前言
Python網路爬蟲實例系列第一篇「 巴哈姆特哈啦區 」裡,我們先跳過留言的爬取,並於延伸練習中的第二題讓大家嘗試。
而在經過了上一篇「 聯合新聞網-動態載入 」,應該大致知道該怎麼處理動態載入的部分。本文再實際帶著大家來爬取"巴哈姆特哈啦區的留言",一樣是採用 Ajax 動態載入,最後也會附上完整程式碼供參考,那我們就開始吧~
備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任
套件
此次 Python 爬蟲主要使用到的套件:
流程
首先進到巴哈姆特哈啦區中任一看板的任一文章,如同Python網路爬蟲實例第一篇「 巴哈姆特哈啦區 」先爬取各個樓層回覆,再進入抓取底下留言的部分。
一樣要觀察其留言列表載入方式,使用瀏覽器的開發人員工具找出 Ajax 請求網址,透過此網址取得新聞列表的 JSON 格式資料。
爬蟲程式
網站有些常見的反爬蟲機制是偵測你送來 requests 的 header 中 User-Agent 欄位,因此我們就需要模仿一般瀏覽器送出去的資料。
先在上方定義 HEADERS 變數,之後需要發出請求就帶入此數值。
| |
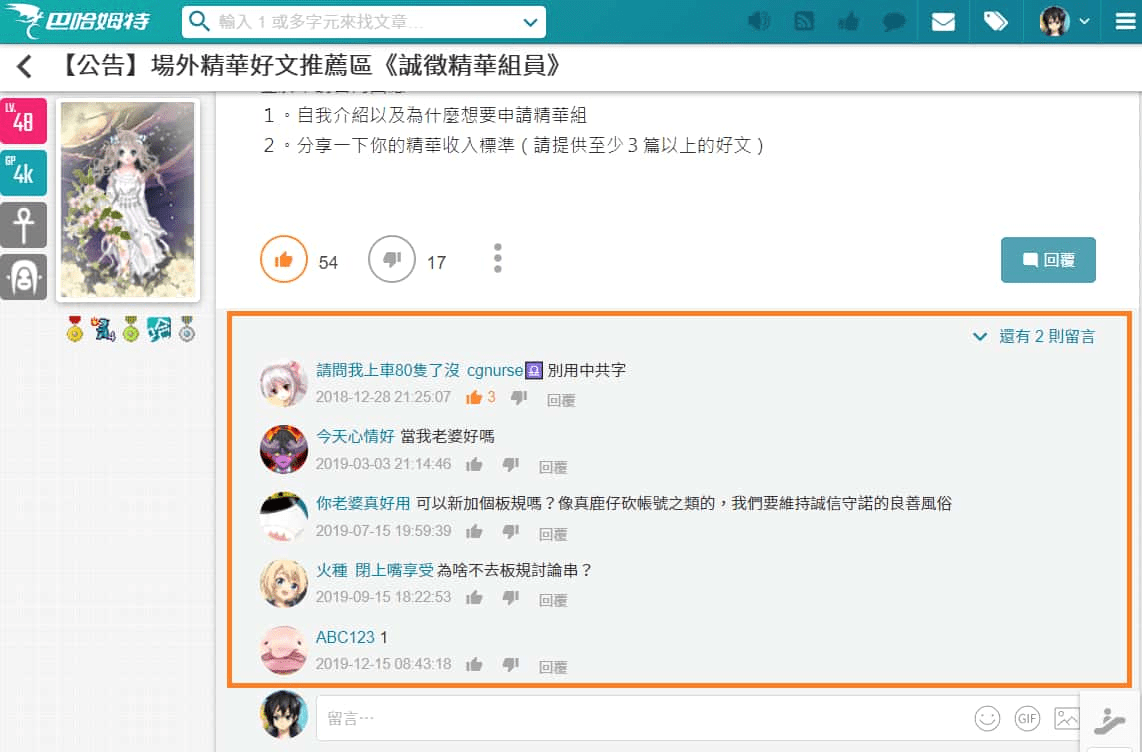
如何載入留言
我們先找一則回覆的留言是需要點擊展開的,例如:
https://forum.gamer.com.tw/C.php?bsn=60076&snA=4549786
,對網頁點滑鼠右鍵 > 檢視網頁原始碼,查看此網頁的原始碼,
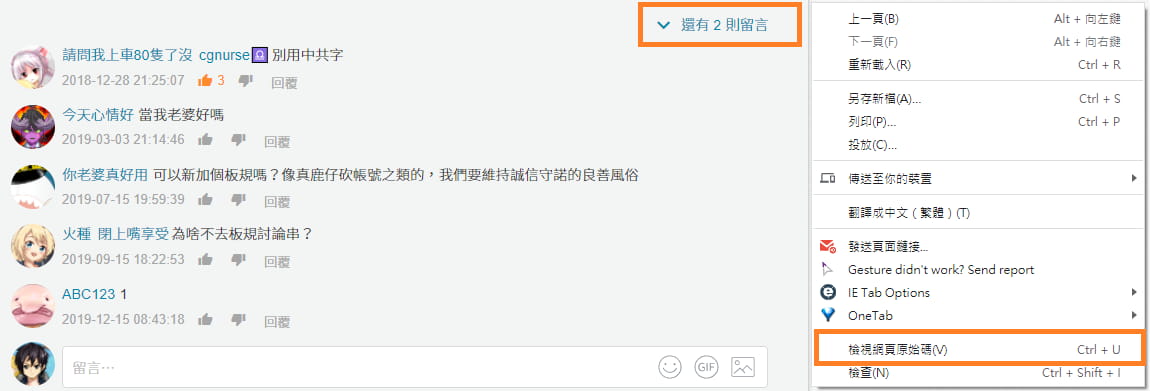
在其中試著搜尋(Ctrl + f)需要展開才能看到的留言,會發現並沒有在網頁原始碼內,因此可以推測留言可能使用動態載入的方式。

打開瀏覽器的 開發人員工具 (F12 或 Ctrl + Shift + i) > Network(網路) 分頁,切換到XHR重整網頁一下(F5),當點擊"還有 2 則留言"後會發現有新的項目出現。
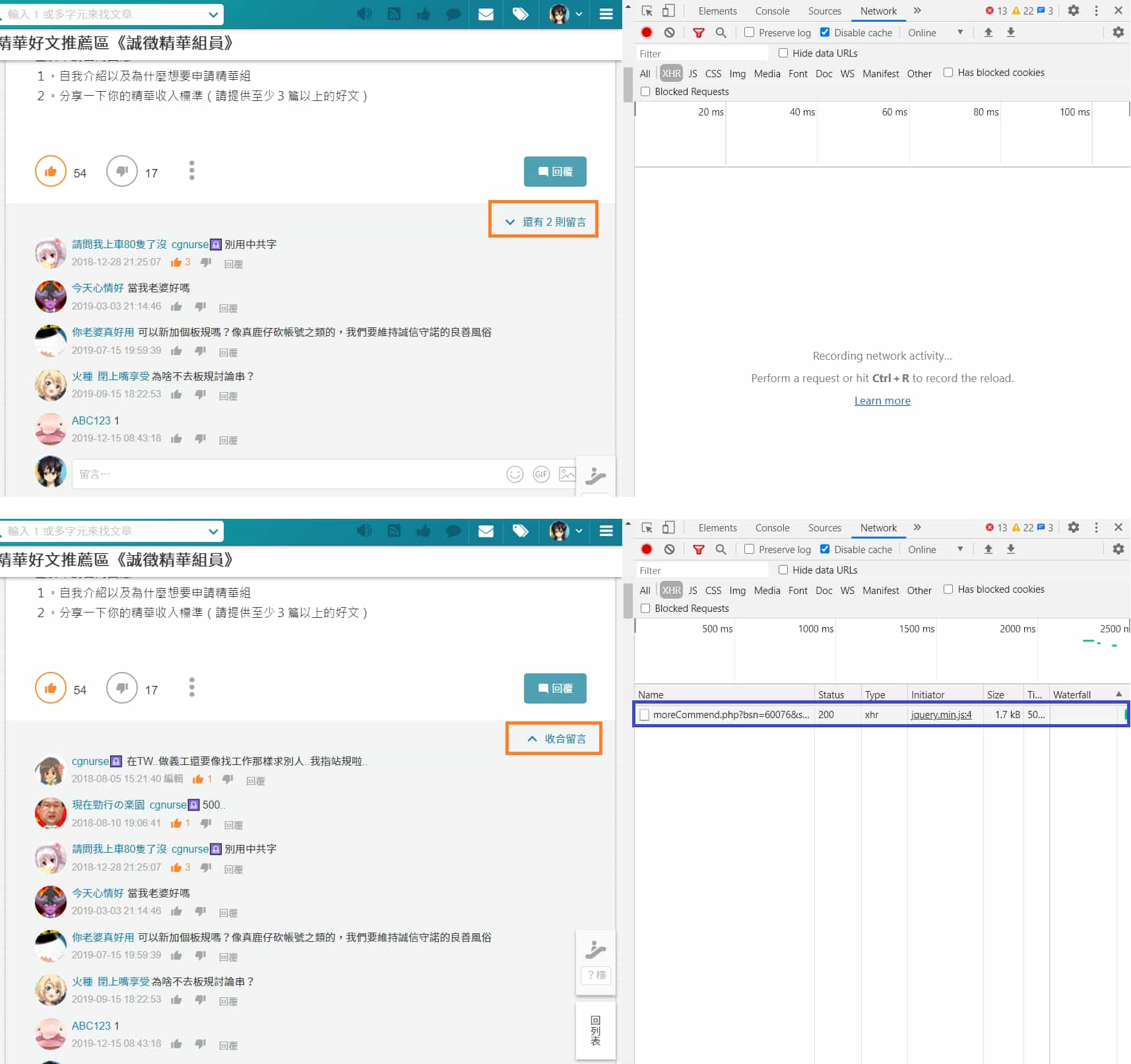
單點選它之後,右邊選擇
Preview 分頁,即可發現這就是我們想要的資料!🤩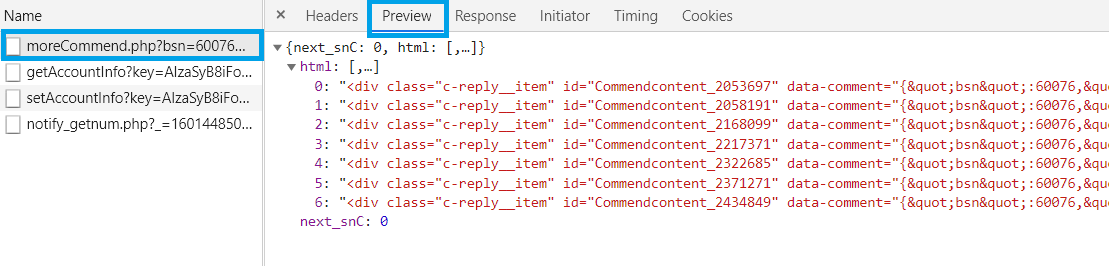
試著載入留言
切換到 Headers 分頁,會顯示請求的網址(綠色框)以及請求方式(紫色框),如此圖片顯示是使用 GET 方式,
https://forum.gamer.com.tw/ajax/moreCommend.php?bsn=60076&snB=50892275&returnHtml=1
將網址複製起來,開個新分頁貼上網址後前往,順利取得回傳的資料(留言)。

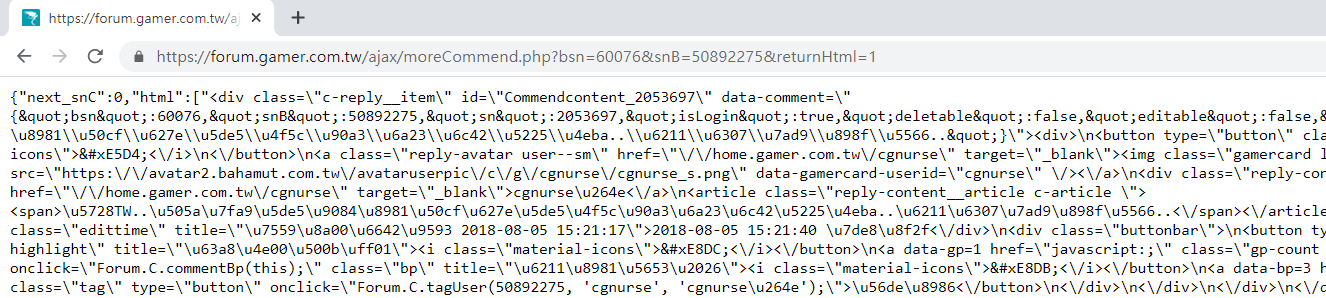
從上方回傳資料發現其留言已經使用 HTML 的格式,為了可以直接丟到網頁上顯示,雖然我們可以抓下來用 BeautifulSoup 解析,但注意觀察請求的網址會發現當中有帶一個參數 returnHtml,如果將其參數的值改為1,或將此參數移除,它回傳的資料就變成我們喜歡的 JSON 格式~ (歡呼)
https://forum.gamer.com.tw/ajax/moreCommend.php?bsn=60076&snB=50892275


不用再耗費力氣去找哪個資料對應哪個Tag、Class之類的麻煩事~
觀察回傳資料
將資料貼到線上 JSON 工具(
JSON Editor Online
)來觀察,發現它除了有一個 next_snC,剩下都是留言資料。

其中比較重要的有以下欄位:
| 參數 | 代表意思 |
|---|---|
| bsn | 板塊ID |
| snB | 回覆ID |
| sn | 留言ID |
| userid | 留言者ID |
| nick | 留言者名稱 |
| comment、content | 留言內容 (目前不知道兩者差異) |
| gp | GP |
| bp | BP |
| wtime | 發布時間 |
| mtime | 編輯時間 |
OK!接下來就要實際動手寫 code 囉~ 😙
爬取每一樓層回覆
* 為了簡化程式碼方便理解,像之前判斷請求是否成功的部份,這次將其省略。
| |
跟之前「
[Python爬蟲實例] 巴哈姆特哈啦區
」一樣,透過 Tag 的 id 爬取每一樓層回覆。
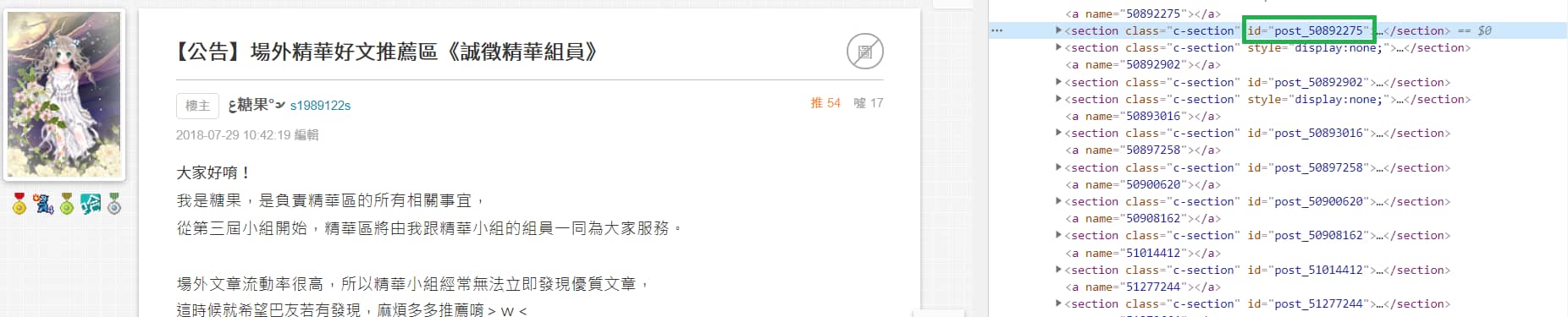
這邊還需要取得"板塊ID",因為爬取留言網址需要。
(這部分可以拉出來寫個 Function,之後需要使用比較方便。)
| |
也需要取得"回覆ID",而其 Tag 的 id 後方接著的數字就是"回覆ID"。
將"板塊ID"與"回覆ID"傳入 get_commend_info_list() 供組合出爬取留言網址使用。
| |
爬取每一則留言
組合出爬取留言用的網址,取得回傳資料,用 requests 提供的 r.json() 解碼轉換成 Dict。

這邊有一點要注意,回傳資料中會有一個叫"next_snC",其他都是字串格式的數字。
數字的裡面放著留言,要排除掉"next_snC"。
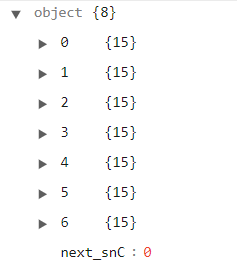
這邊我們弄一個 commends 的列表保存需要的留言資料,最後回傳。
備註:不太確定它一次最多可以回傳幾則留言,如果有人發現超過 1000 則留言的回覆,歡迎底下留言,我再將其補充。
| |
執行結果如下,這邊我顯示第一則留言方便觀察:
| |
完整程式碼
附上完整程式碼:
gamer_commend_spider.py
(對超連結右鍵 > 另存連結為)
延伸練習
回傳的留言資料中,有一筆
"next_snC":0資料,你可以猜測它是代表什麼意思嗎?嘗試結合第一篇「 巴哈姆特哈啦區 」文章,寫出可以爬取"文章"、"回覆"、"留言"的爬蟲程式~
結語
其實沒有想像中的難吧~趕快自己實際動手寫寫看~
之後會繼續加入不同網站的"網路爬蟲實例",如果你正好是剛開始想學爬蟲的新手、想知道某個網站如何爬取資料,又或者遇到其他問題,歡迎參考和在底下留言ㄛ~😙
參考:
巴哈姆特 - 哈啦區
別想一下造出大海,必須先由小河川開始。
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~