前言
本篇主要一步步講解如何使用 Python 爬取巴哈姆特哈啦區的文章及回覆,最後也會附上完整程式碼供參考。
備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任
套件
此次 Python 爬蟲主要使用到的套件有:
流程
先來講一下我們這次寫爬蟲想抓取的資料及流程,在 巴哈姆特哈啦區 中選擇一個看板,想抓取文章列表中的文章及回覆。
一開始要先在文章列表中抓取每一篇文章的網址,再來進入文章網址中抓取每一樓層的回覆。
那因為這是 本系列 第一篇文章,較複雜的部分先省略,在文章列表中只抓第一頁的文章就好,回覆底下的留言是採用動態載入(AJAX)的方式,本次也先跳過,等後續文章再講解。
 爬取說明
爬取說明爬蟲程式
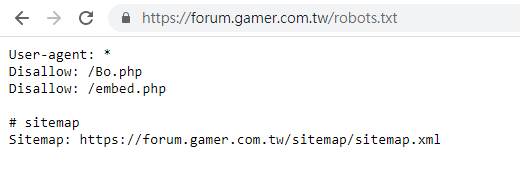
首先查看網站對於爬蟲的規範(
robots.txt
),
https://forum.gamer.com.tw/robots.txt
OK 它只有這兩個路徑不允許,跟我們爬取哈啦區文章沒有關係。
 robots.txt
robots.txt有些有反爬蟲的網站,基本的方式就是偵測你送來 requests 的 header 中 User-Agent 欄位,因此我們就需要模仿一般瀏覽器送出去的資料。
先在上方定義 HEADERS 變數,待之後需要發出請求就帶入此數值。
| HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
}
|
爬取文章列表
對網站伺服器發出請求後,要確認回傳的結果,如果是正常成功的才繼續後續的處理。
| def get_article_url_list(forum_url):
"""爬取文章列表"""
r = requests.get(forum_url, headers=HEADERS)
if r.status_code != requests.codes.ok:
print('網頁載入失敗')
return []
# ......
|
這邊就以
荒野亂鬥板
來示範。
打開瀏覽器的 開發人員工具 (F12 或 Ctrl + Shift + i) > Elements(元素) 分頁,
當你指到程式碼時,它對應網頁區塊就會用顏色顯示,
但這樣找太麻煩費時了,有個好用的功能,就是位在開發人員工具左上角的選擇工具,
點一下它後,就可以直接在網頁上點擊想要查看的區塊,Elements(元素)裡的程式碼也會自動跳到相應的地方。
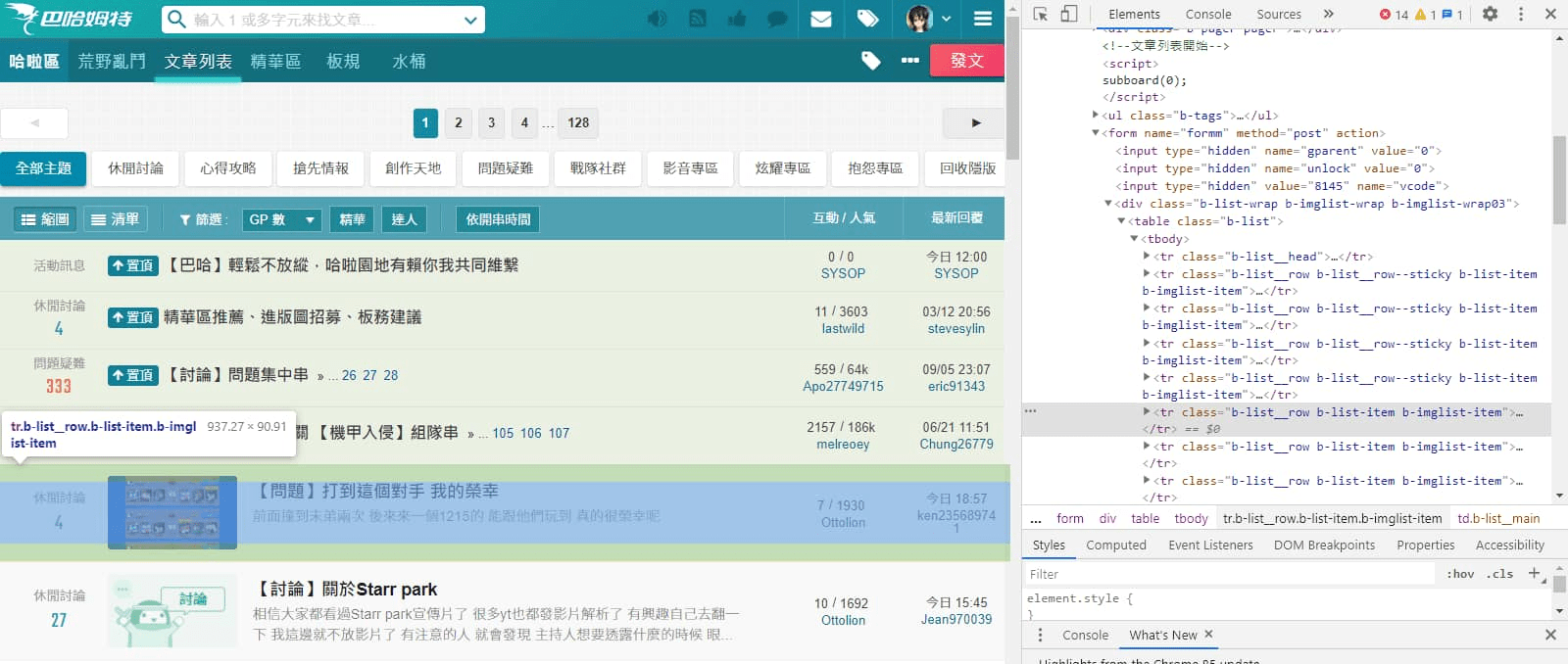
開發人員工具 > 選擇工具先指到文章區塊,在右方可以看到在 <table class="b-list"> 裡的每一個 <tr class="b-list__row b-list-item b-imglist-item"> 對應每一篇文章區塊,因此CSS選擇器可以使用 table.b-list tr.b-list-item 去選擇。
* 這部分還不太懂的人,可以參考我之前整理的文章:
網頁CSS節點定位整理
。
 開發人員工具 > Elements(元素) > 文章區塊
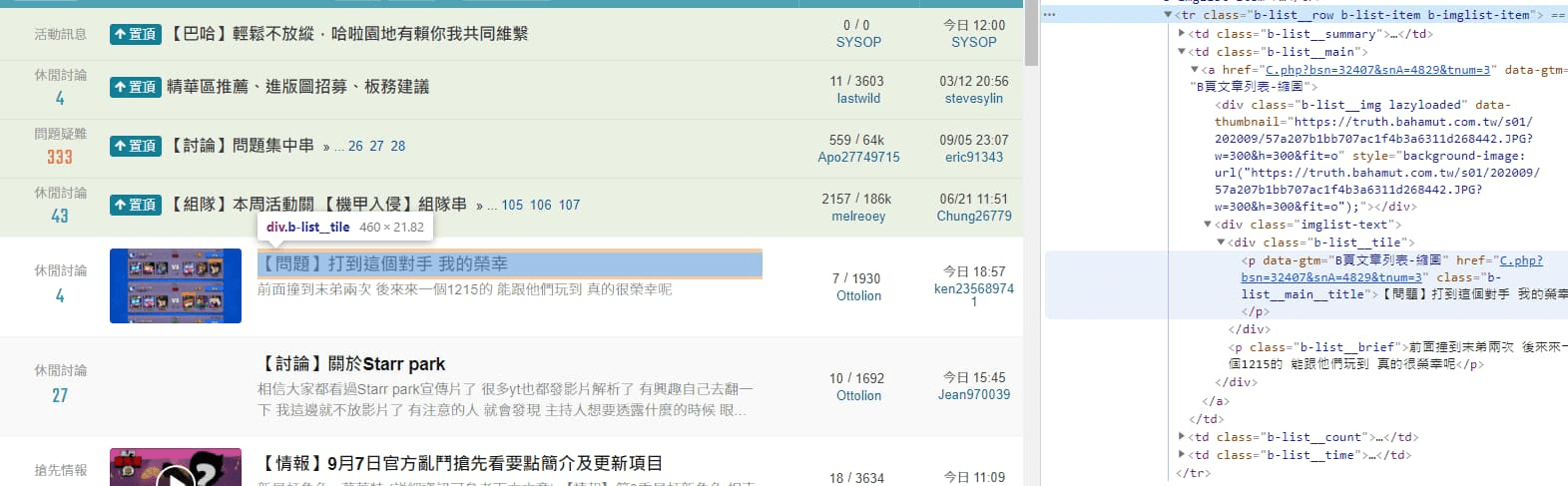
開發人員工具 > Elements(元素) > 文章區塊我們這邊只需要抓取文章的網址,再往下找在 class="b-list__main__title" 元素中的 href 參數後方發現前往文章頁面的網址。
不過取出來時還要要加上網域,才是完整的文章網址。
 開發人員工具 > Elements(元素) > 文章區塊 > 文章網址
開發人員工具 > Elements(元素) > 文章區塊 > 文章網址 1
2
3
4
5
6
7
8
9
10
11
12
13
| def get_article_url_list(forum_url):
"""爬取文章列表"""
# ......
article_url_list = []
soup = BeautifulSoup(r.text, features='lxml')
item_blocks = soup.select('table.b-list tr.b-list-item')
for item_block in item_blocks:
title_block = item_block.select_one('.b-list__main__title')
article_url = f"https://forum.gamer.com.tw/{title_block.get('href')}"
article_url_list.append(article_url)
return article_url_list
|
先來稍微觀察一下文章網址,
https://forum.gamer.com.tw/C.php?bsn=60076&snA=3919777&tnum=429
網址中後方的參數有"bsn"、"snA"、"tnum",其分別代表:
| 參數 | 代表意思 |
|---|
| bsn | 板塊 ID |
| snA | 文章 ID |
| tnum | 文章內目前最新回覆的樓層數 |
| (bPage) | 在文章列表中此文章是出現在第幾頁 |
題外話:"tnum"參數可有可無,能的話最好把它拿掉,這樣網址比較"乾淨"。
爬取文章資訊
此函式會爬取文章標題、網址、樓層回覆,網址剛剛已經知道了,標題也很容易就抓出來。
 文章標題
文章標題 | def get_article_info(article_url):
"""爬取文章資訊(包含回覆)"""
r = requests.get(article_url, headers=HEADERS)
if r.status_code != requests.codes.ok:
print('網頁載入失敗')
return {}
soup = BeautifulSoup(r.text, features='lxml')
article_title = soup.select_one('h1.c-post__header__title').text
# ......
|
這邊的重點就是如何抓取樓層回覆,
我們嘗試點選不同頁數,會發現網址會有個 page 參數用來跳頁,藉由如此,我們就可以前往每一頁。
但,我們要先知道這篇文章總共有幾頁啊!
觀察一下,只要取得 <p class="BH-pagebtnA"> 內最後一個 <a> 元素即可。
文章回覆頁數 | def get_article_total_page(soup):
"""取得文章總頁數"""
article_total_page = soup.select_one('.BH-pagebtnA > a:last-of-type').text
return int(article_total_page)
|
知道總頁數後,就可以使用 for 迴圈來歷遍每一頁。
組出網址字串,接著就是抓取每一層回覆(等等會講),並合併成 Dict 格式回傳。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def get_article_info(article_url):
"""爬取文章資訊(包含回覆)"""
# ......
article_total_page = get_article_total_page(soup)
reply_info_list = []
for page in range(article_total_page):
crawler_url = f"{article_url}&page={page + 1}"
reply_list = get_reply_info_list(crawler_url)
reply_info_list.extend(reply_list)
time.sleep(1)
article_info = {
'title': article_title,
'url': article_url,
'reply': reply_info_list
}
return article_info
|
* for 迴圈中加入時間延遲 time.sleep(1) ,避免太頻繁的爬取,造成對方伺服器的負擔。1秒可以換成 random.uniform(1, 3),來達到一段隨機範圍延遲,更避免被伺服器偵測為爬蟲。
爬取回覆資訊
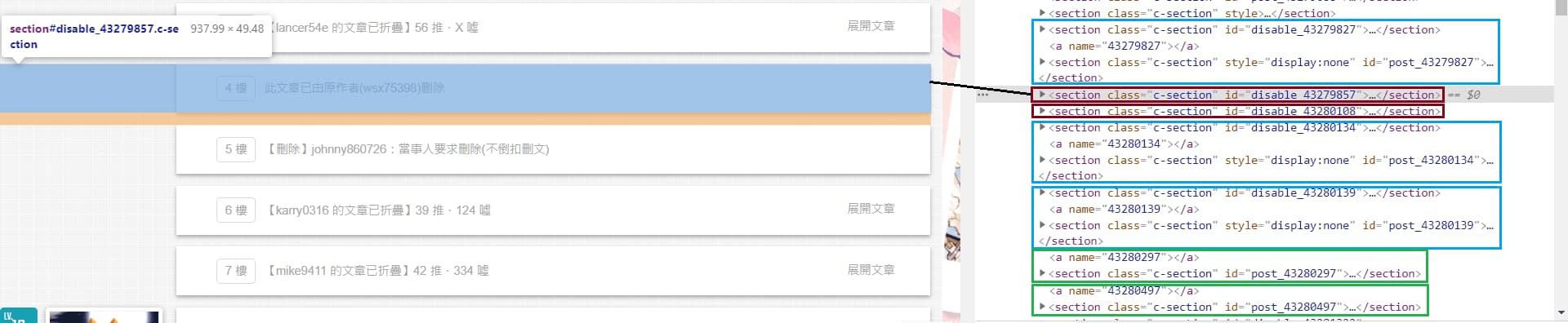
爬取回覆的部分,從下圖的綠色方框能得知每一層回覆都是位於 <section class="c-section" id="post_43280297"> 裡。
但有些比較特殊的樓層,像是下圖中"已刪除"或"已摺疊"的樓層,可以看到其 id 會是 disable_ 開頭,"已刪除"的樓層我們可以略過,但"已摺疊"的樓層該怎麼抓呢?
別擔心,在往下看可以發現一樣有被摺疊起來樓層的資料,只是它被隱藏起來而已(style="display:none")
如下圖指示,綠色代表一般正常樓層;藍色代表已折疊樓層;深紅色代表已刪除樓層。
已刪除&已摺疊的樓層 1
2
3
4
5
6
7
8
9
10
11
12
| def get_reply_info_list(url):
"""爬取回覆列表"""
# ......
reply_info_list = []
soup = BeautifulSoup(r.text, features='lxml')
reply_blocks = soup.select('section[id^="post_"]')
for reply_block in reply_blocks:
# ......
return reply_info_list
|
接下來就是各別抓取需要的部分了,
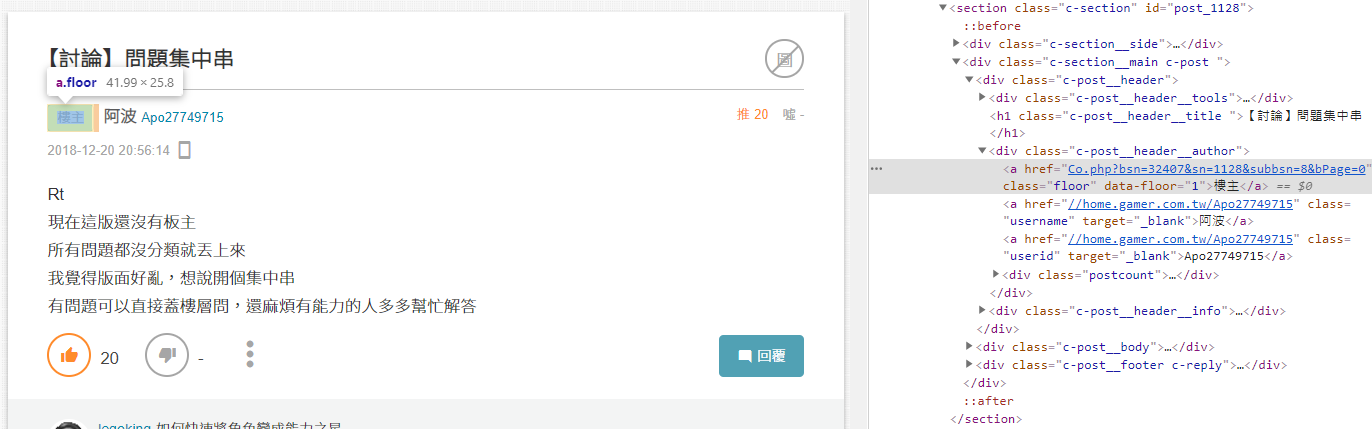
例如"回覆樓層"雖然網頁上只顯示樓主,看不到樓層的數字,但從網頁原始碼中能發現,此元素中 data-floor 欄位裡有我們想要的樓層數字。
回覆 樓層欄位又或者想抓取"發文時間",但如果有編輯過的回覆,它網頁上顯示著是"編輯時間",這時從網頁原始碼中也能發現,元素裏頭有 data-mtime 欄位記錄著發文時間。
但抓下來的資料是文字格式(字串)的,最好轉成 datetime 格式方便後續的判斷、處理。
回覆 發文時間欄位而"推"、"噓"也要注意例外,當"推"超過 1000 時會顯示"爆";當"噓"超過 500 時會顯示"X"、等於 0 會顯示"-"。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| def get_reply_info_list(url):
"""爬取回覆列表"""
# ......
for reply_block in reply_blocks:
reply_info = {}
reply_info['floor'] = int(reply_block.select_one('.floor').get('data-floor'))
reply_info['user_name'] = reply_block.select_one('.username').text
reply_info['user_id'] = reply_block.select_one('.userid').text
publish_time = reply_block.select_one('.edittime').get('data-mtime')
reply_info['publish_time'] = datetime.strptime(publish_time, '%Y-%m-%d %H:%M:%S')
reply_info['content'] = reply_block.select_one('.c-article__content').text
gp_count = reply_block.select_one('.postgp span').text
if gp_count == '-':
gp_count = 0
elif gp_count == '爆':
gp_count = 1000
reply_info['gp_count'] = int(gp_count)
bp_count = reply_block.select_one('.postbp span').text
if bp_count == '-':
bp_count = 0
elif bp_count == 'X':
bp_count = 500
reply_info['bp_count'] = int(bp_count)
# 從命名應該可以知道分別代表什麼資料,這邊我就不細說了
reply_info_list.append(reply_info)
return reply_info_list
|
完整程式碼
附上完整程式碼:
gamer_spider.py
(對超連結右鍵 > 另存連結為)
延伸練習
在本篇教學中只爬取第一頁的文章,該如何自動爬取前五頁的文章呢?
提示:參考爬取每一頁回覆的方式
為了簡單,本篇教學中並沒有爬取樓層回覆底下的留言,這部分有沒有什麼辦法可以做到?
 樓層回覆底下的留言
樓層回覆底下的留言
結語
有些機制這邊沒有寫出來,像是當網頁請求失敗該做什麼處理,將字串轉換為日期時間格式時(或將字串轉換為整數)時,需要加上 try-except 去捕抓錯誤等等。
之後我會慢慢陸續寫一些網站的"網路爬蟲實例",如果你正好是剛開始想學爬蟲的新手,或者是不知道某個網站如何爬取資料,都很歡迎過來參考ㄛ~
有想推薦的網站,或遇到其他問題,也歡迎再底下留言。😙
參考:
網頁CSS節點定位整理
又不是所有的答案都必須完美,失敗和錯誤也是生命的養分。
—— Peter Su
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~