(2021/10/03 新增) 瀏覽器使用 CSS Selectors 搜尋教學。
最近開始接觸網路爬蟲,因此順便把一些常用網頁取得元素(element)的 CSS Selectors 方式整理一下,第一部分是純 CSS,第二部分則是 Python 搭配 BeautifulSoup 套件。
喜歡網路爬蟲也歡迎觀看 Python網路爬蟲實例 系列文章~
純CSS
先上表格,後面還有範例。
| 說明 | 語法 |
|---|
| tag 定位 | span font |
| id 定位 | #ID |
| class 定位 | .CLASS |
| 排除 | :not() |
| 屬性值 | [name="NAME"] |
| 屬性值(不等於) | [name!="NAME"] |
| 屬性值包含 | [title*="TITLE"] |
| 屬性值開頭 | [title^="start"] |
| 屬性值結尾 | [title$="end"] |
| 第 1 個子元素 (全部) | ul li:first-child |
| 最後 1 個子元素 (全部) | ul li:last-child |
| 第 2 個子元素 (全部) | ul li:nth-child(2) |
| 倒數第 2 個子元素 (全部) | ul li:nth-last-child(2) |
| 第 1 個子元素 (指定) | ul li:first-of-type |
| 最後 1 個子元素 (指定) | ul li:last-of-type |
| 第 2 個子元素 (指定) | ul li:nth-of-type(2) |
| 倒數第 2 個子元素 (指定) | ul li:nth-last-of-type(2) |
| 第奇數個子元素 (指定) | ul li:nth-of-type(odd) |
| 第偶數個子元素 (指定) | ul li:nth-of-type(even) |
| 第 3 的倍數個子元素 (指定) | ul li:nth-of-type(3n) |
| 第 3 的倍數+1個子元素 (指定) | ul li:nth-of-type(3n+1) |
| 同一層往後尋找元素 | #ID ~ i |
| 同一層的"下一個"元素 | #ID + * |
| 同時尋找多種選擇器 | #id1 , #id2 |
| import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
|
標籤定位(tag、id、class)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <html>
<span>
<div><font>001</font></div>
<font>002</font>
</span>
<div id="ID">003</div>
<div class="CLASS CLASS2">004</div>
<i name="NAME" style="STYLE">005</i>
<i name="NAME2" style="STYLE">006</i>
<div title="TITLE">007</div>
<div title="start-TITLE">008</div>
<div title="TITLE-end">009</div>
</html>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # tag定位:
soup.select_one('span font')
# <font>001</font>
soup.select_one('span > font')
# <font>002</font>
# id定位:
soup.select_one('#ID')
soup.select_one('div#ID')
# <div id="ID">003</div>
# class定位:
soup.select_one('.CLASS')
soup.select_one('div.CLASS')
soup.select_one('div.CLASS.CLASS2')
# <div class="CLASS CLASS2">004</div>
# 同時尋找多種選擇器
soup.select('#ID , .CLASS')
# [<div id="ID">003</div>, <div class="CLASS CLASS2">004</div>]
# 排除
soup.select('div:not(#ID):not(.CLASS)')
# [<div><font>001</font></div>, <div title="TITLE">007</div>, <div title="start-TITLE">008</div>, <div title="TITLE-end">009</div>]
|
元素屬性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # 元素有某屬性:
soup.select_one('i[name]')
# <i name="NAME" style="STYLE">005</i>
# 屬性值:
soup.select_one('i[name="NAME"]')
soup.select_one('i[name="NAME"][style="STYLE"]')
# <i name="NAME" style="STYLE">005</i>
# 屬性值不等於:
soup.select_one('i[name!="NAME"]')
# <i name="NAME2" style="STYLE">006</i>
# 屬性值包含某字串:
soup.select_one('div[title*="TITLE"]')
# <div title="TITLE">007</div>
# 屬性值以某字串開頭:
soup.select_one('div[title^="start"]')
# <div title="start-TITLE">008</div>
# 屬性值以某字串結尾:
soup.select_one('div[title$="end"]')
# <div title="TITLE-end">009</div>
|
子元素
1
2
3
4
5
6
7
8
9
10
11
12
| <html>
<div id="list">
<p>101</p>
<p>102</p>
<span>201</span>
<span>202</span>
<span>203</span>
<p>103</p>
<span>204</span>
<p>104</p>
</div>
</html>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| # -child
# 第1個、最後1個 子元素:
soup.select_one('ul#list li:first-child')
soup.select_one('ul#list li:last-child')
# <li>1001</li>
# <li>1004</li>
# 第2個、倒數第2個 子元素:
soup.select_one('ul#list li:nth-child(2)')
soup.select_one('ul#list li:nth-last-child(2)')
# <p>102</p>
# None
# 注意:倒數第2個元素不是"p",因此找不到
# -of-type
# 第1個、最後1個 子元素:
soup.select_one('#list p:first-of-type')
soup.select_one('#list p:last-of-type')
# <p>101</p>
# <p>104</p>
# 第2個、倒數第2個 子元素:
soup.select_one('#list p:nth-of-type(2)')
soup.select_one('#list p:nth-last-of-type(2)')
# <p>102</p>
# <p>103</p>
# 以上兩種很像,他們的差別是:
# nth-child 會把全部的元素加進去算;nth-of-type 只會針對你指定的元素去算。
# 偶數、奇數 位置元素
soup.select('#list p:nth-of-type(odd)')
soup.select('#list p:nth-of-type(even)')
# [<p>101</p>, <p>103</p>]
# [<p>102</p>, <p>104</p>]
|
同一層元素
| <html>
<div id="ID">301</div>
<div class="CLASS CLASS2">302</div>
<i name="NAME" style="STYLE">303</i>
<i name="NAME2" style="STYLE">304</i>
</html>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 在同一層往後尋找元素
soup.select_one('#ID ~ i')
# <i name="NAME" style="STYLE">303</i>
# 在同一層的"下一個"元素
soup.select_one('#ID + *')
# <div class="CLASS CLASS2">302</div>
# 在同一層,往後尋找"下一個"元素
soup.select_one('#ID + div')
# <div class="CLASS CLASS2">302</div>
# 在同一層,往後尋找中間跳過一個元素的"下一個"元素
soup.select_one('#ID + * + i')
# <i name="NAME" style="STYLE">303</i>
|
搭配 BeautifulSoup 套件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <div>
<span>標題</span>
<span>副標題</span>
<span>第二副標題</span>
<div class="a" title="first" href="/link">這是一行句子</div>
<a href="/link1">這是超連結1</div>
<a href="/link2">這是超連結2</div>
<div data-target="value">data屬性</div>
<div class="CLASS CLASS2">多個class</div>
</div>
|
尋找標籤
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 返回符合的單個元素(如有多個符合,則回傳第一個),當找不到則回傳None:
soup.select_one('span')
soup.find('span')
# <span>標題</span>
# 返回符合的全部元素(List),當找不到則回傳空List:
soup.select('span')
soup.find_all('span')
# [<span>標題</span>, <span>副標題</span>, <span>第二副標題</span>]
# 限制尋找元素數量:
soup.select("span", limit=2)
# [<span>標題</span>, <span>副標題</span>]
|
取得元素文字、值
1
2
3
4
5
6
7
8
9
10
11
12
| # 取得元素的文字:
soup.select_one('div.a').text
# 這是一行句子
# 如果需要更多擷取方式,可使用get_text()
# 取得元素屬性的值:
soup.select_one('div.a').get('title')
# first
soup.select_one('div.a').get('class')
# ['a']
soup.select_one('div.a').get('href')
# /link
|
元素屬性、文字
有些較複雜的也可以改用 find 或 find_all 來尋找。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # 基本的
soup.find_all(title="first")
# [<div class="a" href="/link" title="first">這是一行句子</div>]
# 因為 class 在 Python 中是保留字,所以尋找class時改使用 class_:
soup.find_all(class_="CLASS")
# [<div class="CLASS CLASS2">多個class</div>]
# 當想比對全部class(注意順序)
soup.find_all(class_="CLASS CLASS2")
# [<div class="CLASS CLASS2">多個class</div>]
# 某些HTML的屬性直接寫的話,會發生錯誤(例如 data-* 這類的屬性),
# 改使用另一種方式即可:
soup.find_all(attrs={"data-target": "value"})
# [<div data-target="value">data屬性</div>]
# 以正規表示式比對超連結網址:
soup.find_all(href=re.compile("^/link\d"))
# [<a href="/link1">這是超連結1</a>, <a href="/link2">這是超連結2</a>]
# 以文字內容尋找(也可搭配正規表示式)
soup.find_all("div", string="這是一行句子")
soup.find_all("div", string=re.compile("句子"))
# [<div class="a" href="/link" title="first">這是一行句子</div>]
|
父元素、同一層元素
前面說的是以其元素往下尋找子元素,那如果要找父元素或同一層元素,使用以下方式:
| <div id="div2">
<div id="div1">
<p id="a">第一點</p>
<p id="b">第二點</p>
<p id="my">第三點</p>
<p id="c">第四點</p>
<p id="d">第五點</p>
</div>
</div>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 先以 <p id="my">第三點</p> 元素為基準
my_tag = soup.find(id="my")
# 函式名稱多加s,代表尋找多個
# 向上尋找父元素
my_tag.find_parent("div")
my_tag.find_parents("div")
# 在同一層往前尋找元素
my_tag.find_previous_sibling("p")
# <p id="b">第二點</p>
my_tag.find_previous_siblings("p")
# [<p id="b">第二點</p>, <p id="a">第一點</p>]
# 在同一層往後尋找元素
my_tag.find_next_sibling("p")
# <p id="c">第四點</p>
my_tag.find_next_siblings("p")
# [<p id="c">第四點</p>, <p id="d">第五點</p>]
|
其他
其他在擷取網頁可能還需要的功能:
| # 去除某個元素
node = soup.select_one("#my").extract()
# 去除多個元素
# 注意:前面已經將 #my 移除了
node = [t.extract() for t in soup.select("p")]
|
瀏覽器使用 CSS Selectors 搜尋
你知道在撰寫網路爬蟲程式時,可以有什麼方式快速找到元素的標籤嗎?
瀏覽器的 開發人員工具 有許多方便的功能讓我們使用~
Q. 如何開啟瀏覽器的 開發人員工具 呢?
A. 有以下三種方式:
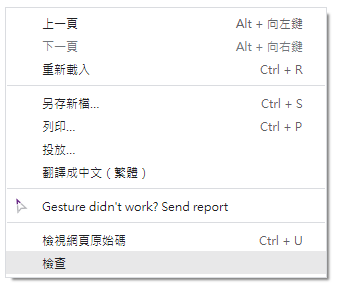
- 網頁空白處點擊滑鼠右鍵 > 檢查。
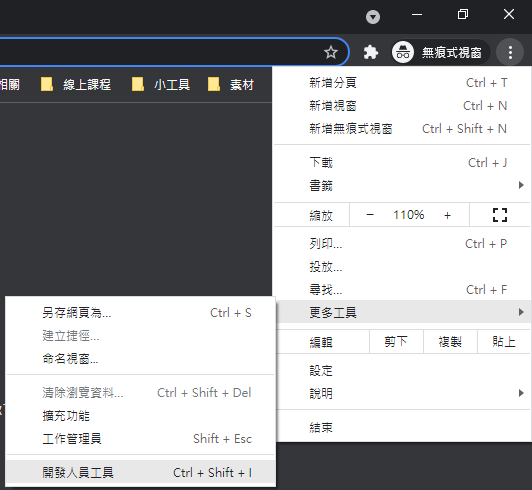
- 瀏覽器(Chrome)右上選單 > 更多工具 > 開發人員工具。
- 快捷鍵 F12。
 第一種開啟方式
第一種開啟方式 第二種開啟方式
第二種開啟方式
Q. 那如何快速找到元素的標籤?
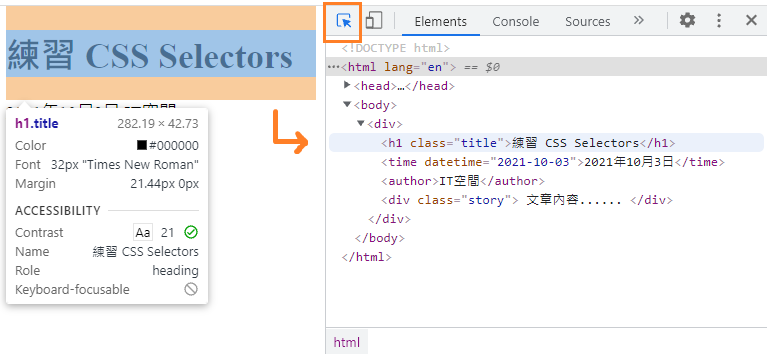
A. 切換到 Elements 分頁,點擊左上角箭頭,並滑鼠指到(或點選)網頁上的元素。
如此開發人員工具內會跳到此元素的位置,並標註出來。
 找到元素的標籤
找到元素的標籤
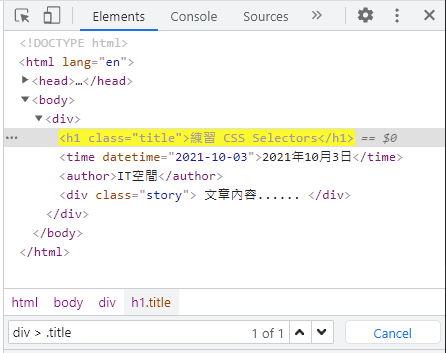
Q. 如何使用 CSS Selectors 或 XPath 搜尋元素?
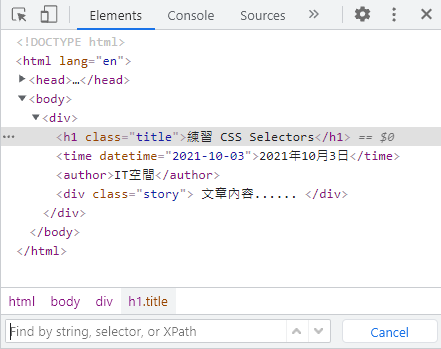
A. 在 Elements 分頁,快捷鍵 Ctrl + F,會跳出下方搜尋欄,可以透過 "文字"、"CSS Selectors"、"XPath" 搜尋元素。
 Elements 下方搜尋欄使用 CSS Selectors 或 XPath 搜尋元素
Elements 下方搜尋欄使用 CSS Selectors 或 XPath 搜尋元素
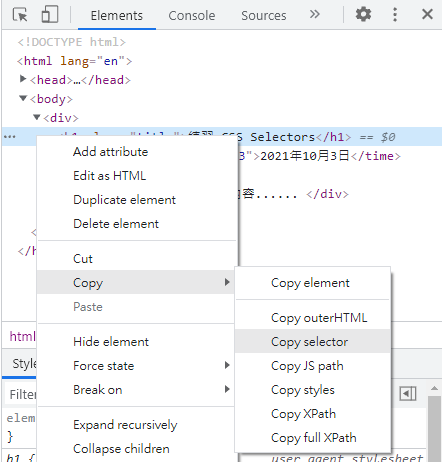
Q. 有辦法自動產生元素的 "CSS Selectors"、"XPath" 嗎?
A. 是可以,但不那麼建議,因為網頁有時會更新、變動,建議自己找出較好的 Selector 寫法。
對元素點擊滑鼠右鍵 > Copy > Copy selector。
複製元素的 CSS Selector 或 XPath
如有發現任何錯誤,歡迎底下留言告知~
參考:
Python selenium —— XPath and CSS cheat sheet
Python 使用 Beautiful Soup 抓取與解析網頁資料,開發網路爬蟲教學
不用很厲害才開始,要先開始才會很厲害。
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~