前言
這次文章比較面向網路爬蟲初學者,以爬取" 巴哈姆特 動畫瘋 "的本季新番動畫資訊示範,從如何使用開發人員工具尋找網頁元素,到如何轉為可實際運作的程式碼,從頭到尾的流程。

備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任。
套件
此次 Python 網路爬蟲主要使用到的套件:
教學
先說明本篇網路爬蟲目標,只針對較容易爬取的欄位來教學,分別是"動畫名稱"、"觀看人數"、"動畫集數"、"觀看連結"等資料,以下瀏覽器以 Chrome 版本 96.0.4664.45 示範。
來到 " 巴哈姆特 動畫瘋 " 網頁後打開"開發人員工具" (F12 或 Ctrl + Shift + i)。
網頁元素架構
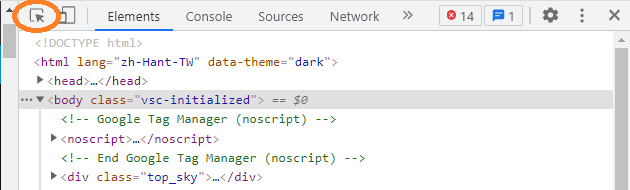
想要知道網頁上的資料在哪個元素中,有個好用的選擇工具,位於開發人員工具地左上角。
點它一下後,可以直接在網頁上點擊想要查看的區塊,Elements(元素)視窗裡的程式碼會自動跳到相應的地方。
但在找元素的定位之前,我們先來觀察元素的架構,這也會影響到後續程式碼的流程。
搭配以上說的"選擇工具"(Ctrl + Shift + C),可以看出這部分的架構如下圖:
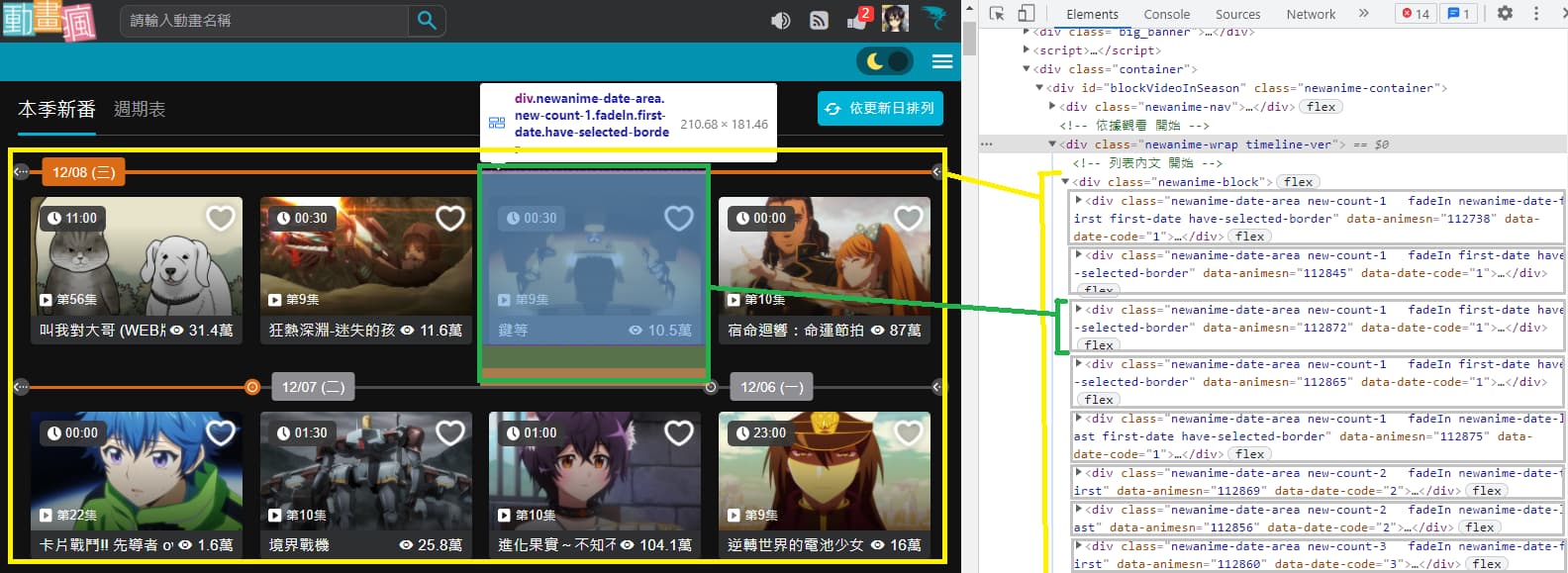
外圈會有一個 <div class="newanime-block"> 開頭,一直到下面以 </div> 結尾 (因為太長,所以圖片沒有擷取到結尾),圖片中我以黃色方框表示。
而裡面每一部動畫的元素我以綠色方框表示,一個黃色框底下包含許多綠色框(動畫資訊),在右邊開發人員工具中我以灰色框所圈起來的,每一個都對應著左邊網頁中一部動畫資訊。
發出請求
好,來寫網路爬蟲程式吧~💪
從請求網頁開始。
首先引入 requests 套件,來對"巴哈姆特 動畫瘋"網址(https://ani.gamer.com.tw/)發出 GET 請求,再從它回傳的狀態碼(HTTP Status Code)來判斷請求是否成功。
* 我們網路爬蟲最常使用的 HTTP 請求方法為 "GET" 和 "POST",兩者介紹與差異可以參考別人撰寫的文章: http Post 和 Get 差異 | Medium
| |
執行後……ㄟㄟ?!
為什麼請求失敗,回傳的狀態碼是"503",不過使用瀏覽器網頁卻是正常顯示的。
(各個狀態所代表的意思:
HTTP狀態碼 | 維基百科
)
很有可能是我們送出的請求中缺少某些要素(資料),以至於動畫瘋的伺服器不回傳資料給我們,
最一開始,可以先加上 Headers 內的 "User-Agent" 試試:
| |
果然,這樣再執行程式碼就請求成功了~
你可能會想問「User-Agent」是什麼? 從哪來的?
「User-Agent」(使用者代理)簡單來說是要"自我介紹",說明自己是誰、版本號多少、使用什麼作業系統這類資訊。
例如我這邊是使用 Chrome 瀏覽器、版本為 96.0.4664.45、作業系統為 Windows 10 64 位元。如果你是使用 Android 或 iOS 系統的手機,那它送出去的 User-Agent 也會有所不同。
「User-Agent」算是一個讓伺服器最簡易判斷送出請求的人是誰,是電腦瀏覽器?是手機瀏覽器?還是Google爬蟲?
不過就像我們上面程式操作的,它也很容易自己去更改。
* 要怎麼辨別使用者瀏覽者用哪種瀏覽器呢?用UserAgent是最簡單的方式喔!
那該如何取得請求的「User-Agent」?
在開發人員工具視窗裡切換到 "Network" 分頁,篩選確認是在 "All",重整網頁(F5),這樣它才會抓到我們送出的請求。
然後會在下方列表的最上面看到 "ani.gamer.com.tw" 的請求。
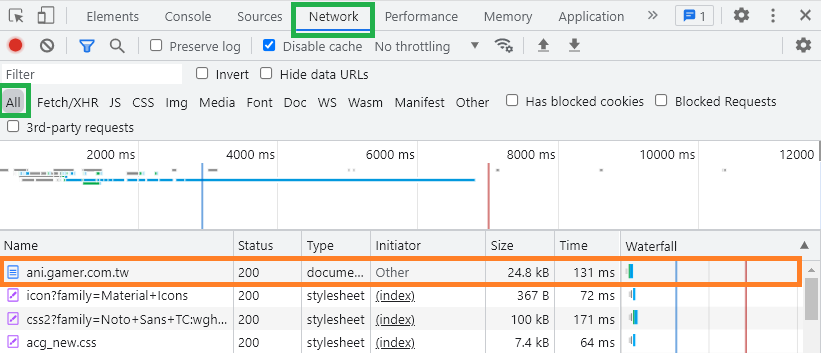
點擊 "ani.gamer.com.tw" 請求後,在右邊出現的視窗中切到 "Headers" 分頁 (正常來說預設就是"Headers"分頁)。
找到在 Request Headers 底下的 "user-agent" 欄位,這個數值就是你瀏覽器發出請求時,所包含的 User-Agent。
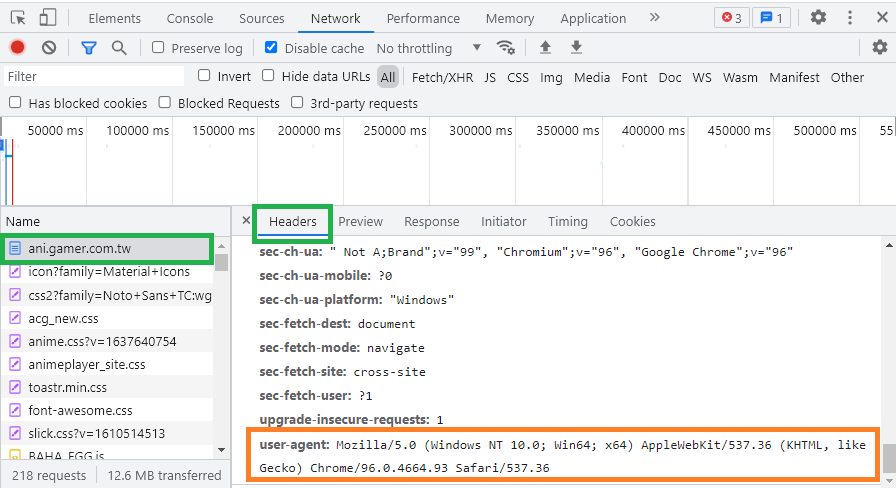
* 此圖片是後來截圖的,所以瀏覽器版本號有些不同。
解析網頁元素
我們在請求成功後,將網頁原始碼顯示出來看看:
| |
接下來要從網頁原始碼解析出我們要的資料,雖然你可以直接從網頁原始碼"字串"切出想要的資料,但光想就知道很麻煩。
網頁原始碼 HTML 是有一定的規則,依循此規則架構可以容易地取出資料。我們將藉助 BeautifulSoup 套件,解析 HTML 文件,方便我們提取資料。
一樣要先將套件引入:
| |
* BeautifulSoup 基礎常用說明參考: Python 使用 Beautiful Soup 抓取與解析網頁資料,開發網路爬蟲教學
將剛剛取得的網頁原始碼傳入,並選擇使用內建的 html.parser 解析器:
| |
要抓取元素,需要給程式依據,讓它可以正確定位到你想抓取哪個元素。
那照上面的 "網頁元素架構" 圖片所示,動畫資料的元素都被包在 <div class="newanime-block"> 之中,是不是只要抓 class 等於 newanime-block 就完事了呢?
可惜這樣會有個小問題,在此網頁中 class 等於 newanime-block 的元素有兩個啊 😕
怎麼知道的?!
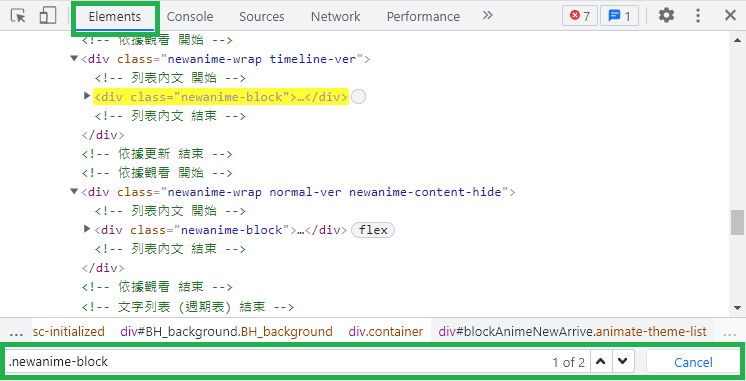
在 "開發人員工具" 的 "Elements" 分頁中開啟搜尋框(鍵盤 Ctrl + F),並輸入 .newanime-block (注意前面有小數點)。.newanime-block 等於告訴它我要尋找 class 等於 newanime-block 的元素,可以看見它找到兩個符合此條件的元素。
* 你可能還不清楚如何寫 CSS Selector (選擇器),之前我整理一篇常用的幾種寫法,可以搭配練習:
常用網頁 CSS Selector (選擇器)取得元素,搭配 Python BeautifulSoup 套件
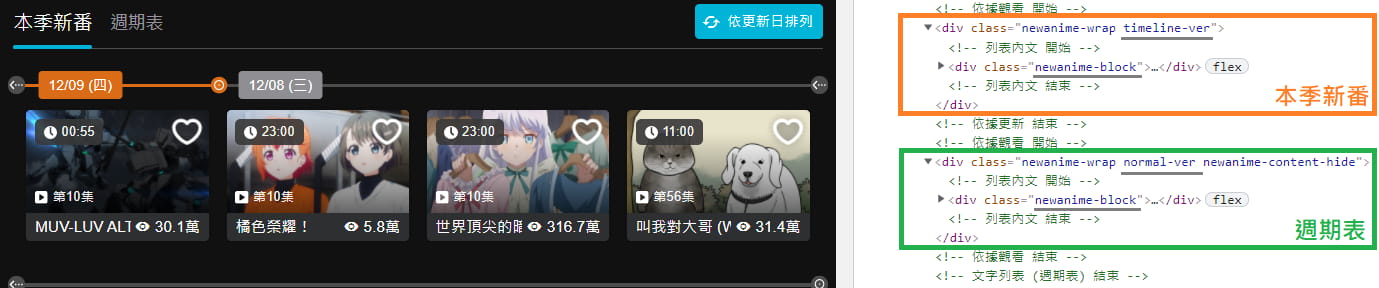
原來這兩個分別是代表 "本季新番" 和 "週期表" 的動畫。
從 <div class="newanime-block"> 再往上看一層,會發覺兩者有不同之處(用來定位元素),一個 class 有 timeline-ver,另一個是 normal-ver,因此我們可以改用 .timeline-ver > .newanime-block 來更準確定位,也就是跟程式說 "我要抓取 class 有包含 timeline-ver 元素底下一層 class 有包含 newanime-block 的元素"。
* class 不一定要全部都寫,主要找出它代表性的、盡量不要跟別的元素重複的 class 即可。
程式中以這樣撰寫:
| |
再往下一層可抓到每一個動畫資料元素,我就以 newanime-date-area 這個 class 來定位。
每個綠框代表一組動畫的元素。
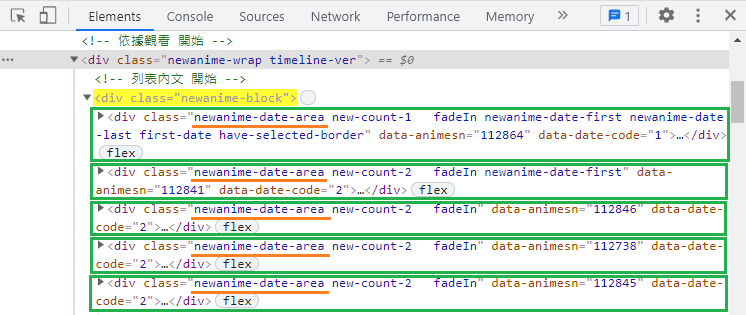
這邊程式碼有一些些不同,剛剛是只要抓一個元素,所以使用 select_one(),但這邊是要抓全部的動畫元素,有很多個就必須使用 select(),它會以"陣列"的形式回傳:
| |
到目前為止,程式部分如下。
為了察看結果,我先暫時用 len() 來看共抓到幾組動畫元素。
| |
終於要進入抓取 "動畫名稱"、"觀看人數"、"動畫集數"、"觀看連結" 的時候了🎉
一樣使用"選擇工具"(Ctrl + Shift + C)輔助,觀察動畫資料元素的架構:
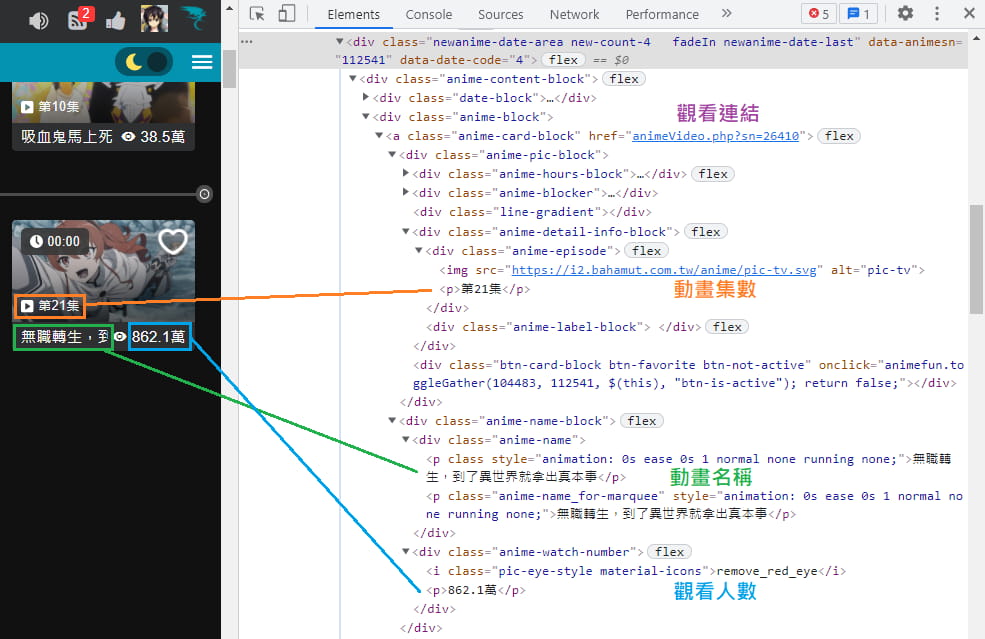
一樣像前面說明,先透過 CSS Selector (選擇器)抓到元素,再來可以使用 text 提取文字,最後的 strip() 只是將字串的前後空格和換行去除。
| |
而 "觀看連結" 稍微特別一點,連結並不是以文字形式被包在元素之間,而是在元素裡的 href 屬性,這時要透過 get('href') 方法來取得。
而且只有網址的後半段,所以我們要再補上前半部才完整。

| |
到這部分的程式碼如下:
| |
好耶~ 快來執行看看~
怎麼發生錯誤了... OAQ...
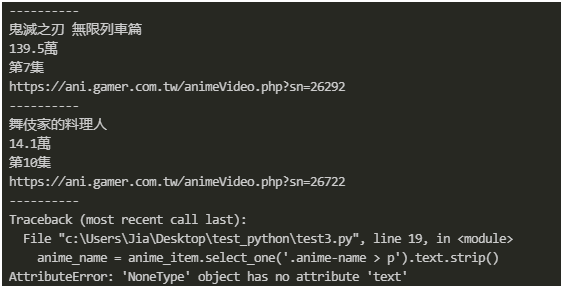
檢查後發現,原來是最後這個"付費比例"區塊搞的鬼,它也同樣有 newanime-date-area 這個 class,一樣會被抓出來,但它沒有動畫名稱,所以才會造成後續在取得文字時發生錯誤。
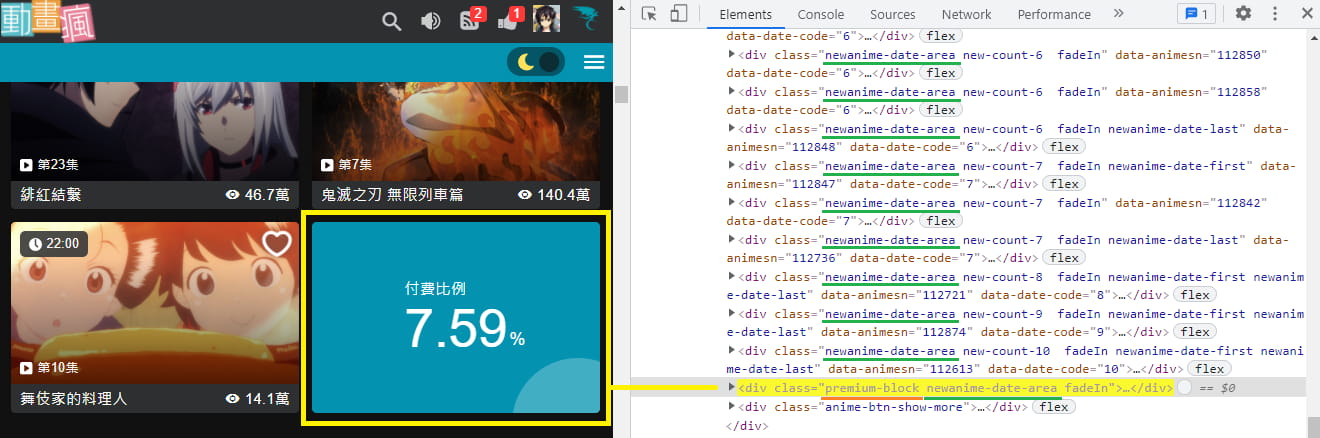
沒關係,可以看見它有個獨特的 class premium-block,我們程式只要使用 :not() 將其排除即可。
| |
好了,花費九牛二虎之力(?)
網頁中"動畫名稱"、"觀看人數"、"動畫集數"、"觀看連結"的資料都如期取得啦~👍

最終程式碼如下:
| |
對了,動畫還有"日期"與"時間"資料,"時間"資料不難取得,和上方教學的方式一樣,不過"日期"在這邊就稍微麻煩點了,本篇文章屬於基礎教學,就先跳過它,但我會附在"完整程式碼"中。
完整程式碼
附上完整程式碼供參考: gamer_ani_spider.py | GitHub
延伸練習
你能試著抓取動畫的圖片網址嗎? 會遇到什麼問題? 最後如何解決?
除了"本季新番"這個畫面的資料,它還可以切換到"週期表"的畫面。
這邊交由你試試看,能不能藉由文章的教學,實際自己爬取資料?
結語
在上方教學範例中,使用哪些 class 來定位都不是絕對,你可以嘗試不同的組合、不同的寫法。
從實作中摸索、犯錯後尋找解答是學習程式的一個很好的方法。
我陸續都有在寫一些網站的 Python網路爬蟲實例 ,如果你正好是剛開始想學爬蟲的新手、想知道某網站如何爬取資料、遇到其他問題,也歡迎在底下留言🔖,或追蹤 FB 粉專『 IT空間 』~ 🔔
我們總是在注意錯過太多,卻不注意自己擁有多少。
—— 《未聞花名》
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~