前言
最近這兩年受到疫情的衝擊,不少人遭到公司裁員,接下來可能就該思考尋找下份工作了。
台灣老字號、最大的人力銀行— 104人力銀行 ,我們來看看其網頁是如何向後端請求職缺資料,實際用 Python 來在 104 上搜尋職缺、查看職缺詳細資料。

備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任。
套件
此次 Python 爬蟲主要使用到的套件:
安裝
| |
搜尋職缺
當在104人力銀行網頁上方,輸入職缺的篩選條件後搜尋,下方會顯示出搜尋結果,中間也有許多篩選條件、排序方式供我們使用。
我們來找找"python"在"台北市"內現在有哪些職缺吧~
請求路徑與參數
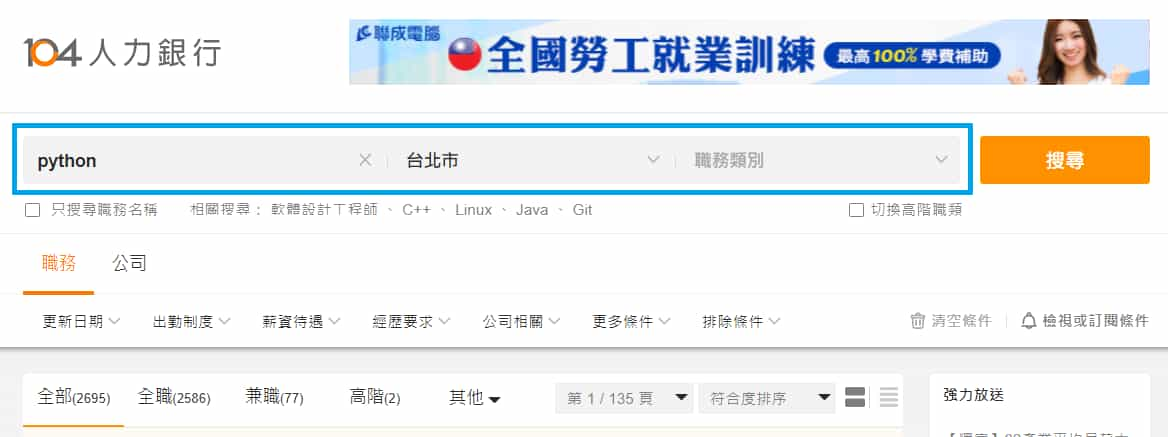
跟以前的步驟一樣,一開始先打開瀏覽器的 開發人員工具 (F12 或 Ctrl + Shift + i) > Network(網路) > XHR 分頁,找找網頁有沒有透過動態載入的方式請求職缺資料。
此時重新整理(F5)網頁,好像沒看見有關職缺資料的請求。
先別放棄,可以往下滾頁面或更改篩選條件,有了!發現到一個 list 開頭的請求,包含著職缺相關資料。
* 一開始點搜尋、網頁第一次載入卻沒有職缺的請求,應該是因為它已經崁入在網頁內一起傳送過來顯示了。
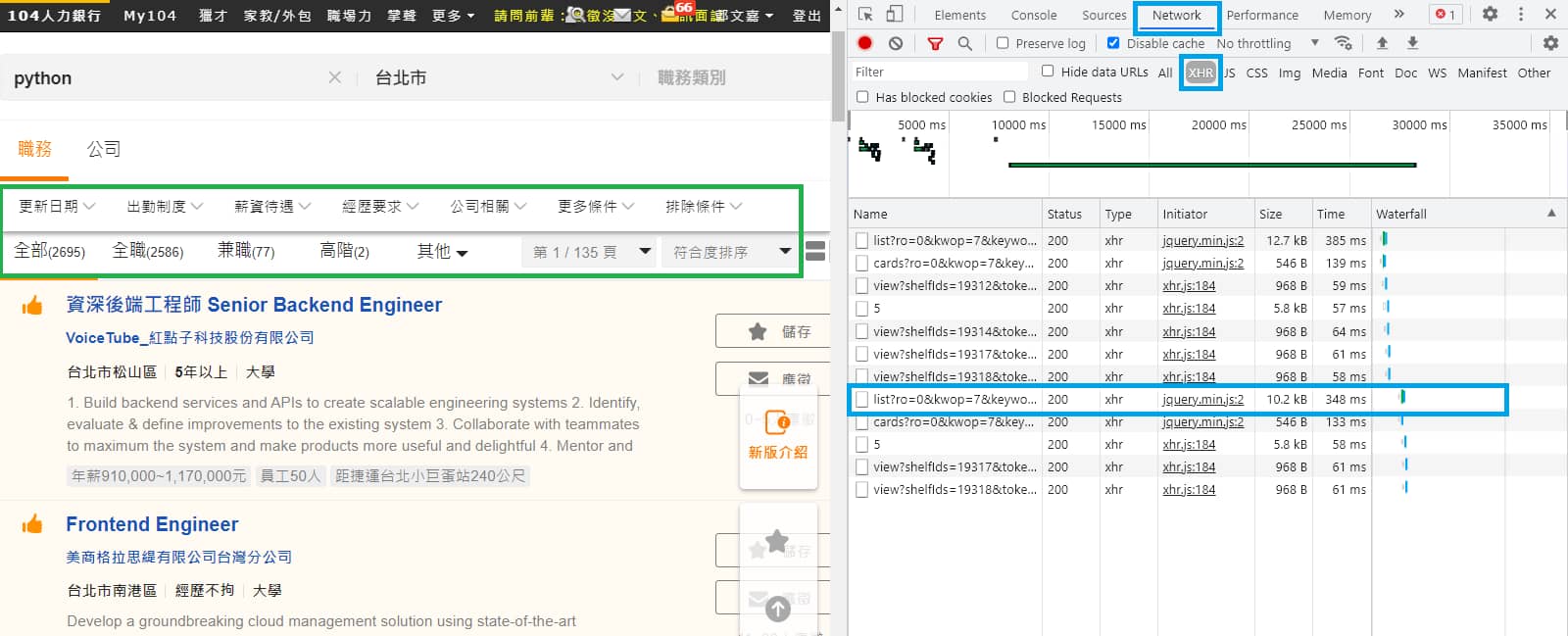
切回到 Headers 查看請求的方式與參數。

並且在用程式測試此請求時,發現還要帶上 Headers 內的 Referer 參數,才可正常取得資料。
將其整理出來,相關參數如下:
Request URL:https://www.104.com.tw/jobs/search/list
Request Methon:GET
Headers Referer:https://www.104.com.tw/jobs/search/
Query String Parameters:
ro: 0
kwop: 7
keyword: python
expansionType: area,spec,com,job,wf,wktm
area: 6001001000
order: 1
asc: 0
page: 1
mode: s
jobsource: 2018indexpoc
請求網址後方代的參數有很多,代表我們對職缺的篩選條件與排序條件,經過我的實測整理出以下。
篩選條件
某些條件可以多選(使用 , 連接),某些條件只能單選。
例如我要查詢"台北市"與"新北市"的職缺,就需要帶上 area=6001001000,6001002000。
頁數
page關鍵字
keyword地區
area
| 地區 | 數值 |
|---|---|
| 台北市 | 6001001000 |
| 新北市 | 6001002000 |
| 桃園市 | 6001005000 |
| 台中市 | 6001008000 |
| 彰化縣 | 6001010000 |
| 台南市 | 6001014000 |
| 高雄市 | 6001016000 |
- 上班時段
s9
| 上班時段 | 數值 |
|---|---|
| 日班 | 1 |
| 夜班 | 2 |
| 大夜班 | 4 |
| 假日班 | 8 |
- 是否輪班
s5
| 是否輪班 | 數值 |
|---|---|
| 不需輪班 | 0 |
| 輪班 | 256 |
- 休假制度
wktm
| 休假制度 | 數值 |
|---|---|
| 沒有週休二日 | 0 |
| 週休二日 | 1 |
- 更新日期
isnew
| 更新日期 | 數值 |
|---|---|
| 本日最新 | 0 |
| 三日內 | 3 |
| 一週內 | 7 |
| 兩週內 | 14 |
| 一個月內 | 30 |
- 經歷要求
jobexp
| 經歷要求 | 數值 |
|---|---|
| 1 年以下 | 1 |
| 1-3 年 | 3 |
| 3-5 年 | 5 |
| 5-10 年 | 10 |
| 10 年以上 | 99 |
- 科技園區
newZone
| 科技園區 | 數值 |
|---|---|
| 竹科 | 1 |
| 中科 | 2 |
| 南科 | 3 |
| 內湖 | 4 |
| 南港 | 5 |
- 公司類型
zone
| 公司類型 | 數值 |
|---|---|
| 上市上櫃 | 16 |
| 外商一般 | 5 |
| 外商資訊 | 4 |
- 福利制度
wf
| 福利制度 | 數值 |
|---|---|
| 年終獎金 | 1 |
| 三節獎金 | 2 |
| 員工旅遊 | 3 |
| 分紅配股 | 4 |
| 設施福利 | 5 |
| 休假福利 | 6 |
| 津貼/補助 | 7 |
| 彈性上下班 | 8 |
| 健康檢查 | 9 |
| 團體保險 | 10 |
- 學歷要求
edu
| 學歷要求 | 數值 |
|---|---|
| 高中職以下 | 1 |
| 高中職 | 2 |
| 專科 | 3 |
| 大學 | 4 |
| 碩士 | 5 |
| 博士 | 6 |
- 上班型態
remoteWork
| 上班型態 | 數值 |
|---|---|
| 完全遠端 | 1 |
| 部分遠端 | 2 |
排除關鍵字
excludeJobKeyword只搜尋職務名稱
kwop
| 只搜尋職務名稱 | 數值 |
|---|---|
| 只搜尋職務名稱 | 1 |
排序條件
- 排序依據
order
| 排序依據 | 數值 |
|---|---|
| 符合度 | 1 |
| 日期 | 2 |
| 經歷 | 3 |
| 學歷 | 4 |
| 應徵人數 | 7 |
| 待遇 | 13 |
- 排序順序
asc
| 排序順序 | 數值 |
|---|---|
| 由大到小 | 0 |
| 由小到大 | 1 |
回傳資料
切換到此請求的 Preview 分頁,能讓我們方便的檢視回傳資料,了解它的資料結構。
資料為 JSON 格式(原始資料可至 Response 分頁查看)。
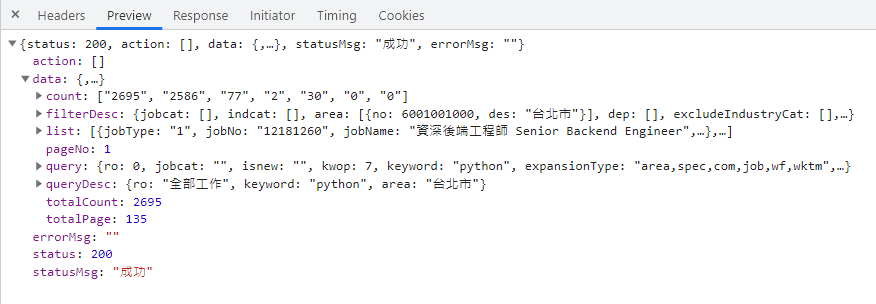
依照我觀察到的推測,來說明個欄位所代表的數值意思:
status、statusMsg、errorMsg:請求狀態與訊息。pageNo:頁數。data > count:各種類的職缺數量,如下圖藍框圈選內顯示數量。
各種類的職缺數量 data > totalCount:搜尋結果的職缺"總數"。data > totalPage:搜尋結果的職缺"總頁數"。data > list:搜尋職缺結果,包含各職缺名稱、簡介、公司等等資訊,通常一次最多 20 筆資料。data > query:搜尋職缺的 query 參數,也就是我們送出請求所夾帶的篩選條件,像是地區、經歷要求、上班時段。data > queryDesc:搜尋職缺的 query 參數所代表的意思。

* 其中得到的資料,有些還要進一步轉換或挑選,因此我們還可以再寫個函式來執行此步驟,可參考" 完整程式碼 "。
範例程式
使用 Python 搭配 requests 套件的寫法如下,:
| |
取得職缺詳細資料
透過上一步"搜尋職缺"所得到的職缺資料還不太完整,接下來我們來尋找取得職缺詳細資料的辦法。
這邊以 此職缺 為範例說明。
請求路徑與參數
如果你點進職缺介紹網頁後,在 開發人員工具 (F12 或 Ctrl + Shift + i) > Network(網路) > XHR 分頁,會發現它也是動態載入的方式請求。
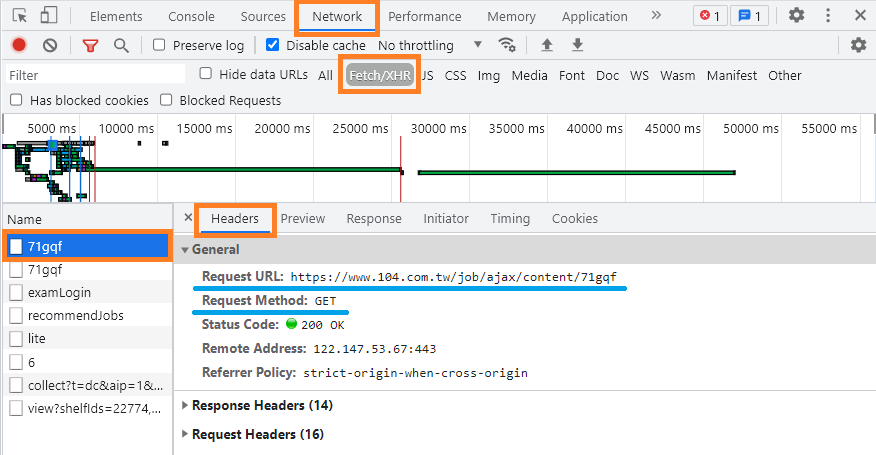
後方的 71gqf 代表此職缺的 ID。
還有請求一樣需要帶上 Headers 內的 Referer 參數,才可正常取得資料。
將其整理出來,相關參數如下:
https://www.104.com.tw/job/ajax/content/71gqfRequest Methon:
GETHeaders Referer:
https://www.104.com.tw/job/71gqf回傳資料
切換到此請求的 Preview 分頁,能讓我們方便的檢視回傳資料,了解它的資料結構。
資料為 JSON 格式(原始資料可至 Response 分頁查看)。
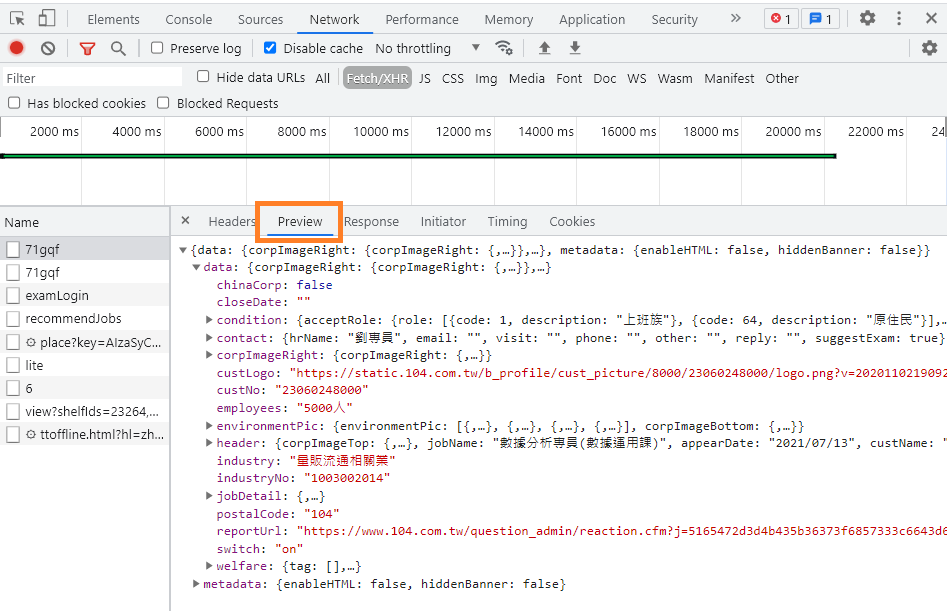
依照我觀察到的推測,來說明個欄位所代表的數值意思,在 data 底下:
header:標題。

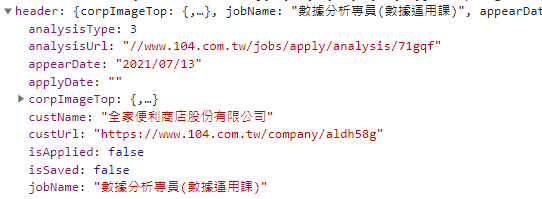
jobDetail:工作內容。


condition:條件要求,例如工作經歷、學歷要求、語文條件、擅長工具、工作技能等等。


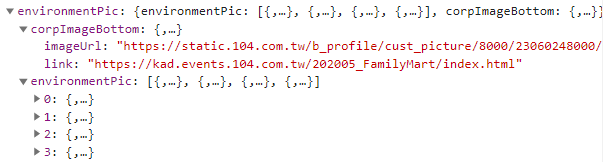
environmentPic:公司環境照片。
welfare:福利制度。


contact:聯絡方式,例如聯絡人、連絡電話等等。


範例程式
使用 Python 搭配 requests 套件的寫法如下,:
| |
完整程式碼
我將"搜尋職缺"與"取得職缺詳細資料"包成一個 class,可以傳入不同的值來篩選,供需要的人參考。
附上完整程式碼: job104_spider.py | GitHub
其他說明
"搜尋職缺"送出的請求中,我發現如果排序依據是選擇"符合度排序",它送出的請求第一頁是 order: 1,第二頁之後卻變成 order: 15。
如果有網友知道原因,歡迎底下留言跟我說(也可到 FB粉專 留言),我再補上說明,感謝~
延伸練習
在上方文章的"搜尋職缺"章節中,說了很多篩選參數(上班時段、經歷要求、學歷要求),但還是有些網頁上有的篩選條件沒有說到,例如"薪資待遇"、"外語要求",這部分你可以試著將它添加到程式內嗎?
(要注意的事,一個篩選條件不一定只有影響一個篩選參數)試著自己做個"自動職缺通知",設定好篩選條件後,以日期排序,每天晚上就排程執行程式,如果有新的職缺,馬上透過 Line 或 Email 通知你,讓你搶先別人一步收到訊息。
結語
除了後續可以嘗試自製 "自動職缺通知" 以外,從回傳的資料中,還可以發現有些網頁上沒列出來的資訊呢!
像是顯示 "11~30人應徵",到底準確是幾個人應徵,也可以從回傳資料中找到。
之後會繼續陸續寫一些網站的 Python網路爬蟲實例 ,如果你正好是剛開始想學爬蟲的新手、想知道某網站如何爬取資料、遇到其他問題,也歡迎在底下留言,或追蹤 FB 粉專『 IT空間 』~ 🔔
相信所有的挫折,都是最好的安排。
—— 郭婞淳 (台灣舉重國手)
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~