前言
來到 Python網路爬蟲實例系列 第四篇,本篇使用 Python 透過官方 YouTube Data API v3 來爬取 YouTube ,包含頻道資訊、影片清單、影片資訊等等資料。
從在 Google 雲端平台(Google Cloud Platform)創建一個專案開始,包括獲取 API 授權憑證、取得 API key,到撰寫抓取程式皆會一步步講解如何操作。最後同樣會附上完整程式碼供參考。
而如果你是想下載 YouTube 影片的話,本篇內容並不會提及,這部分可參考其他套件,例如 pytube
。
之前還有另外一個套件 Youtube-dl,但在寫這篇文章時發現美國唱片業協會(RIAA)點名 Youtube-dl 程式碼違反著作權法,並要求GitHub將它們移除(
來源
)。
備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任
套件
本次主要使用到的套件:
流程
要使用官方 YouTube Data API 抓取資料前,要先取得 API Key。
先到 Google 雲端平台(Google Cloud Platform)創建一個專案,並將 YouTube Data API 加入置專案內,獲取 API 授權憑證、取得 API key。
爬取資料這邊以 六指淵 Huber 頻道當範例,到上傳的影片列表抓取最新的前五則影片,再到影片內取得影片相關資訊及留言。
🔑 取得 YouTube Data API Key
先到
Google 雲端平台(Google Cloud Platform)
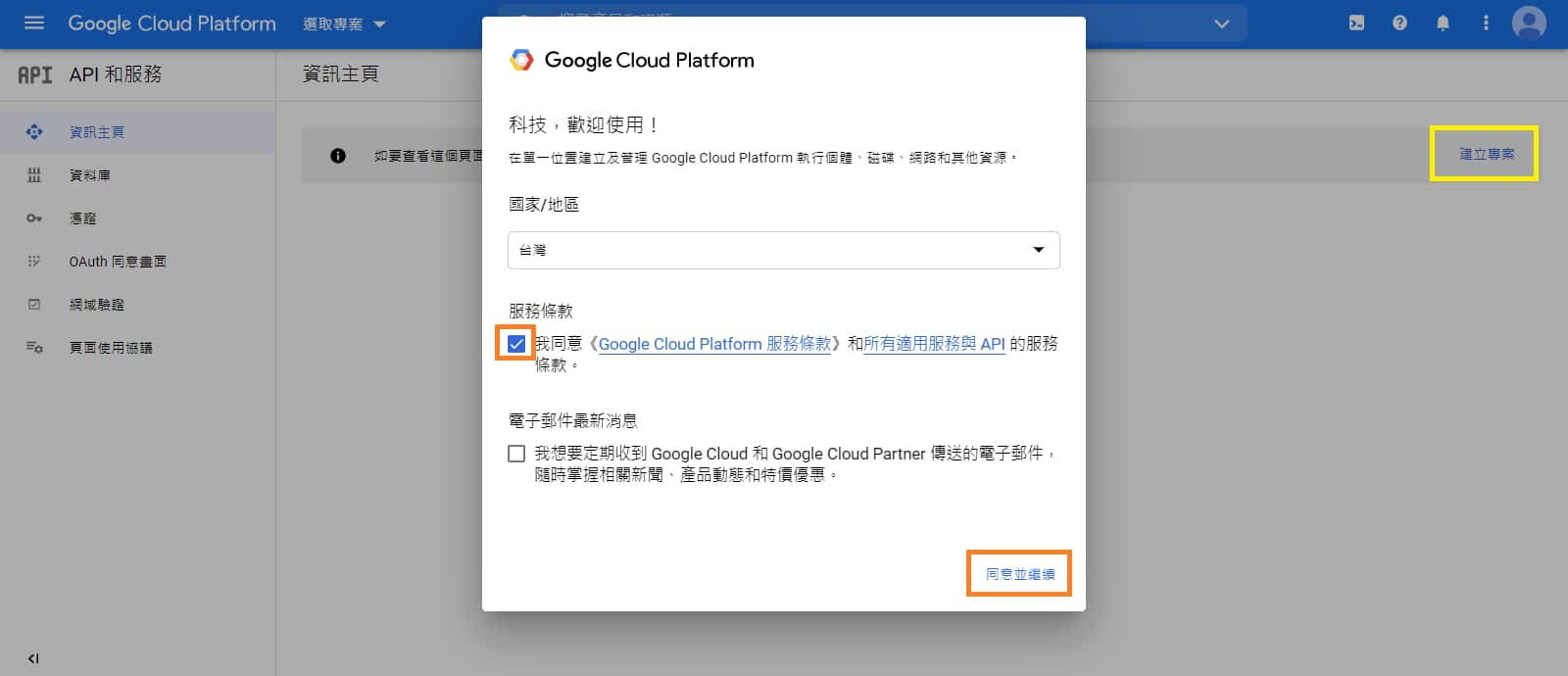
創建一個專案,如果是第一次進來會跳出服務條款,點選同意後繼續。
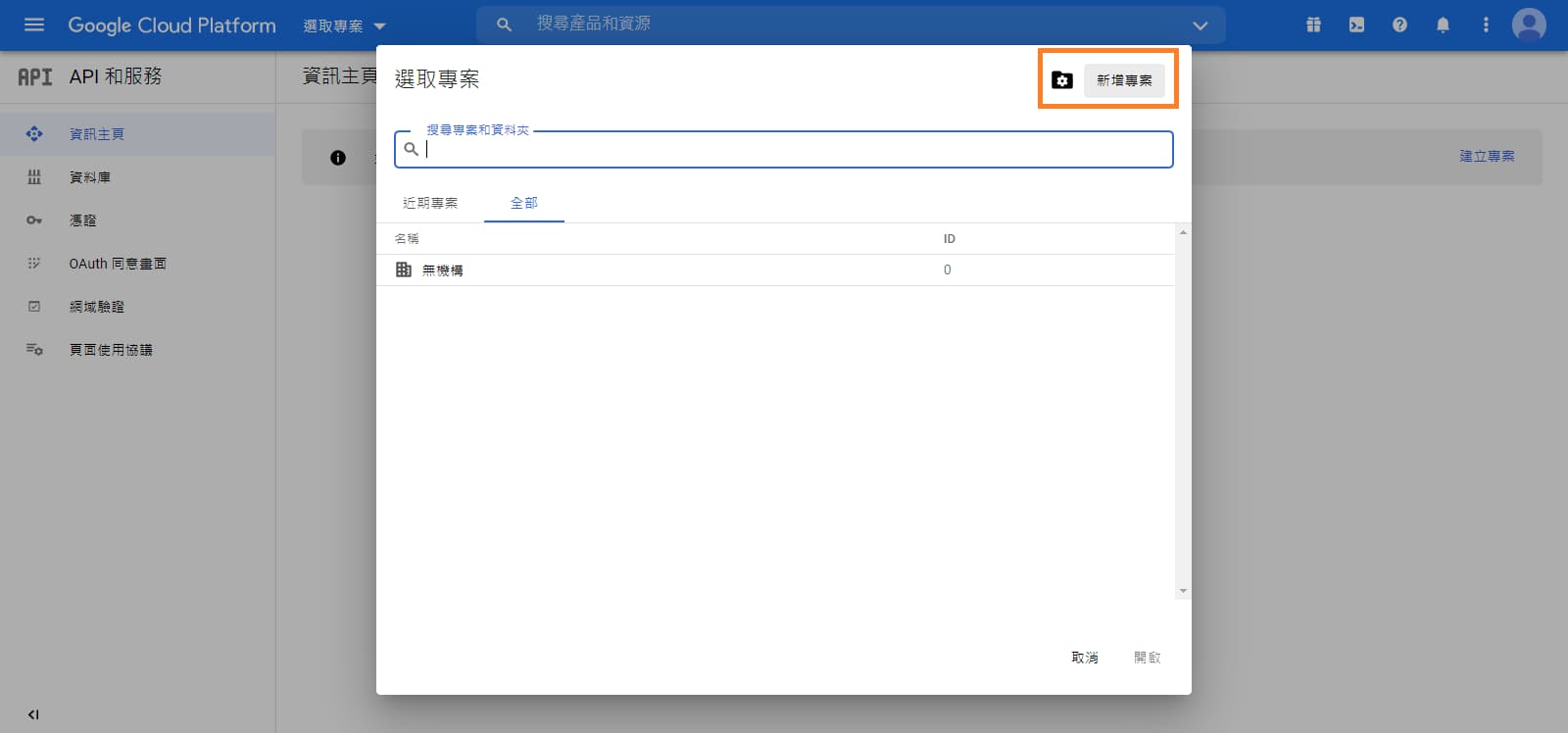
點擊右上角顯示"建立專案",或到上方的"選取專案"處建立。
右上角"新增專案"。
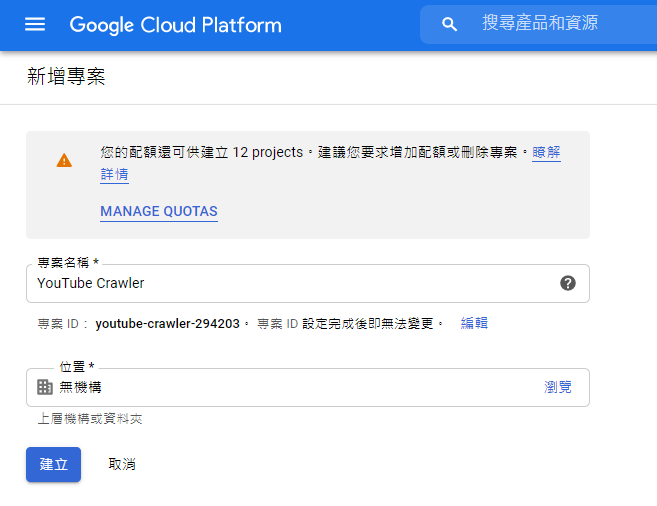
輸入"專案名稱",點選"建立"。
(專案ID也可以修改)
等它跑完後會進到此頁面,接下來要將我們需要使用的 API 加進來啟用。
點選"啟用 API 和服務"。
找到 YouTube Data API v3。
點擊"啟用"。
最後要建立憑證,並取得 API Key。
點擊右方"建立憑證",或者點擊左方的"憑證"。
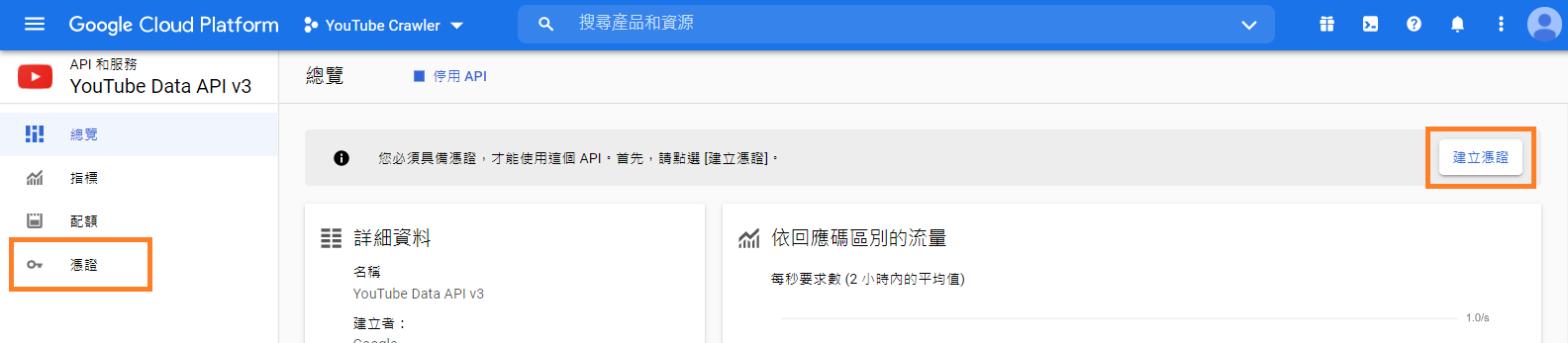
如果你是點擊左方"憑證",則依下圖所示建立 API 金鑰 (API Key)。
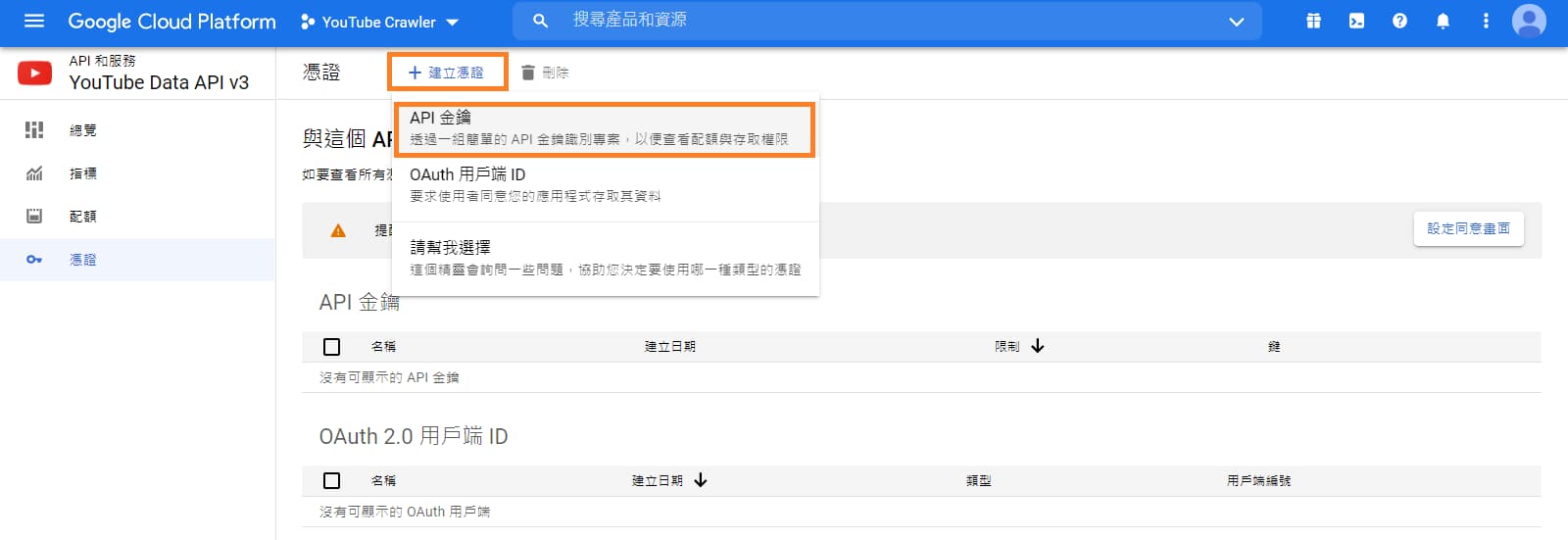
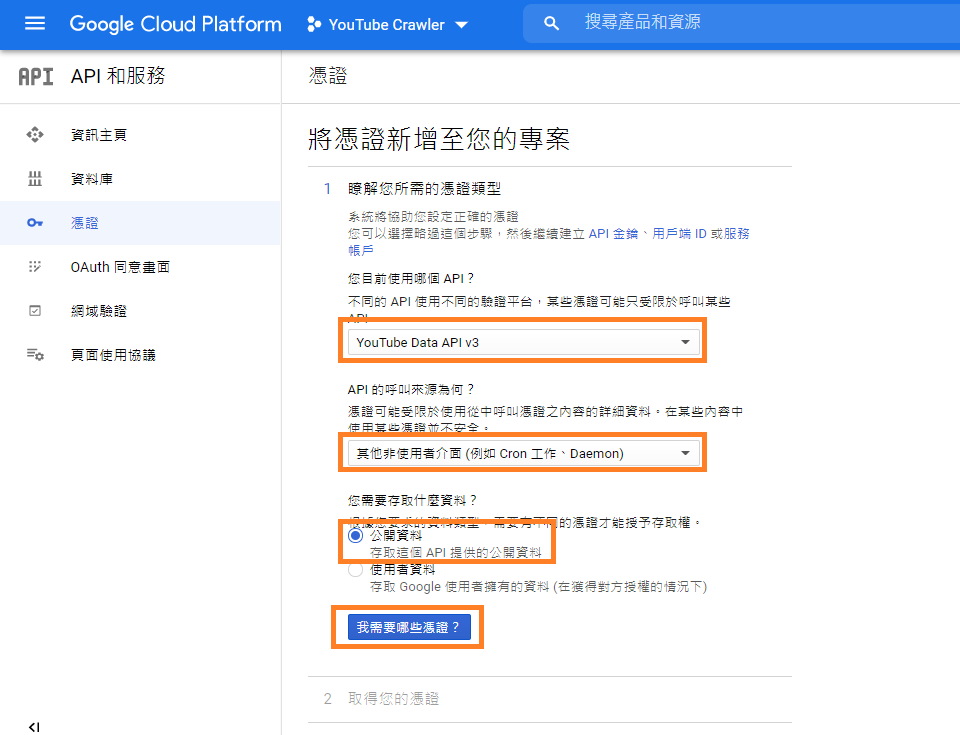
如果你是點擊右方"建立憑證",則依下圖選擇,並點擊"我需要那些憑證"。
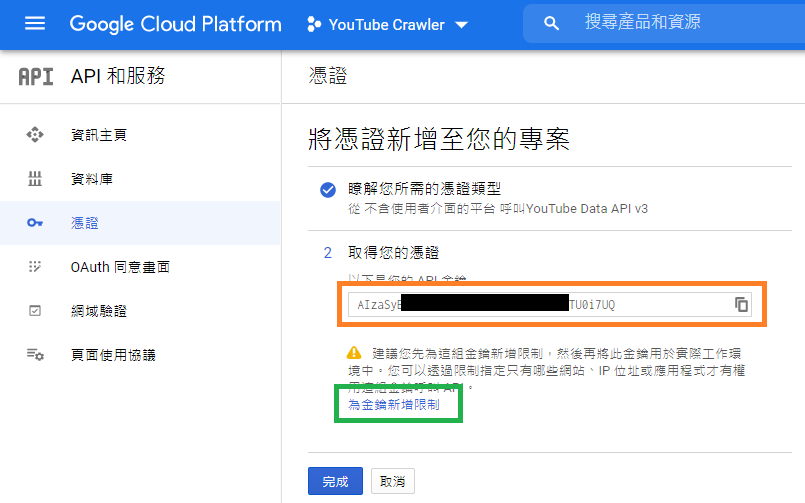
它會跳到此頁面,將 API 金鑰複製下來,待之後程式使用。
(也可以"為金鑰新增限制")
到這邊就完成 YouTube Data API Key 的取得,看似步驟很多,但實際操作過一遍就會了解了。
* 官方說明文檔
📘 爬蟲程式
本次是直接使用 API,因此在送出請求時就不需要加入 header 中 User-Agent 欄位了。
先在上方定義剛剛取得的 API Key,待之後發出請求時帶入。
(YOUR_YOUTUBE_API_KEY 換成剛剛在上一步取得的 API Key)
| |
API 說明
在 官方 API 文件 內,可以查詢各種資源及各種請求方法。
在本次程式中會用到幾種資源 (這邊都只需使用 list 方法):
- channels :取得頻道"上傳影片清單"的 ID
- playlistItems :取得清單中的影片列表
- videos :取得影片資訊
- commentThreads :取得影片底下留言
本教學都只使用到 list 方法(GET),因此網址串好後可以直接貼到瀏覽器上測試,觀看它回傳的資料。
因為每一次送出請求皆需要帶上 API Key,而且回傳資料要轉換JSON,所以可以另外寫一個用於組合網址、請求的函式,也可在裡面做當請求失敗的處理。
| |
* 為了較清楚的了解流程,以下範例程式內沒有加入太多的例外處理。
取得頻道"上傳影片"清單的 ID
想要抓取頻道內上傳的影片前,需要先抓到"上傳影片"清單的 ID,再用此 ID 去取的影片清單。
使用
channels
路徑來取得,需帶上"id"、"key"、"part"等查詢參數。id 代表頻道 ID;key 代表我們的 API Key;part 代表想取得的資源屬性。
頻道ID的取得方式可以先到頻道首頁,觀察網址後方帶的數值,例如:https://www.youtube.com/channel/UC7ia-A8gma8qcdC6GDcjwsQ
"channel/"後方的 UC7ia-A8gma8qcdC6GDcjwsQ 就代表此頻道的 ID。
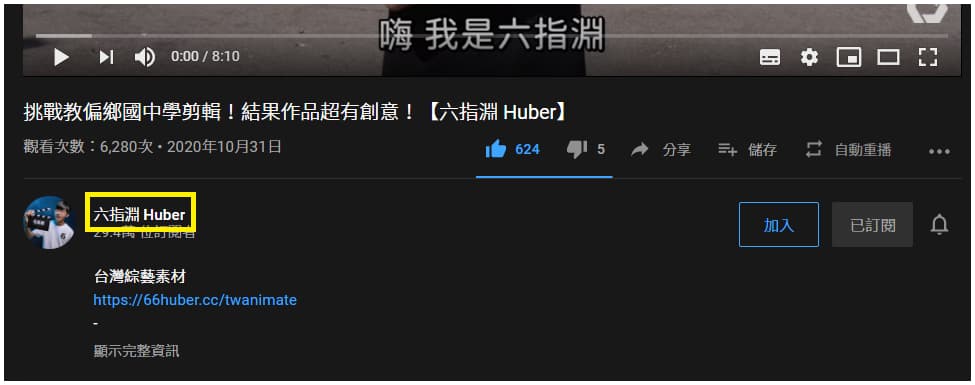
不過有時會發現網址是呈現以下形式:https://www.youtube.com/c/六指淵Huber
別擔心,此時隨便點擊頻道底下的其中一支影片,在點中間的頻道名稱進入後,一樣即可看到網址後方的數值。
至於"part"需帶什麼數值可以參考
官方 API 文檔
說明,也可以一個一個嘗試看看會回傳什麼資料。
因為請求方式是使用 GET,因此可以直接貼到瀏覽器上測試。https://www.googleapis.com/youtube/v3/channels?part=contentDetails&id=UC7ia-A8gma8qcdC6GDcjwsQ&key={YOUR_API_KEY}

==> 回應資料範例
其中 uploads 後面那串就是此頻道"上傳影片"清單的 ID,這邊是 UU7ia-A8gma8qcdC6GDcjwsQ。
| |
取得清單中的影片列表
好的,接下來取得"上傳影片"清單的影片吧~
使用
playlistItems
路徑來取得,需帶上"playlistId"、"key"、"part"等查詢參數。playlistId 代表播放列表 ID;key 代表我們的 API Key;part 代表想取得的資源屬性。
這邊代的參數大部分與上方雷同,可以自行參考官方 API 文檔說明,就不多說介紹了。
我們要抓此頻道上傳影片,所以 playlistId 帶入上一步抓到的"上傳影片"清單的 ID。
https://www.googleapis.com/youtube/v3/playlistItems?part=contentDetails&playlistId=UU7ia-A8gma8qcdC6GDcjwsQ&key={YOUR_API_KEY}

==> 回應資料範例
| |
取得影片資訊
針對每一支影片,來取得其影片相關資訊吧~
使用
videos
路徑來取得,需帶上"id"、"key"、"part"等查詢參數。id 代表影片 ID;key 代表我們的 API Key;part 代表想取得的資源屬性。
https://www.googleapis.com/youtube/v3/videos?part=snippet,statistics&id=lM7ltxkXE40&key={YOUR_API_KEY}
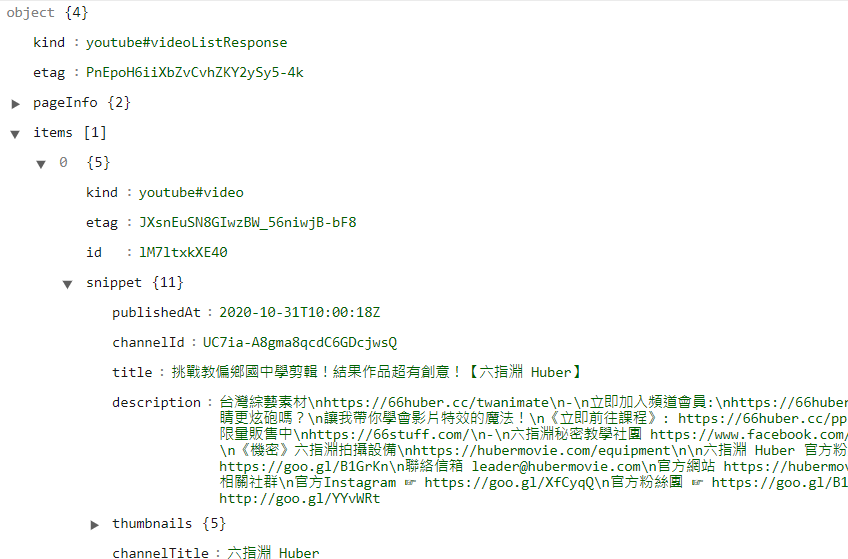
==> 回應資料範例
回傳資料有影片標題、頻道名稱、發布時間、縮圖網址、觀看數、留言數……等等許多相關資訊。
* 謝謝網友提醒,dislikeCount 資訊現在無法取得了,這應該也是因應 YouTube 現在不能看到 Dislike 的數量了。
Note: The statistics.dislikeCount property was made private as of December 13, 2021. This means that the property is included in an API response only if the API request was authenticated by the video owner. See the revision history for more information.
| |
取得留言資訊
那該如何取得影片底下的留言呢?
使用
commentThreads
路徑來取得,需帶上"videoId"、"key"、"part"等查詢參數。videoId 代表播放列表 ID;key 代表我們的 API Key;part 代表想取得的資源屬性。
https://www.googleapis.com/youtube/v3/commentThreads?part=snippet&videoId=lM7ltxkXE40&key={YOUR_API_KEY}
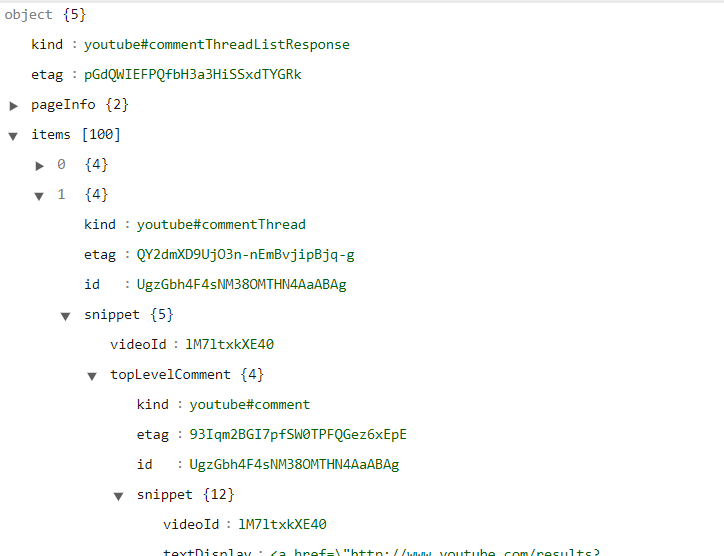
==> 回應資料範例
| |
其他查詢參數
還有其他常用的查詢參數:
像是 maxResults 可以限制回傳筆數,搭配 commentThreads 帶入 maxResults=10 代表最多回傳 10 筆留言。
又例如 pageToken 是用來換頁的,什麼意思呢?
像是 API 有限制留言最多一次只能抓 100 筆留言,就算你帶入 maxResults=200 也只能抓到 100 筆。
但在回傳的資料中可以發現一個 nextPageToken 欄位,代表你再用一樣的網址請求一次,帶上 pageToken=QURTSl9pMmhMYktBc25xOHZtZTg3enJBTFFXNTFPbldJY05zTFFTTjdMM25VYThmdTBwWS1CNGFPZm1kQUU0WkJac0dWZkw3cWI2V1owOA== 就能取得下一頁的資料(例如:101~200 筆留言)。

在像是有多個留言(commentThreads)或多支影片(playlistItems)時需要用到。
以上一段取得留言為例,會像是如下:
https://www.googleapis.com/youtube/v3/commentThreads?part=snippet&videoId=lM7ltxkXE40&pageToken=QURTSl9pMmhMYktBc25xOHZtZTg3enJBTFFXNTFPbldJY05zTFFTTjdMM25VYThmdTBwWS1CNGFPZm1kQUU0WkJac0dWZkw3cWI2V1owOA==&key={YOUR_API_KEY}完整程式碼
附上完整程式碼:
youtube_spider_api.py
(對超連結右鍵 > 另存連結為)
注意事項
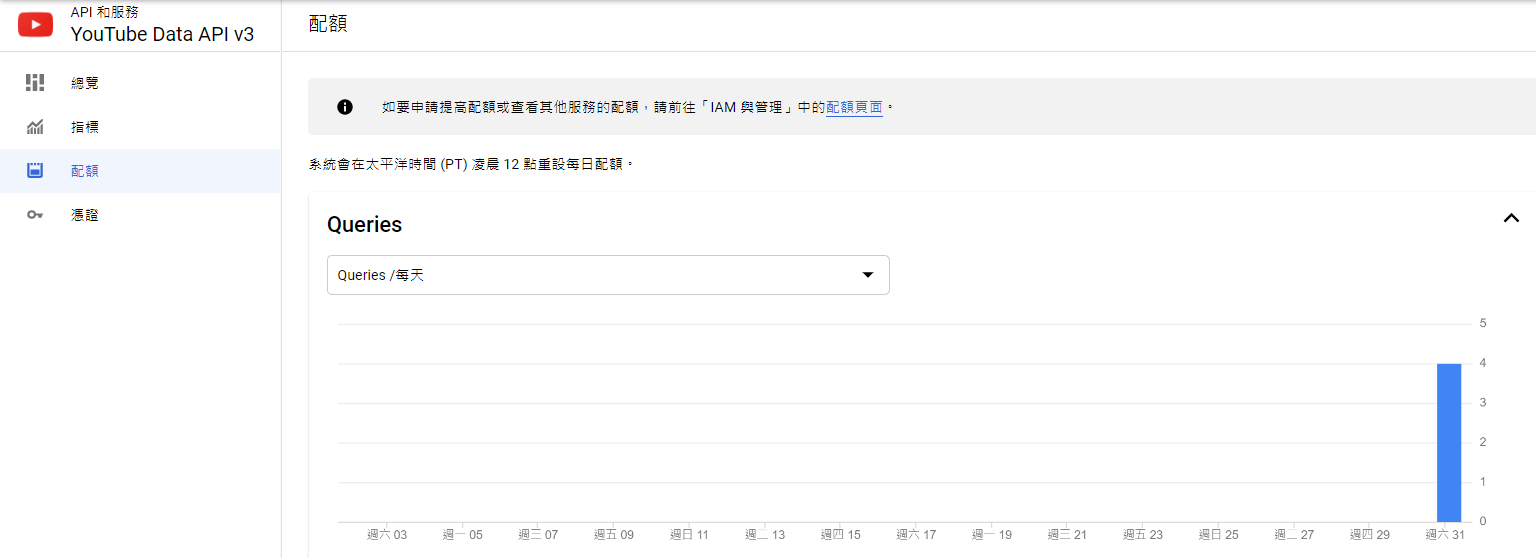
要注意的是這個 API 有額度的限制,為每天 10,000 個單位(
官方說明
),如果想將影片的留言都抓下來,可能就會耗費較多額度。
像上方使用的查詢都是消耗 1 單位。
在
配額頁面
可以查看此專案目前耗費的單位。
延伸練習
在上方教學中,影片清單只有取得前 5 則影片,那如果我想取得前 100 則影片呢?是不是會遇到什麼問題?需不需要加上什麼參數?
* 提示:參考教學中爬取留言的方法,使用pageToken參數。上方教學只說抓取留言,那我如何想取得留言的回覆呢?是要帶入什麼參數嗎?或者是使用不同的方法?
* 提示:part中的 replies ,或 Comments 資源。
結語
我會陸續寫一些網站的 Python網路爬蟲實例 ,如果你正好是剛開始想學爬蟲的新手、想知道某個網站如何爬取資料,或者遇到其他問題,歡迎過來參考和在底下留言~👇
每一個成功者都有一個開始。
勇於開始,才能找到成功的路。
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~