前言
Python網路爬蟲實例系列 第二篇,本篇一步步講解如何使用 Python 爬取 udn聯合新聞網 的即時列表新聞,包含更多新聞採 Ajax 動態載入的部分,最後也會附上完整程式碼供參考。
備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任
套件
此次 Python 爬蟲主要使用到的套件:
流程
首先進入 聯合新聞網-即時列表 網頁,觀察其新聞列表載入方式,使用瀏覽器的開發人員工具找出 Ajax 請求網址,透過此網址取得新聞列表的 JSON 格式資料,如此即可抓取新聞網址、標題、閱覽數等等資料。
以下範例說明皆以「即時列表-不分類」舉例,其他類別所需要帶入的參數可能稍微不同。
爬蟲程式
網站有些常見的反爬蟲機制是偵測你送來 requests 的 header 中 User-Agent 欄位,因此我們就需要模仿一般瀏覽器送出去的資料。
先在上方定義 HEADERS 變數,待之後需要發出請求就帶入此數值。
| |
如何載入更多新聞
跟前一篇實例教學 (
[Python爬蟲實例] 巴哈姆特哈啦區
) 最不一樣的,是使用瀏覽器閱覽網頁明明就看到許多篇新聞,一直往下滾就一直產生,但使用程式抓取只能取得前 28 篇新聞。
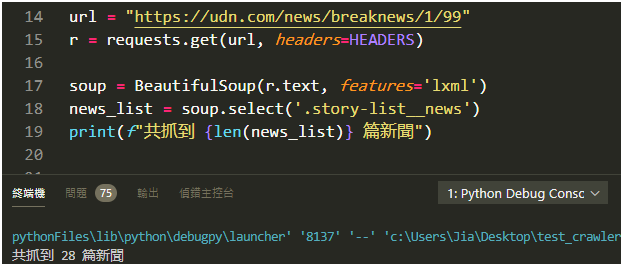
為什麼會這樣?!
原來當我們網頁往下滾後,它會透過 Ajax 動態載入後續新聞資料,並不在我們一開始請求後回傳的網頁原始碼內,難怪無法抓取。
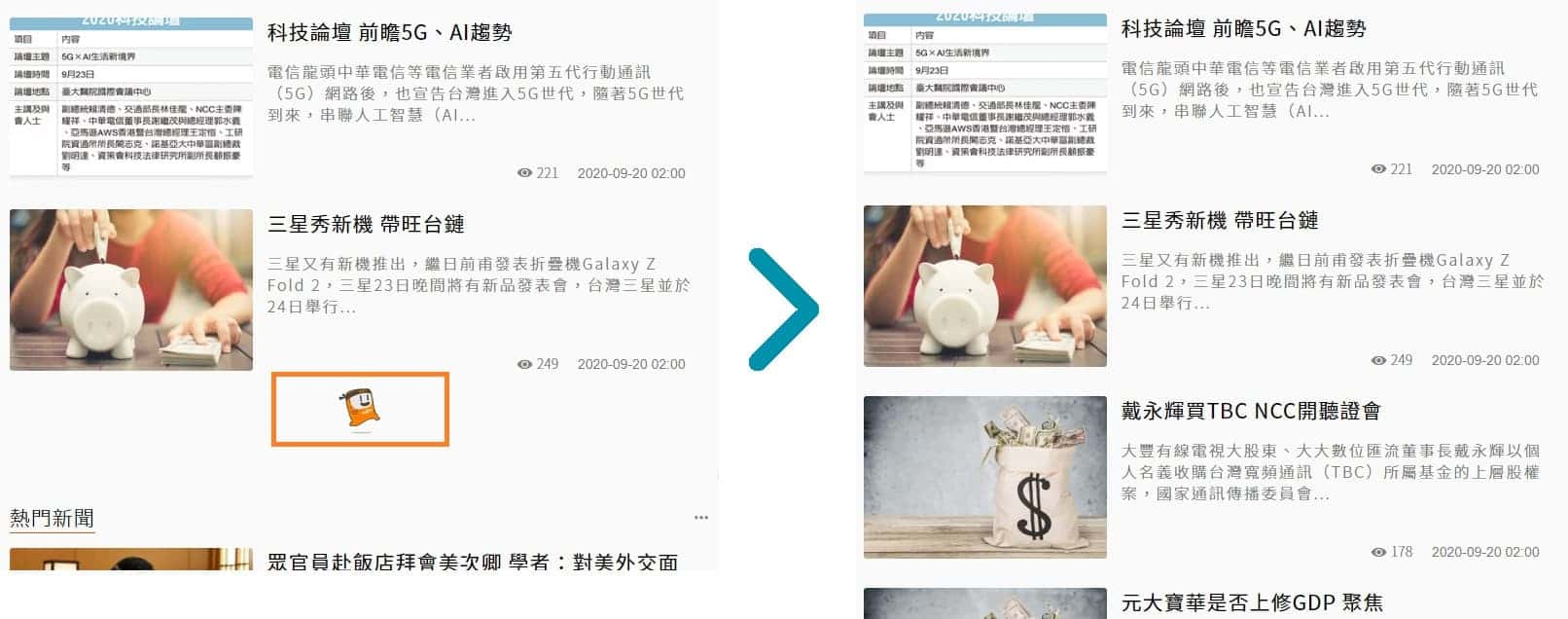
針對這種採用 Ajax 動態載入的網頁,有兩種方式來取得資料:
- 一種是使用 Selenium 來操作瀏覽器載入資料。
- 另一種(也就是本篇教學要使用的方式)是找出 Ajax 去請求的網址,然後照他的請求方式、參數來取得資料。
我們來試著找出它動態載入的網址吧。
打開瀏覽器的 開發人員工具 (F12 或 Ctrl + Shift + i) > Network(網路) 分頁,切換到XHR,重整網頁一下(F5)讓它載入資料﹐並把網頁往下滾讓它載入更多新聞資料,會發現有新的項目出現。
單點選它之後,右邊選擇 Preview 分頁,即可發現這就是我們想要的資料。
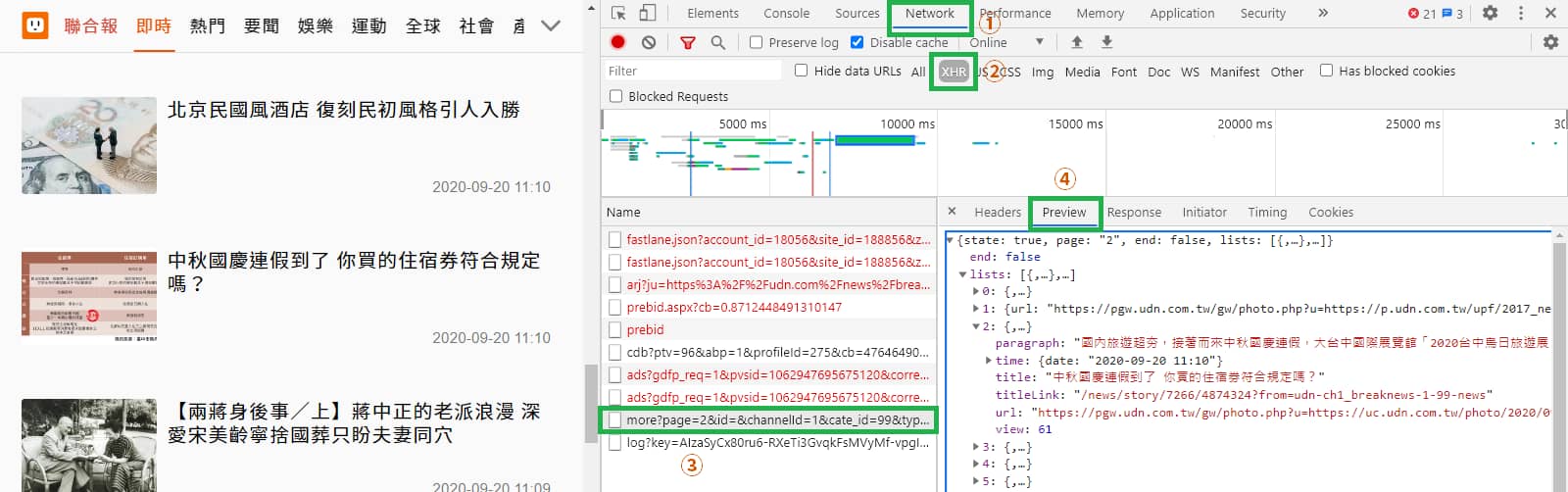
所以概念就是,是當我們網頁往下滾到底部後,會觸發網頁的 JavaScript 程式,讓它透過 Ajax 動態載入,將新聞資料一直載入進來。
試著載入更多新聞
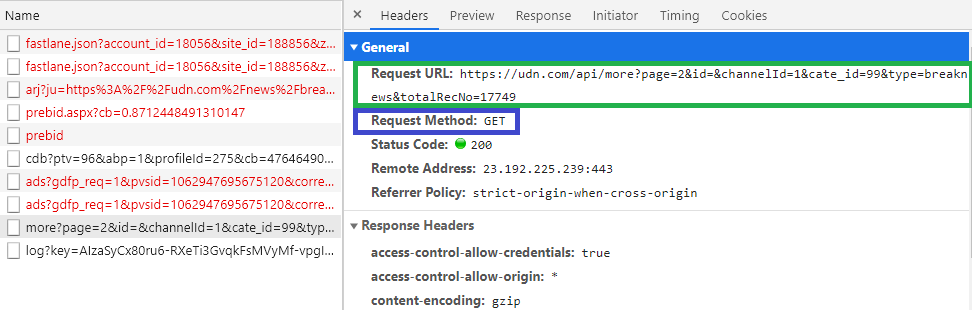
切換到 Headers 分頁,會顯示請求的網址(綠色框)以及請求方式(紫色框),如此圖片顯示是使用 GET 方式,我們在瀏覽器中輸入網址前往就是 GET 請求方式。
https://udn.com/api/more?page=2&id=&channelId=1&cate_id=99&type=breaknews&totalRecNo=17749
將網址複製起來,瀏覽器開個新分頁,貼上網址後 Enter 前往,收到的資料即是我們需要的更多新聞。
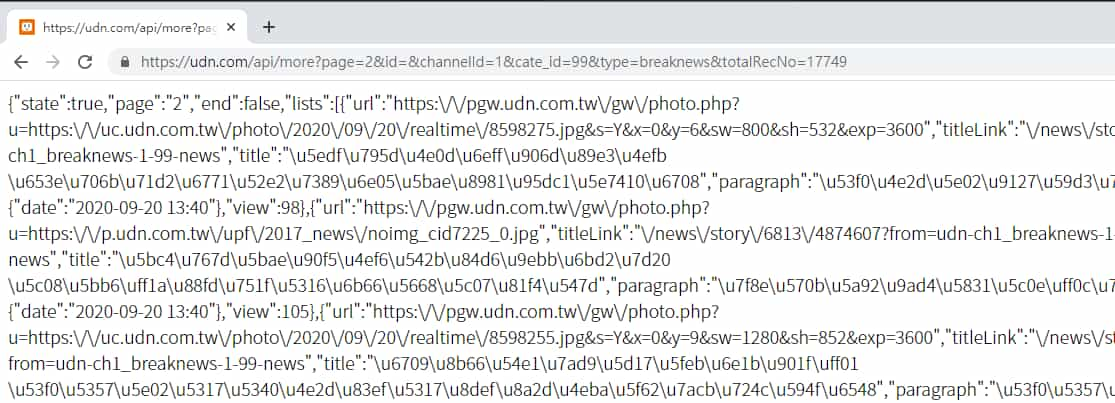
觀察回傳資料
取得資料後,為了方便觀察,可以找尋線上 JSON 工具或瀏覽器擴充功能來輔助,這邊我使用 JSON Editor Online 來演示。
進入網頁後,將剛剛回傳的資料貼在左方欄位內,點擊 Copy(綠色框) 將文字整理、檢查、轉碼並顯示於右側,為了方便觀察,點擊 tree(藍色框) 將其以樹狀結構來顯示。
而且可以發現它有幫我們把原本看不懂的 Unicode編碼 轉換過來。
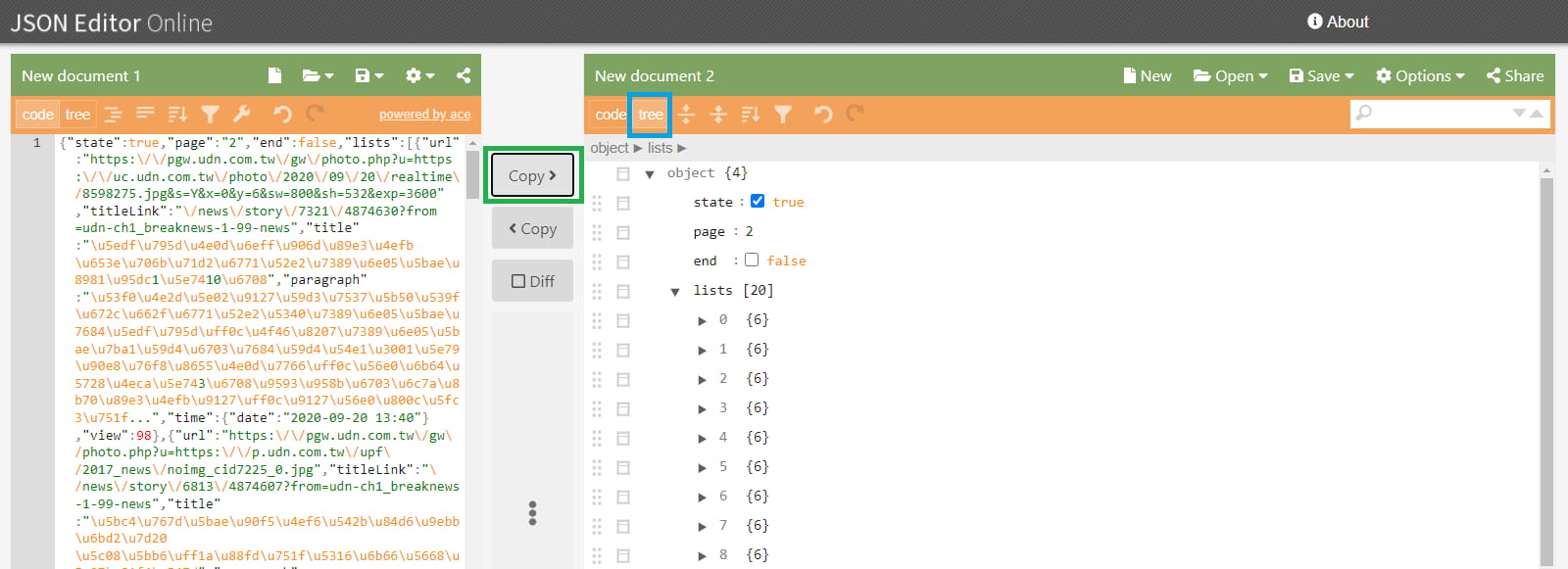
新聞資料都放在 lists 底下,共有 20 篇,其每一篇所包含的欄位有url、titleLink、title、paragraph、time、view,代表意義如下表:

| 參數 | 代表意思 | 格式 |
|---|---|---|
| url | 圖片網址 | 文字 |
| titleLink | 新聞文章網址 | 文字 |
| title | 新聞標題 | 文字 |
| paragraph | 段落簡介 | 文字 |
| time | 日期時間 | 文字 |
| view | 閱覽數 | 數字 |
好了!大致都知道了,來開始將想法轉換為程式吧~ 😙
爬取文章列表
* 為了簡化程式碼方便理解,像上次判斷請求是否成功的部份,這次將其省略。
| |
來看一下前面動態載入的網址,
https://udn.com/api/more?page=2&id=&channelId=1&cate_id=99&type=breaknews&totalRecNo=17749
網址後方參數的部分有 page、id、channelId、cate_id、type、totalRecNo 六個,經過我的測試,只需要的 page、channelId、cate_id、type 四個即可取得一樣的資料。
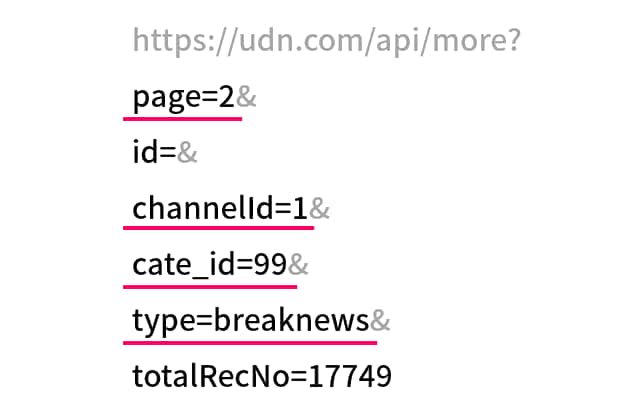
除了 page 是頁數,其他的需要自行前往網站找尋"什麼類別、分類對應哪個編號"、"需要那些參數"。
像是:
即時列表-不分類
channelId: 1cate_id: 99type: breaknews即時列表-地方
channelId: 1cate_id: 3type: breaknews運動-最新
channelId: 2type: cate_latest_newscate_id: 7227運動-棒球
channelId: 2type: subcate_articlescate_id: 7227sub_id: 7001
將網址與參數組合起來準備送出請求,頁數 page 的部分可使用 for 迴圈來歷遍。
| |
回傳資料是以 JSON 的格式,跟 HTML 相比很方便從中取出資料,也不要再使用 BeautifulSoup 解析,在 Python 類似 Dict 格式。
有兩種方式將其轉成 Dict:
- requests 提供的
r.json()解碼轉換 - 一樣使用
r.text取出字串,再用json.loads()將其轉換
這邊我就直接使用 requests 提供的 r.json() 來轉換,最後將資料中 'lists' 抓出來 (也就是新聞資料)。
一樣加上時間延遲 time.sleep(),避免太頻繁的爬取,造成對方伺服器的負擔。
注意,這邊使用 random.uniform 來達到一段隨機範圍時間。
| |
執行結果如下:
| |
完整程式碼
附上完整程式碼:
udn_spider.py
(對超連結右鍵 > 另存連結為)
延伸練習
試著抓取不同分類裡的新聞列表,例如:"即時列表-運動"、"數位-數位焦點"。
如果想抓取文章內容全文,則需進入文章網址爬取,但這邊要注意的是其有幾種不同的網頁結構,需各別判斷並有不同的解析方式。例如:
結語
我會陸續慢慢寫一些網站的"網路爬蟲實例",如果你正好是剛開始想學爬蟲的新手、想知道某個網站如何爬取資料,又或遇到其他問題,歡迎過來參考和在底下留言ㄛ~😙
用你的微笑改變世界,
但別讓世界改變了你的微笑。—— 劉軒
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~