前言
現在各式 LLM (大型語言模型) 滿天飛,你有沒有想過讓模型可以參考你自己的資料來回答呢?
就像一個屬於你的 AI 知識庫管家,有問必答,還會標示引用文件的來源,讓你還可以回去原始文件參考。
今天要來帶大家使用 Python 中的 LlamaIndex 套件,搭配免費的 Gemini 模型 API,打造屬於你自己的 RAG (Retrieval Augmented Generation) 個人知識庫✨。
文章前半部會先介紹 RAG 架構 (什麼是 RAG、RAG 流程),後半部再來使用 LlamaIndex 套件搭配 Gemini API 實際撰寫 RAG 架構程式碼。
什麼是 RAG?
RAG (Retrieval Augmented Generation,檢索增強生成) 是一種結合檢索搜尋和生成的自然語言處理架構。讓 LLM (大型語言模型)在生成回覆以前,從外部知識庫搜尋相關資料,並使用這些資訊生成更準確、更全面的答案。
純粹的語言模型僅依賴於訓練語料,而 RAG 則能在生成時動態地加入額外知識,生成更準確、更相關、更具可靠性的輸出。
來一個簡單的比喻,更容易理解:
想像你是一位學生,要寫一篇關於台灣歷史的報告。
一般 LLM 就像一個沒有外部資源的學生,只能憑藉自己的記憶和理解來寫報告,這可能會導致報告內容不準確、不全面,甚至出現錯誤。
而 RAG 架構的學生,會先去圖書館查閱資料,會找到一些有關台灣歷史的資料,然後用這幾個相關資料來彙總、寫報告,這樣可以大大提高報告的準確性和全面性 (而且還能看到資料是從哪本書來的)。
RAG 流程
RAG 模型的架構主要可分成以下兩個階段:
- 索引 (Indexing):事前準備。從來源取得資料,並為其建立索引後儲存起來。
- 檢索和生成 (Retrieval and generation):使用者發問後,會從索引中搜尋相關資料,然後將其傳遞給模型並生成回覆。
對應我下方自己畫的流程圖,灰色部分(A~C)就是「索引」、藍色部分(1~5) 就是「檢索和生成」。
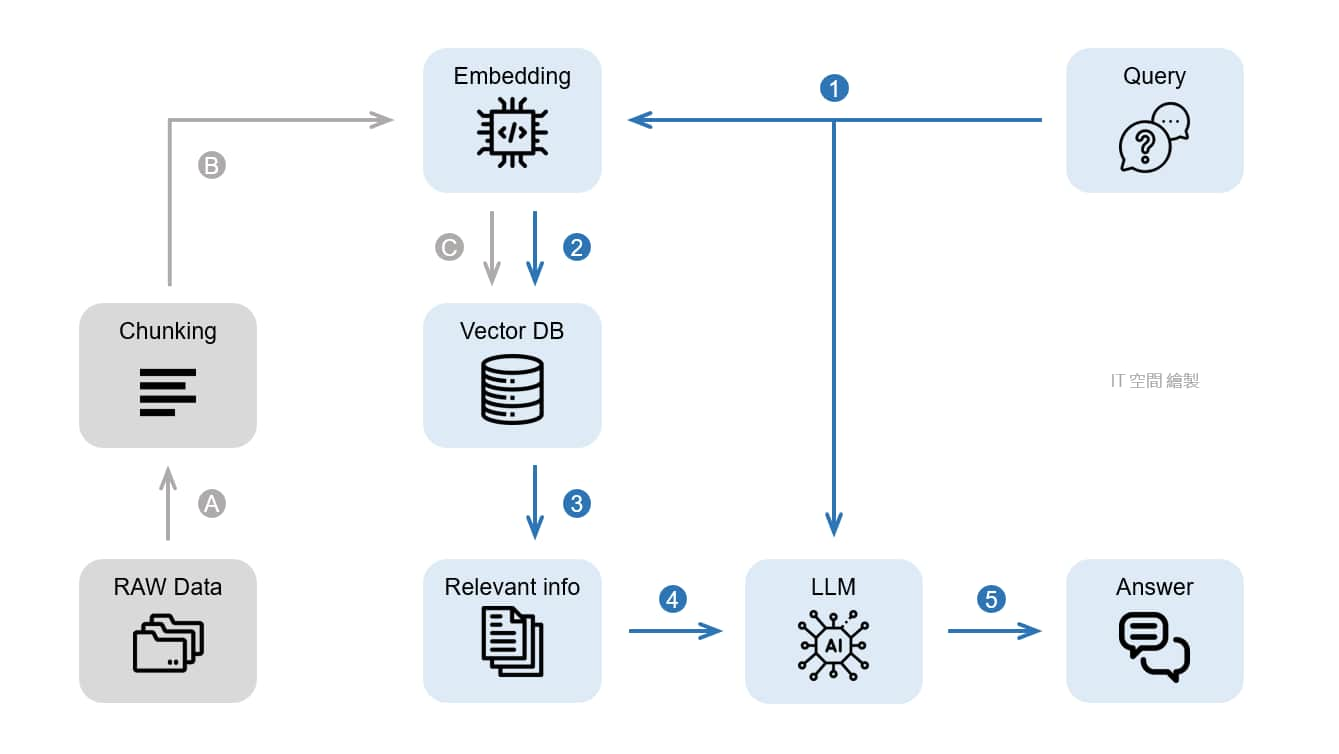
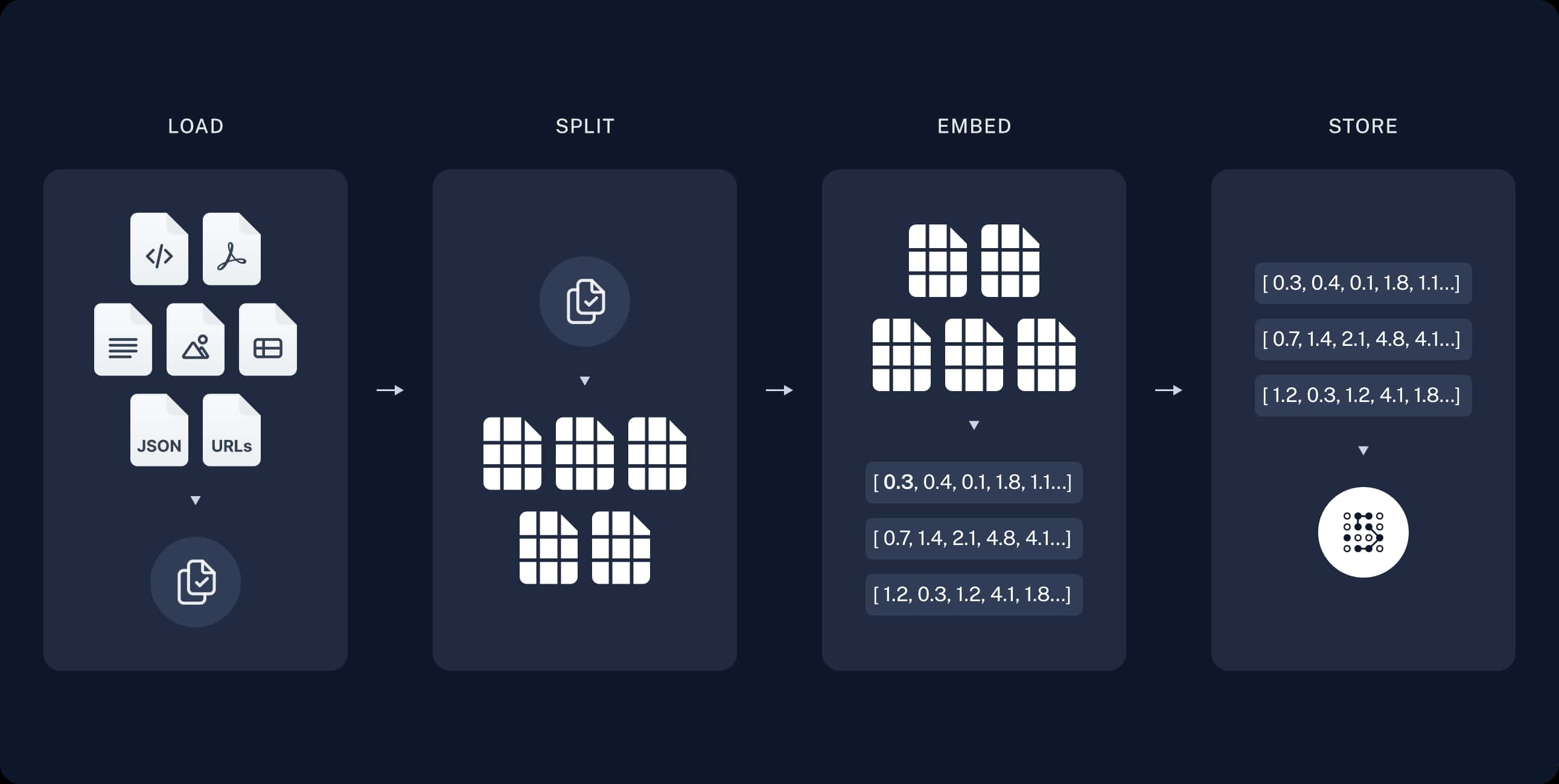
索引 (Indexing) 階段
- A:將我們準備好的資料 (有可能是 公司內部文件、產品常見問答集、專業文獻、特定領域的專業知識 等等) 切分成較小的區塊(chunk)。因為區塊內容太多較難搜尋,而且 LLM 模型也有字數限制。
- B:將區塊的內容透過 Embedding model 轉換成向量(一組數字),因為後續能比對資料間的向量距離,來判斷其相似程度。
- C:將轉換好的向量 (連同原始資料) 儲存至向量資料庫。
此流程只需要做一次就好,或者當原始資料有新增、更新時再執行即可。
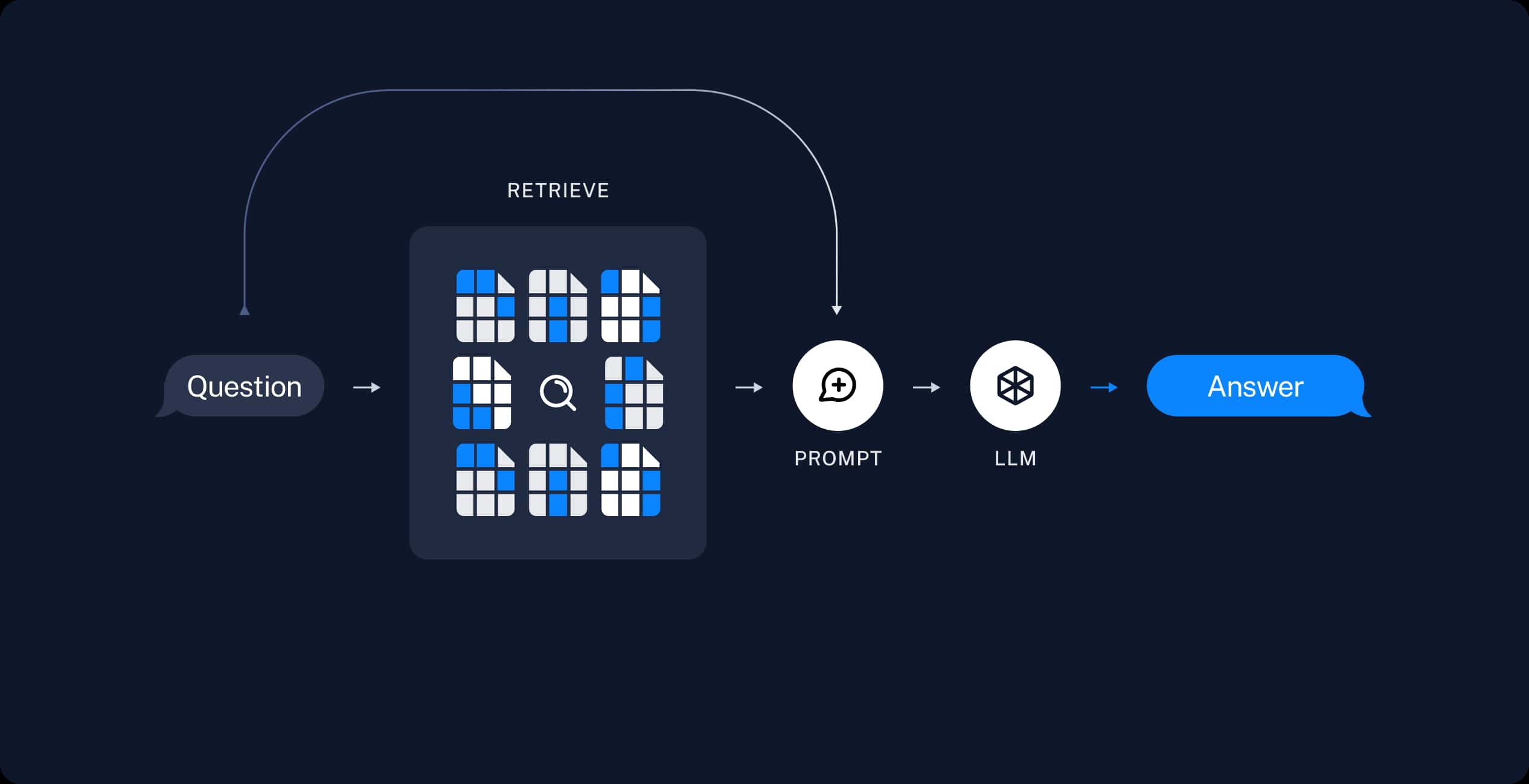
檢索和生成 (Retrieval and generation) 階段
- 1:將使用者的問題一樣透過 Embedding model 轉換成向量。
- 2、3:拿問題向量去向量資料庫中找出相關的區塊。
- 4、5:將 "相關區塊" 與 "使用者的問題" 一起給 LLM 生成答案。
使用 Promt Enginerring (提示工程) 或 Fine-tuning (微調) 不行嗎?
Promt Enginerring (提示工程):
透過一些提示(Promt)技巧來引導模型,輸出較高品質、正確性的結果。
例如:角色扮演、將複雜的任務拆分為更簡單的子任務、一步步思考……等等。Fine-tuning (微調):
在已經預訓練過(pre-trained)的模型基礎上,用自己準備的資料進一步訓練,讓模型的輸出能夠更符合我們的預期。
例如:特定口吻、風格、格式、或加入自己的資料。
RAG 相較於「Fine-tuning (微調)」或「Promt Enginerring (提示工程)」有幾點優勢:
- 節省成本:不用像 Fine-tuning 需要訓練模型,節省時間成本、金錢成本(和硬體成本)。
- 資料即時性:Fine-tuning 需要訓練模型,很難即時更新資料。
- 資訊正確性:RAG 會參照外部資訊,有效減少虛假訊息,使得回答更加可信、準確。
- 可信任性:RAG 回答可引用資訊來源,讓使用者可以審核答案,透明度高。
- 安全、隱私性較高:RAG 是查找自己向量資料庫的知識,存取權限方面比較容易管控。相較之下,Fine-tuning 的較容易外洩。
不過其實也不是只能選一種,你可以結合其中兩種、甚至三種,來讓模型達到更好、更符合自己的生成結果。
什麼是 LlamaIndex?
LlamaIndex 是一個資料框架,提供了抽象元件,可以更容易、更安全的使用 "資料提取"、"索引"、"查詢" 等功能。
適用於基於 LLM 的應用程序,主要是 RAG 架構 (也就是我們上面介紹的)。
LlamaIndex 支援 Python 和 Typescript,本篇文章會使用 Python 來示範,不過概念上是一樣的。
撰寫程式
需要先安裝 LlamaIndex 套件本身,以及我們要使用的 Gemini (LlamaIndex 已經有包好的介面可用):
* 後來發現 Gemini 的 Embedding 不支援中文…所以改用 OpenAI 的 Embedding,因此最後的程式碼不需要 llama-index-embeddings-gemini,可不用安裝。
| |
LLM 和 Embedding model
在開始建構 RAG 架構之前,我們先來分別試一下 LLM 和 Embedding model 是否都正常。
* Gemini 各種模型介紹與限制,可以看這篇官方的說明頁面:https://ai.google.dev/models/gemini
* 還沒有取得 Gemini API key 的人,可以參考我之前寫的文章:
如何使用 Google 的 Gemini 模型 API?
* Gemini API Key 可以像官方說明設定在環境變數中(GOOGLE_API_KEY),或者我這邊省麻煩直接寫在程式碼裡 (但就要注意不要不小心外洩了)。
首先來試試 Gemini 本身 LLM,基本的 Complete 和 Chat 使用:
* 以下參考官方提供的範例:https://github.com/run-llama/llama_index/blob/main/docs/docs/examples/llm/gemini.ipynb
| |
再來試試 Gemini 的 Embedding,將句子轉換為向量:
| |
沒問題~ 測試都正常。 (← 真的嗎…立旗)
RAG
一開始,先給大家看完整程式碼。
| |
這程式主要的部分是從官方文件來的: Starter Tutorial (OpenAI)
可以看到,其實透過 LlamaIndex 框架來實作 RAG 架構,根本不用幾行程式碼。
而且如果你是使用 OpenAI API,上方 Gemini 的部分甚至可以省略 (它預設是 OpenAI API)。還有中間 else 的部分也可以省略 (只是變成你每次執行都還要再 Embedding),所以實際上所需的程式碼更少。
首先,我們先準備好原始資料,並放到 docs 資料夾內(這名稱是在程式碼內自訂的)。
我就拿我最近在看、而且前陣子很火紅的日本動畫《葬送的芙莉蓮》當範例。
我們去維基百科複製 葬送的芙莉蓮 的內容,並存到 docs 資料夾底下的 frieren.txt。
rag
├ docs
│ └ frieren.txt
│
└ llamaindex_rag.py
| |
如同剛剛說的,LlamaIndex 框架預設的 LLM、Embedding model 都是採用 OpenAI API,如果你想要改變全域的配置,需透過 Settings 對象
。
這邊我原本是打算 LLM 和 Embedding model 都使用 Gemini 的,結果我實際跑起來發覺結果很怪,每次找出來最相近的段落都是那兩個,網路查了才發現,Gemini 的 embedding-001 好像不支援中文……
而且就算我改嘗試前幾天 Google 發布的新一代文字嵌入模型 text-embedding-004,也還是不行。
沒辦法,最後在 Embedding 的部分還是改回使用 OpenAI 的 text-embedding-ada-002,所以也才同時需要 Gemini 和 OpenAI 的 API Key。
* OpenAI 的 API key 申請可以參考我之前的文章 ( OpenAI ChatGPT API 如何使用?(附上 Python 範例程式) ),但因為已經過一年了,實際介面與步驟可能有點不太一樣。
| |
這邊的 if-else 是在第一次執行會去讀取 docs 資料夾下所有的檔案,將內容切割後做 Embedding (轉向量),並把結果儲存下來,避免每次執行都要花時間、花金錢做 Embedding。
第二次之後執行,如果 ./storage 資料夾存在,我們就當已經做過 Embedding,直接從 ./storage 讀取向量資料。
因此如果我們有修改、新增原始資料,需要把 ./storage 資料夾刪除,讓它再重新 Embedding 一次。
| |
從原始資料讀取並轉換成向量之後,我們就可以開始詢問它問題。
例如我問它「動畫《葬送的芙莉蓮》中的芙莉蓮角色是由哪位聲優配音?」,他會回答「種崎敦美」✨。
非常正確~~🎉
結語
以上各個步驟的元件都有很多不同的可以替換,像是 LLM 可以換成 Azure OpenAI、Anthropic 的 Claude 3 Opus、生成超快的 Groq、本地跑 Ollama、甚至自訂 LLM 模型……等等 ( 詳細支援列表 )。還有文件載入方面,也可以連接 PDF、CSV、HTML、Google Docs 等等多種來源。
以上資訊可以在 官方文件 Examples 和 LlamaHub 裡面找到。
學習完最基礎的範例後,各位可以從官方文件的 常見問題 (FAQ) 來針對你感興趣的部分,進一步學習、嘗試。或者先去看看官方文件的 Learn 有針對以上不同的步驟做詳細的說明。
我後來整理一篇「 Query Transformations 技巧幫助 RAG 優化問題,提升檢索效果 」。
有時候我們的問題太廣、太模糊,
導致找不出相關資料,甚至找到錯誤的資料,造成回應結果不靠譜。
有一種做法是將問題先請 LLM 做 “改寫”,再送進去檢索,那就是「查詢轉換 (Query Transformations)」技巧。
如果對於 生成式 AI 有興趣的讀者,記得追蹤『 IT空間 』FB 粉專,才不會錯過最新的發文通知呦~🔔
如果想的太多,就會做的很少
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~