前言
ChatGPT 是由 OpenAI 所開發的一個基於 GPT-3.5 架構的大型語言模型,自從去年底發表到現在依然話題不斷、人氣超高。而在三月初,OpenAI 公開了 ChatGPT 的 API,也就是 gpt-3.5-turbo 模型的 API,讓我們不再被限制只能透過官方網頁使用,並且提供更多可調整的參數選項。
這篇文章就是要一起來了解 ChatGPT API,並實際使用 Python 串接 API (當然有 Python 範例程式碼),帶著大家快速上手。
這兩份官方文件建議可以看看:

API key 申請
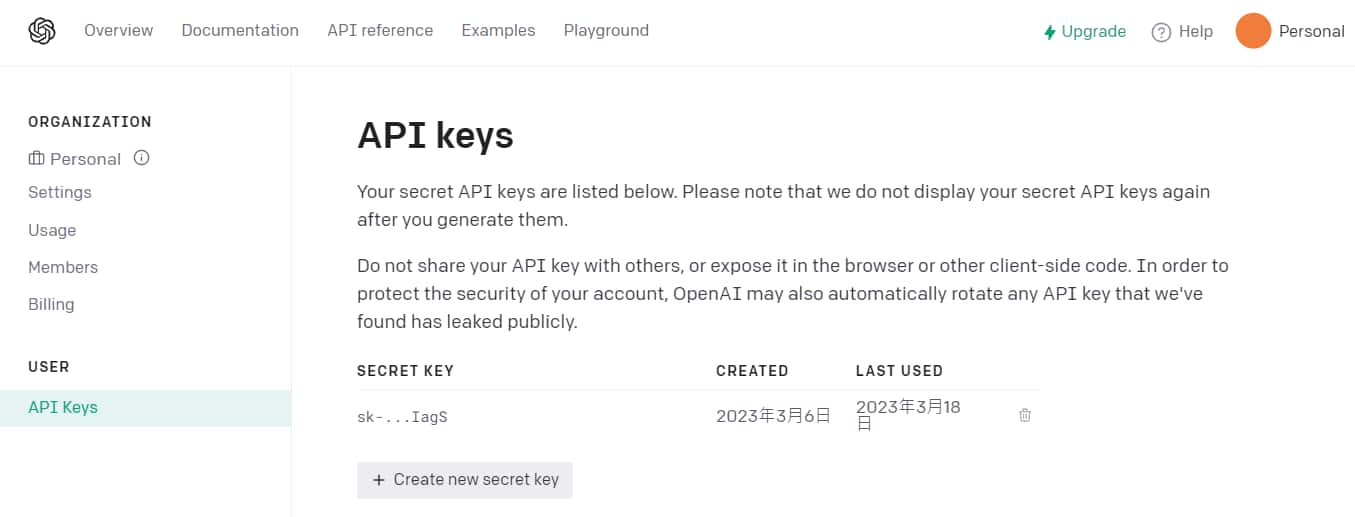
進到帳號的 API key 頁面,登入帳號後,點擊 “Create new secret key” 來產生 API key,這時候就要把 key 複製並保存下來了,如果忘記的話,再產生一次即可。
使用量與計費方式
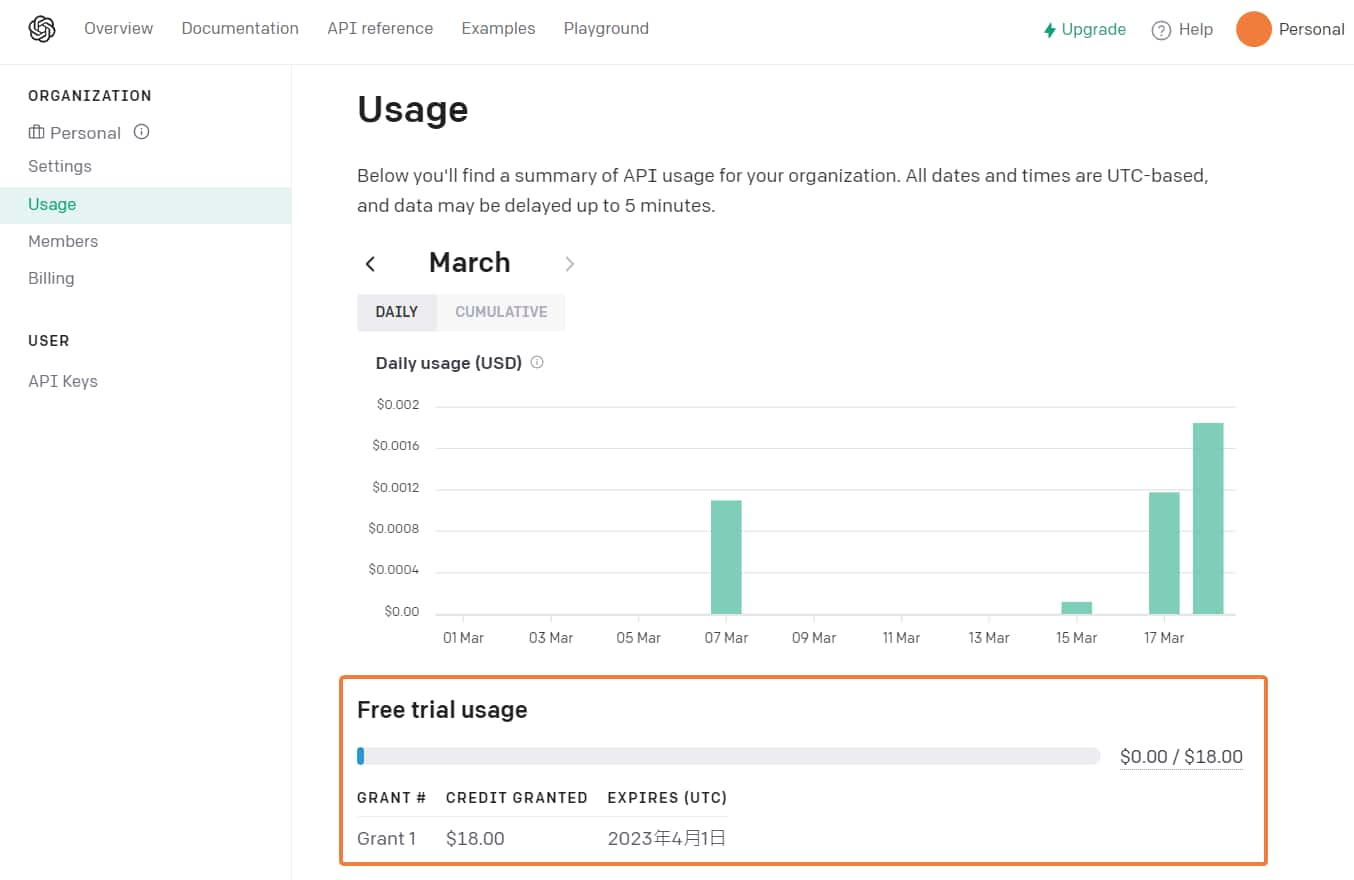
而帳號實際的總使用量可以到 帳號 Usage 頁面查看。
目前每個帳號會贈送 18 美元的額度讓你試用 (如果你是用同一組手機去開多個帳號,那就不一定了),並且有使用期限要留意,不要白白浪費了~
如果免費額度用完過到期,就應該要綁信用卡才能使用了。
每種模型的計費方式可參考 官網 Pricing 頁面說明。
範例程式碼
馬上給各位看看範例程式碼。
這邊分別使用使用兩種套件來示範,我們之前常用的 requests,與官方提供的 openai 套件。
Model 使用 ChatGPT 的 gpt-3.5-turbo,如果之後 GPT-4 的也開放後可以使用 gpt-4。
目前 OpenAI API 有提供
這些 Model
,裡面有對每一種 Model 做詳細說明。
使用 requests 套件
| |
使用官方 openai 套件
| |
參數
輸入參數除了上方範例中的 model 和 messages,還有以下這些。
此表格是依照官方 API Reference 所整理出來的。
| 參數名稱 | 資料型態 | 必填/選填 | 預設值 | 說明 |
|---|---|---|---|---|
model | string | 必填 | - | 要使用的 Model ID。 ( 可使用的model ) |
messages | array | 必填 | - | 以對話格式生成對話的訊息。 ( 格式參考 ,或以下說明) |
temperature | number | 選填 | 1 | 介於 0 和 2 之間。較高的值(如 0.8)將使輸出更加隨機,而較低的值(如 0.2)將使輸出更加集中和確定。 |
top_p | number | 選填 | 1 | 一種替代temperature的方法(nucleus sampling)。Model 考慮具有 top_p 概率質量的標記的結果。所以 0.1 意味著只考慮構成前 10% 概率質量的標記。 |
n | integer | 選填 | 1 | 輸出幾種回覆結果。 (參考以下說明) |
stream | boolean | 選填 | false | 開啟 stream 方式傳送,就像 ChatGPT 網頁版那樣會一個一個字跑出來。( 官方範例 ) |
stop | string or array | 選填 | null | 指定字串,如果回覆有出現這些字串將會停止輸出。 |
max_tokens | integer | 選填 | inf | 聊天完成時生成的最大令牌數。如果太小它可能回覆到一半就會斷掉,但每種 Model 都有各自的最大值。 |
presence_penalty | number | 選填 | 0 | -2.0 和 2.0 之間的數字。正值會根據到目前為止是否出現在文本中來懲罰新標記,從而增加 Model 談論新主題的可能性。 |
frequency_penalty | number | 選填 | 0 | -2.0 和 2.0 之間的數字。正值會根據新標記在文本中的現有頻率對其進行懲罰,從而降低 Model 逐字重複同一行的可能性。 |
logit_bias | map | 選填 | null | 修改指定標記出現在完成中的可能性。 |
user | string | 選填 | - | 代表你的用戶的ID,幫助 OpenAI 監控和檢測濫用行為。 ( 更多說明 ) |
* 官方建議不要同時更改 temperature 和 top_p,可以參考 這邊的說明 。
* 表格內有幾個說明你可能看不懂,因為我也不太懂 XP
messages 是個陣列的格式,放著你們之間的對話。
裡面的 role 欄位可以放三種身分:“system”、“user”、“assistant”。
對話可以先有一則 “system”,對 Model 先做出指示,例如 “你是一隻貓” (?,不過官方說 gpt-3.5-turbo 對 “system” 消息的關注度不高,因此重要的說明建議還是放在 “user” 的消息比較好。
“user” 是我們使用者的發問;“assistant” 則是 Model 的回話。
如果你想要讓對話有上下文關係(要讓 Model 記得之前講過的話),要把全部對話紀錄都在傳給它,然後這些都算進 token(使用量) 裡…,像是底下這樣。
第一次問它:
| |
它回覆:
| |
想再繼續深入詢問,第二次問它,就要把剛剛我問的跟他回的都放進去:
| |
它回覆:
| |
可以感受到 total_tokens 的使用量了嗎?
如果想讓它記得以前講過的話,每次請求所消耗的 token 是要繼續往上疊的,也是蠻恐怖的 XD
以上內容可以參考 官方說明 。
參數 n 是代表你想要它給出幾種回覆,例如 n=3 會產生如下三則訊息回覆:
| |
回覆內容
依照上方的範例程式,他回傳的格式與內容會類似這樣:
| |
usage 欄位顯示你本次消耗的 token 數量。
prompt_tokens:你問他(輸入)所消耗的 token。completion_tokens:它回覆(輸出)所消耗的 token。total_tokens:本次請求總共消耗多少 token,也就是prompt_tokens加completion_tokens。
如果想知道一句話代表幾個 token,可以使用官方提供的 Python 套件 — tiktoken:https://github.com/openai/tiktoken
也有計算 token 相關的
使用說明
。
本來想說可以使用官方的 Tokenizer 網頁 來計算,但它是 GPT-3 Model 的,官方有說轉換 token 的計算方式可能因不同 Model 而異,因此我實際使用其實跟 gpt-3.5-turbo 出來的結果有落差。
帳號實際的總使用量可以到 帳號 Usage 頁面查看。
* 你會發現中文消耗的 token 比英文還多很多😭
choices 內就是主要我們想知道的部分 — ChatGPT 的回覆。
message>content:回覆的內容。index:代表第幾種回覆。(如果輸入參數有設定n的話)finish_reason:代表此次回覆結束的原因(狀態),可能會有以下四種值:stop:完整的輸出。length:由於 max_tokens 參數或 token 限制,導致輸出不完整。content_filter:由於內容過濾器中的標誌而省略了內容。null:API 響應仍在進行中或未完成。
Playground 遊樂場
OpenAI 還有提供 Playground 遊樂場,可以在上面測試不同的模型、調整不同的參數,觀察其結果,方便我們去快速了解。
Playground 遊樂場:https://platform.openai.com/playground
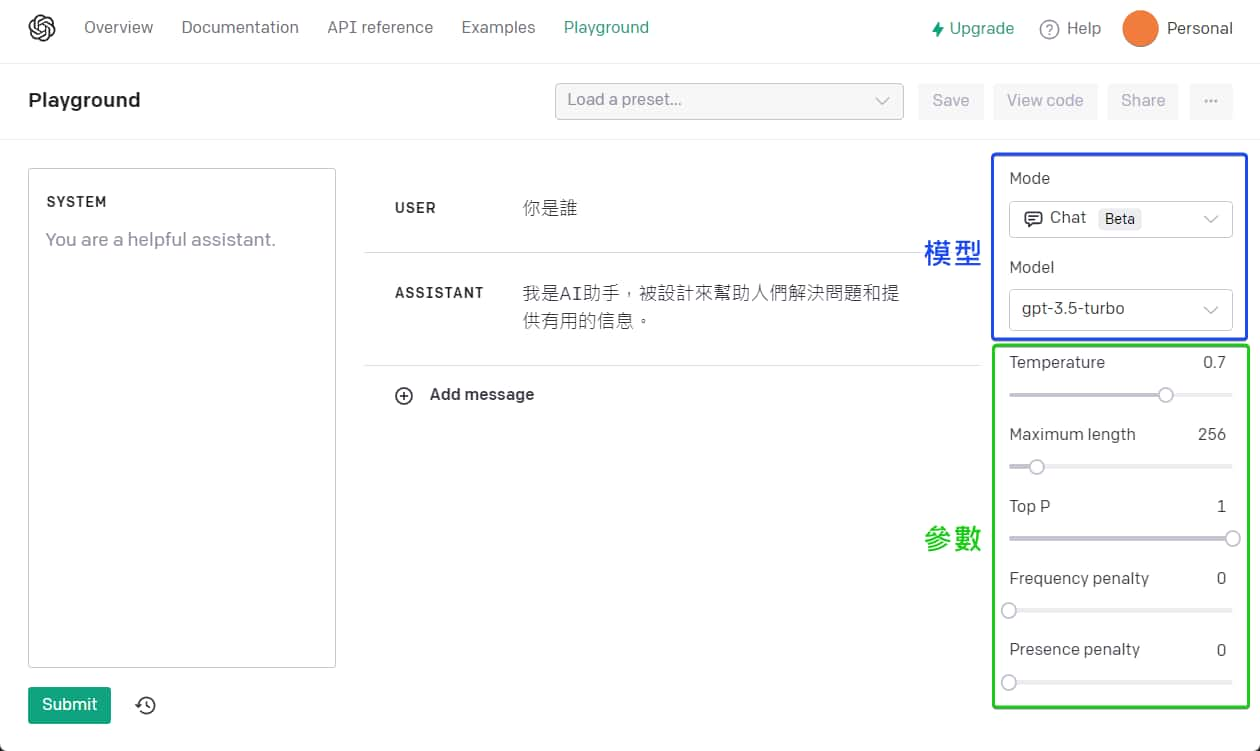
對了,使用 Playground 也是會消耗你自己的 token,這點要稍微注意一下,不要以為是 ChatGPT 網頁而玩過頭了🤣
其他說明
串接 OpenAI API 發出請求可能會收到錯誤,而完整詳細的錯誤代碼說明與進一步的解決辦法,可以參考這邊官方的文章:https://platform.openai.com/docs/guides/error-codes
OpenAI API 在使用上還有一些速率限制,如果使用會比較大量的朋友可以過去了解一下:https://platform.openai.com/docs/guides/rate-limits/overview
結語
使用 OpenAI API 上非常簡單,只是有些小地方要注意一下。
在看完以上介紹,趕快實際動手做,看看有沒有什麼 idea 可以進一步放大 ChatGPT 的用途~
歡迎追蹤『 IT空間 』FB 粉專,取得最新發文通知🔔
參考:
OpenAI 官方說明文件
OpenAI 官方 API 參考
OpenAI 帳號後台
OpenAI 各種 Model 說明
OpenAI 各種 Model 價格
OpenAI Playground 遊樂場
OpenAI API 錯誤代碼
OpenAI API 速率限制
別讓沒有夢想的人摧毀你的夢想。
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~