前言
Omnimatte 是由 Google 與牛津大學的研究人員共同研究,並在去年(2021年)所發表的一項技術,是用於自動將影片中主體與背景分離,也就是類似俗稱的「去背」。
最厲害的點在於,包含主體相關的細節他都可以抓出來,像是陰影、反射和煙霧等等。

以下是我找了官方論文、部落格、影片,以及其他網站所介紹的文章、影片,所整理出來的說明,我對 AI 還很粗淺,如有眼尖的網友發現錯誤,歡迎留言跟我說~
Omnimatte 的效果
先來看這段影片範例,最左邊是原始輸入影片,第二張是使用像是 Mask R-CNN 這類自動產生遮罩 AI 所輸出的遮罩結果,可以看到目前的電腦視覺技術,已經可以自動產生像這樣的遮罩,用來去除影像背景,或合成景深、合成影像。
但從這個遮罩結果會發現一個問題,就是與主體相關的細節,像是陰影、反射和煙霧,通常會被演算法忽略。如果我們想把主體從影片中剔除,會造成主體的陰影或反射仍然存在的錯誤。
了解了目前的問題後,我們來看看 Omnimatte 處理的效果如何(中間那張)。
有沒有非常神奇?它可以將主體包含影子也一起摳出來,(最右邊)從影片中完完全全地去除,而且影子投射在椅子上的部份也去除了,只看這個片段完全不知道原始影片還有個人走過。
再來另一個例子。
這是從上方的角度拍攝,有一台車在甩尾並產生煙霧,Omnimatte 除了將煙霧抓出來外,明顯看出輸出的遮罩是有透明度上的變化。

這樣我們可以做什麼應用?我們可以在主體與背景間插入文字,這也可以很明顯地看出提取煙霧確實包含透明度。
關於這類從影片中生成遮罩的分割網絡,我們可以簡單分成三個等級。
第一級,只能抓出主體本身,就像 Mask R-CNN 這樣。
第二級,包含主體的影子、反射,並自動將其與主體關聯起來,人與人的影子、狗與狗的影子。
第三級,當被遮擋還會自動修復,注意看下圖,當狗擋住人的影子時,在輸出還是能預測出大致上正確的樣子。
接下來,我們稍微說明這項神奇的技術。
Omnimatte 架構與例子
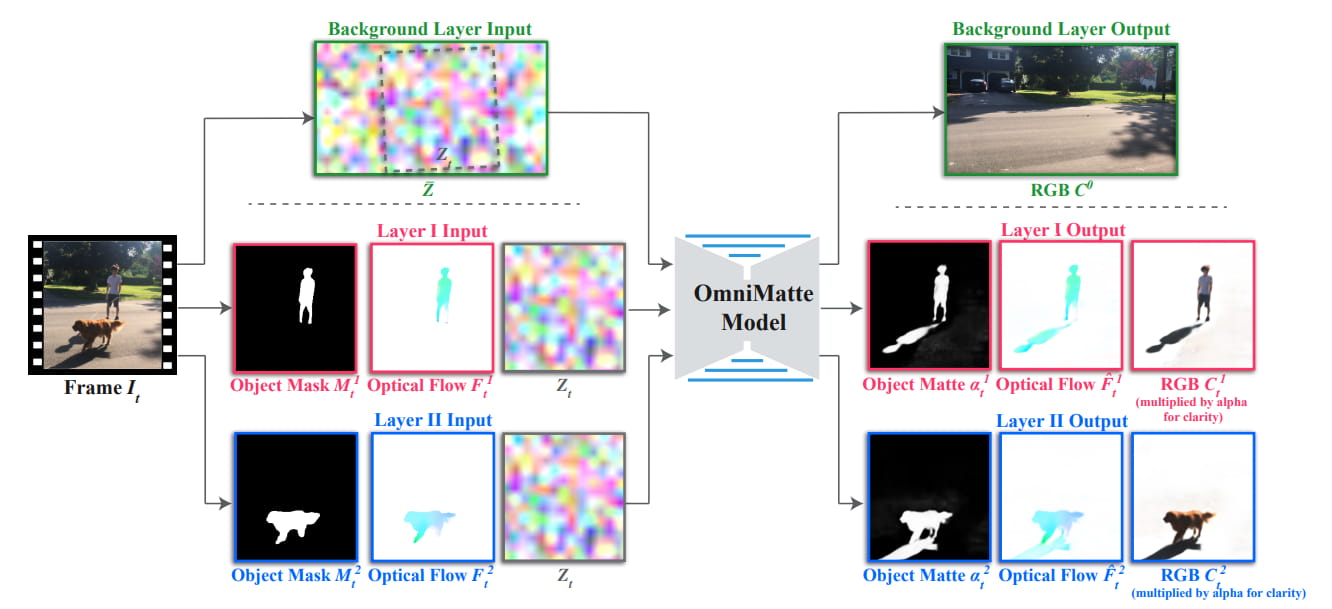
這是 Omnimatte 簡單的流程,主要模型是一個 2D U-Net 的 CNN 架構。
首先使用現成的分割網絡 (Mask R-CNN) 提取每個對象的分割遮罩,及使用 STM 跨幀跟踪對象當輸入,讓遮罩可以更好的適配主體。
假設背景完全是靜態的,主體會有明顯的移動、變化,不過可能因為相機曝光的變化或光線的角度什麼的,使得背景會有些微的變化,為了避免這些變化影響到我們把主體提取出來,會先計算出這些背景噪點,讓 model 在學習時把它過濾掉,而這部分噪點的算法是有參考另一篇論文的方式去計算的。
這個模型針對個別影片進行訓練,只需要輸入原始影片即可,不需要觀察任何其他例子,也不需要任何標籤,在這種情況下,以自我監督的方式進行訓練去重建輸入影片。
為了讓結果更好、細部的優化,除了這個基本的處理外,還有使用 RAFT 計算連續幀之間的光流,這是為了追蹤主體跨幀的移動,避免某些幀可能發生破圖等等小問題。
因為 CNN 的特性,能夠良好地學習主體和相關特效之間的關聯性,兩者的相關性越強,CNN 就越容易學習,
像是在路上行走的人與狗,人和人的影子,以及狗和狗的影子之間的空間關係,都是從右向左移動,不過人與狗的影子比較不像、狗與人的影子比較不像,關係變化更大,因此相關性也就相對較弱,CNN 會先學習較強的相關性。就是說人的影子與人在形狀、運動上更相似,因此能獲得正確的分解結果。
我們來看更多其他例子,從中可以觀察到幾個重點:
球拍不包括在原本的輸入遮罩中,卻還是被順利抓出來。

黑天鵝的反射和牠引起的水波紋也可以。

大象噴出的半透明塵埃及陰影。

這個跟"人與狗"的那個影片類似,也是有兩個主體,分別為足球以及踢球的人。但注意人在踢到足球的時候,兩者物體是貼在一起,不過還是有成功地將人的影子與足球的影子分離。

而這個場景的挑戰在於:
- 下方兩位人都以相同的速度一致地移動。
- 玻璃上的反射與人在空間上的接近程度。
這例子算是一個失敗的結果,雖然陰影與人有正確關聯,但右上角的人投射在玻璃上的反射錯誤地與左下角的人分組,因為玻璃中的反射比較接近下方的人。

現有技術比較
我們來看看,現行有哪些方法可以達成類似的效果。
FGVC 影片補全演算法
FGVC (Flow-edge Guided Video Completion) 是 Facebook 發表的影片補全演算法。
在紅鶴的例子中,如果 FGVC 輸入的遮罩沒有包含倒影,那結果水中的倒影就會被保留下來,相反 Omnimatte 就完美的去除主體包括倒影的部分。
而下方跳舞的範例,在將舞者移除後,FGVC 存在著鬼影,而 Omnimatte 就比較自然。

參考資料:
* Flow-edge Guided Video Completion | 官網
* Flow-edge Guided Video Completion | Paper
* Flow-edge Guided Video Completion | GitHub
陰影檢測
使用陰影檢測,看它能不能完整的抓出主體和陰影。
ISD (Instance Shadow Detection) 是 2020 年發表的基於深度學習的圖像陰影檢測方法,可以看到當影子投射在其他物體上時,ISD 很可能就檢測不出來,或是像下圖,當人的影子被狗擋到時,人和其影子也可能抓不到。

這邊可以直接看影片,會發現 ISD 某幾幀會 miss 掉,Omnimatte 從頭到尾都很順的都有抓到。
參考資料:
* Instance Shadow Detection | Paper
* Instance Shadow Detection | GitHub
背景減法
下一種是使用背景減法,首先就有一個很明顯的缺點,就是它叫背景減法,表示它需要已知且乾淨的背景影像,再來研究人員說它對閾值非常敏感,更重要的是,當影片中有多個具有效果的對象時,它沒辦法把主體跟其效果關聯在一起。
分層神經渲染
最後是跟"分層神經渲染" (Layered Neural Rendering for Retiming People in Video) 做比較,這也是 Google 跟牛津大學的研究(其實跟 Omnimatte 是同位作者🤣),是在 2020 年發表的。
兩者都成功捕捉變形、陰影和反射,但 Omnimatte 輸入更通用、簡單遮罩,分層神經渲染還需要先計算 UV 貼圖,而且這邊可以看到,有些背景也被捕捉進來。
參考資料:
* Layered Neural Rendering for Retiming People in Video | 官網
* Layered Neural Rendering for Retiming People in Video | Paper
* Layered Neural Rendering in PyTorch | GitHub
延伸應用
這項技術感覺這麼有趣,我們來看看他有那些延伸應用。
第一個最容易的是換背景,或者也可以說主體去背。它厲害在於還可以包括陰影等相關效果。
但右邊合成結果主體和背景光線、色調會有些不同,要比較好的成果要再做細部的調整。
接下來是頻閃攝影,又稱連閃攝影。
它的做法是在一個快門內,藉助於閃光燈的連續閃光,在一個畫面上記錄動體的連續運動過程,那因為需要多次曝光,所以需要在很暗的環境,可以看到物體的運動軌跡。
Omnimatte 應用的結果就有點類似這種頻閃攝影,只是它是動態影片版。

最後這個影片重新定時,我覺得非常有趣,而且在實際生活上也比較可能常拿來應用。
前面提到 Omnimatte 能將影片中的主題獨立分出來,也就是一個影片內的物體可以擁有不同時間軸,像這影片內有三位小朋友,我們就可以得到三個圖層。在原始的影片中,每位小朋友跳入水裡的時間不同,但是透過調整三個圖層之間播放的時間軸,就能夠讓三位小朋友同時跳入水中,並且還包含水花和反射等效果。
這項特效常被應用在電影上,但是傳統的作法必須在受控的環境中,為每個單獨的主體拍攝影片。那借助Omnimatte後,即便日常的影片,都能夠簡單地操縱物體時間軸,你想讓某一個主體暫停,或改變播放速度都可以。有另外一篇論文,也是 Google 和牛津大學的研究論文,有更詳細的說明這個部分。


* 這兩段圖片來源:https://retiming.github.io/
限制
當然,在目前研究的結果上,研究人員還是有說明一些限制。
- 第一,目前只能用來處理畫面固定不動,或小幅移動的影片,不然可能無法精確地捕捉整個背景,造成部分背景元素可能還原會有問題。
- 第二,CNN 在學習相關性上雖然非常強大,但是部分時候產生的結果不如預期,且研究人員也說還無法切確掌握原因。
- 再來,無法分離相對於背景完全靜止的主體及特效,目前這個模型需要主體有移動,才能將其與背景分離。
- 最後,這項技術可能遭到濫用,即便重新排列的影片中已經存在的內容,但是只要簡單地調整影片內容的順序,就可以被用來產生虛假和誤導性訊息。
結語
雖然這項技術還沒有實際應用,處於研究階段,但這個是 Google 正在研發的技術,或許不久的將來會在 Pixel 手機上看到也說不定呢~
如果有興趣等不及了,想要自己動手做,可以參考官方提供的 GitHub:https://github.com/erikalu/omnimatte
參考:
Introducing Omnimattes: A New Approach to Matte Generation using Layered Neural Rendering | Google AI Blog
Omnimatte: Associating Objects and Their Effects in Video
Omnimatte: Associating Objects and Their Effects in Video | Paper
Omnimatte: Associating Objects and Their Effects in Video (CVPR 2021 Oral)
This Magical AI Cuts People Out Of Your Videos! | Two Minute Papers
Google以分層神經渲染生成遮罩,可個別操縱影片中物體時間軸 | iThome
任何缺陷弱點,只要好好打磨,便能成為武器。
—— 《暗殺教室》
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~