前言
Python網路爬蟲實例系列 已經進入第六篇了,我們要試著來抓取「NOWnews今日新聞」的 即時新聞列表 ,而透過底下說明可以發現它有使用 Ajax 動態載入,我們也可以更容易地取得資料。文末有附上完整程式碼供參考。
備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任
套件
此次 Python 爬蟲主要使用到的套件:
安裝
| |
流程
首先進入 NOWnews 今日新聞的 即時新聞列表 網頁,來觀察看看其新聞列表載入方式。
打開瀏覽器的 開發人員工具 (F12 或 Ctrl + Shift + i),可能一開始會先透過"Elements"找網頁節點元素,馬上就開始寫爬蟲程式了。
但是等等,這樣除了要解析網頁,他頁面上有三種版型,還要各自分開解析,或許我們可以再花點時間觀察觀察。
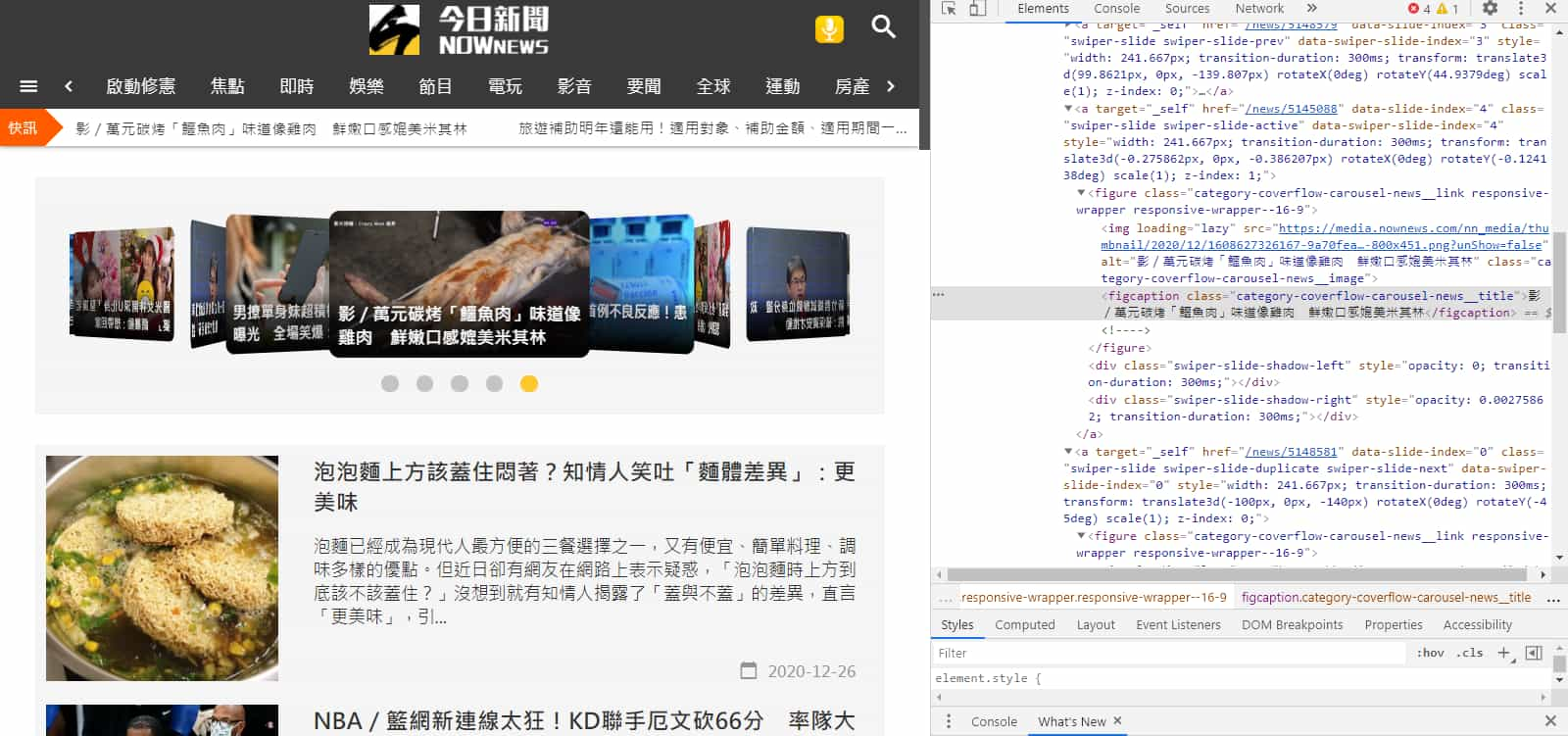

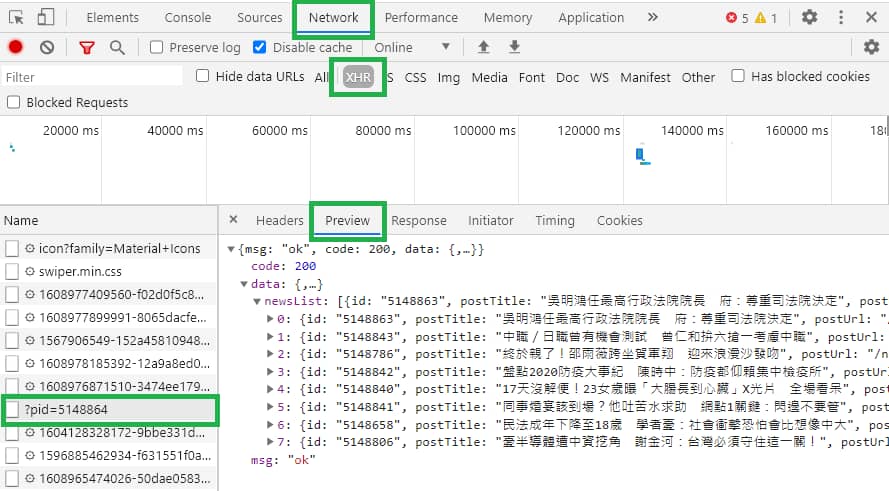
開發人員工具切換到"Network" > "XHR",當我們點擊「看更多新聞」按鈕時,會發現有送出一個請求,單點選它打開之後,右邊選擇 Preview 分頁看一下其中的資料。
水啦~~~就是我們希望取得的新聞列表。
切換回 Headers 分頁,看一下此資料請求方式與網址。
使用"GET"的方式,網址為 https://www.nownews.com/nn-client/api/v1/cat/breaking/。
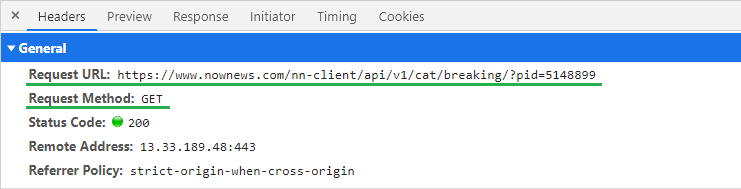
ㄟ?! 那網址後方的參數 pid=5148899 代表什麼呢?
打開開發人員工具內的搜尋(Ctrl+F),觀察一下發現,原來是代表前一次資料中的最後一篇新聞ID啊~
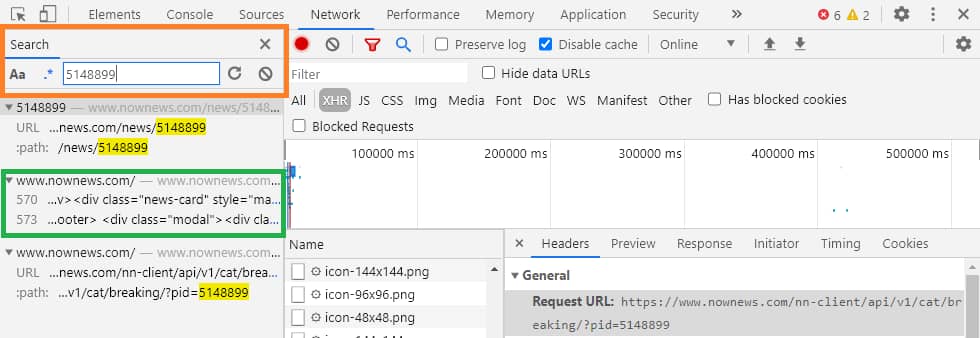
可以將網址貼到瀏覽器的網址欄位中,查看回傳的資料。
OK
大致上原理與流程我們知道了,來開始將其轉換成 Python 程式碼吧!

爬蟲程式
先設定兩個變數,all_news 之後要裝抓取的新聞資料;pid 是記錄每頁最後一筆新聞的ID (為了請求下一頁)。
| |
這邊使用 while 迴圈,num 代表我們想爬取的新聞數量,當數量還不到時,就繼續抓取。
請求的網址 url 後方記得帶上 pid 參數。第一頁只要空著就行,之後開始才需要給值。
| |
我們先觀察之前取得的回傳資料:
* 為了方便觀察,我這邊使用 JSON Editor Online 線上工具來輔助演示。

| 參數 | 代表意思 | 格式 |
|---|---|---|
| id | ID | 文字 |
| postTitle | 標題 | 文字 |
| postUrl | 網址(包含請求分類) | 文字 |
| postOnlyUrl | 網址(不包含請求分類) | 文字 |
| sort | 排序 | 數字 |
| postContent | 內容摘要 | 文字 |
| imageUrl | 圖片網址 | 數字 |
| newsDate | 發布日期 | 數字 |
回傳資料是 JSON 格式,直接使用 requests 提供的 r.json() 轉換。
新聞列表資料是放在 data > newsList 中,並取得我們想要的欄位。
| |
下一頁網址後方參數 pid,就是這次的最後一筆新聞ID。
每次請求之間加入一小段延遲,避免太頻繁爬取,造成對方伺服器負擔。
| |
完整程式碼
附上完整程式碼:
nownews_spider.py
(對超連結右鍵 > 另存連結為)
延伸練習
- 試著抓取不同分類裡的新聞列表,例如:
NOW電玩裡的最新新聞
。
提示:雖然它看似採用"下一頁"的方式,但你實際點擊不同頁數時,發現到網址並無任何變化,或許它也是使用 Ajax 動態載入資料的方式呢~
結語
整體來說,NOWnews今日新聞的爬取方法與聯合新聞網蠻類似的,可以前往我之前寫的 教學文 參考。
我會陸續慢慢寫一些網站的 Python網路爬蟲實例 ,如果你正好是剛開始想學爬蟲的新手、想知道某個網站如何爬取資料,又或遇到其他問題,歡迎參考與在底下留言喔~🔖
人生沒有最好的決定,只有在決定之後做到最好。
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~