前言
之前某天在社團看到網友詢問 591 租屋網的網路爬蟲,因此才有這篇文章的誕生,距離 Python網路爬蟲實例 系列 上一篇文章已經隔了半年了呢 (好久~
這次要來分別說明 591 租屋網的 "搜尋房屋" 與 "取得房屋詳情" 兩個請求,以及如何發出請求、取得回傳數據資料。
經網友提醒網站有改版,這篇文章的方法已過時,我雖然有再嘗試找出發請求的網址,但發現回傳資料有加密過的,要解開的話還要從它的 JS 程式中尋找 KEY 值,因為太麻煩就沒繼續研究了。
不過後來我還有寫一篇 591 房屋交易「新建案」的搜尋與房屋詳情,有需要的讀者也可以過去逛逛:[Python爬蟲實例] 591 房屋交易 -「新建案」搜尋與房屋詳情

備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任。
套件
此次 Python 爬蟲主要使用到的套件:
安裝
| |
搜尋房屋
首先到「 591 租屋網 」的搜尋頁面,我們想可以給不同篩選條件,並取得底下結果的房屋資訊。
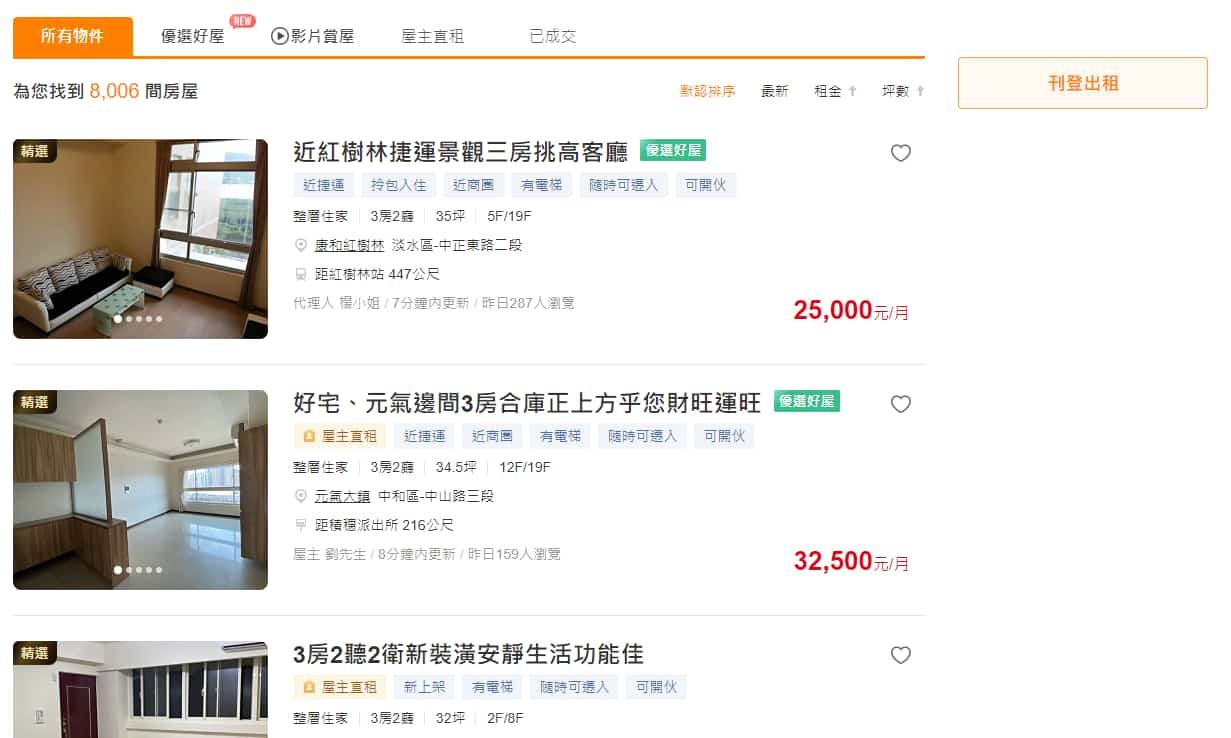
請求路徑與參數
打開瀏覽器的 開發人員工具 (F12 或 Ctrl + Shift + i) > Network 分頁,在 "Fetch/XHR" 分類中找找看哪個是搜尋房屋結果的請求。
稍微比對後,即可確定是 https://rent.591.com.tw/home/search/rsList 這個請求。
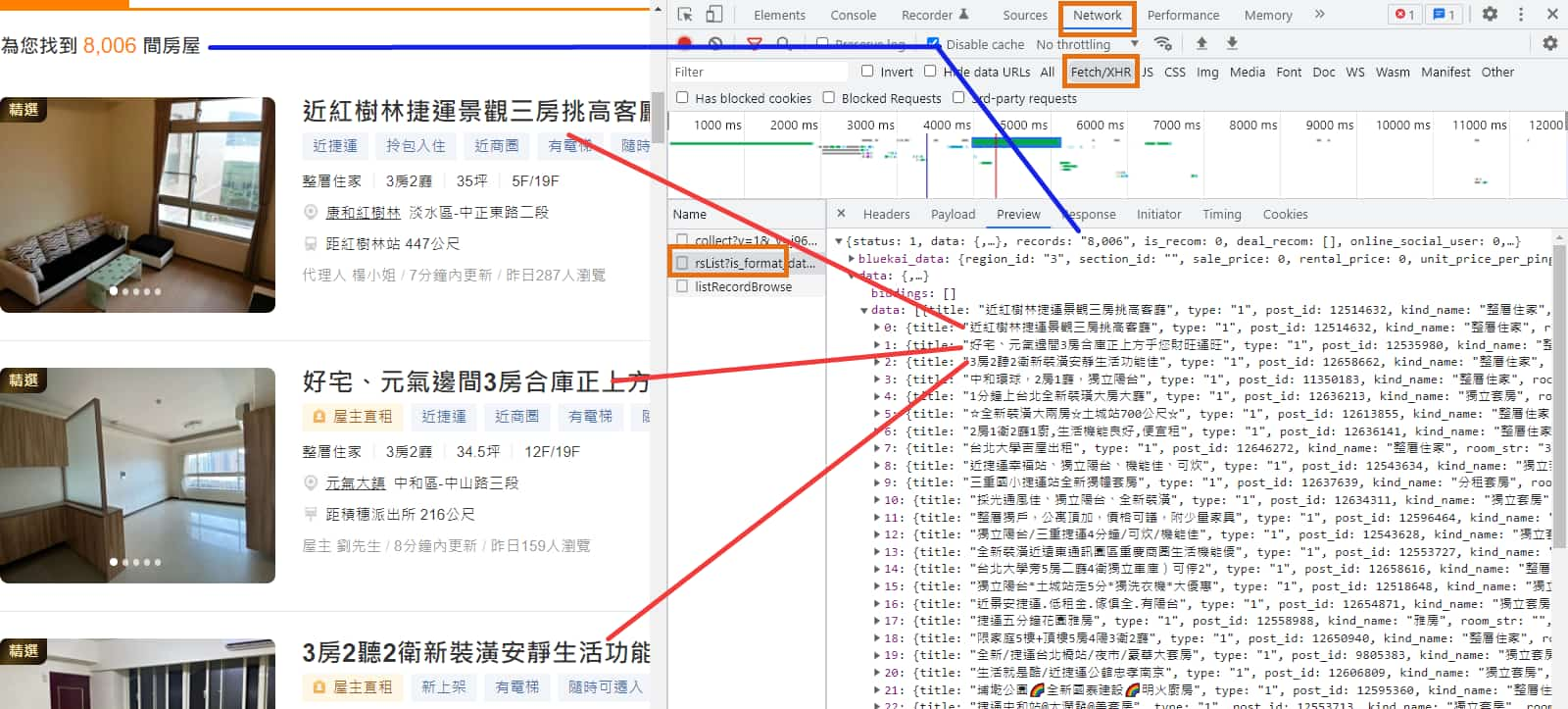
但透過 Python 的 requests 直接發送 https://rent.591.com.tw/home/search/rsList?is_format_data=1&is_new_list=1&type=1®ion=3 請求,卻會收到失敗的訊息。
HTTP 狀態碼 (HTTP Status Code) 為 419,網頁內容顯示 "The page has expired due to inactivity.",推測可能是我們缺少哪些必要參數。
經過我的測試,發現它需要代上 Cookie 與 X-CSRF-TOKEN 這兩個必要參數,才能夠順利取得資料。
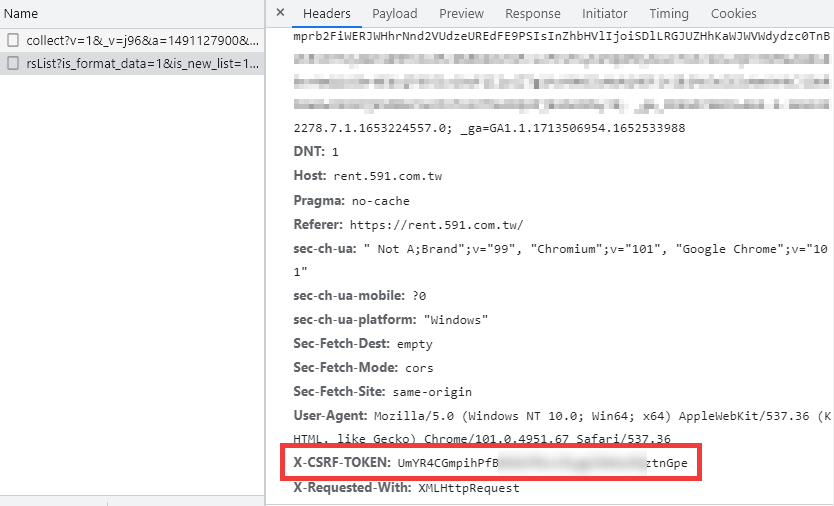
可以直接在 開發人員工具 > Network 搜尋(Ctrl+F)來尋找這個值是從何來。
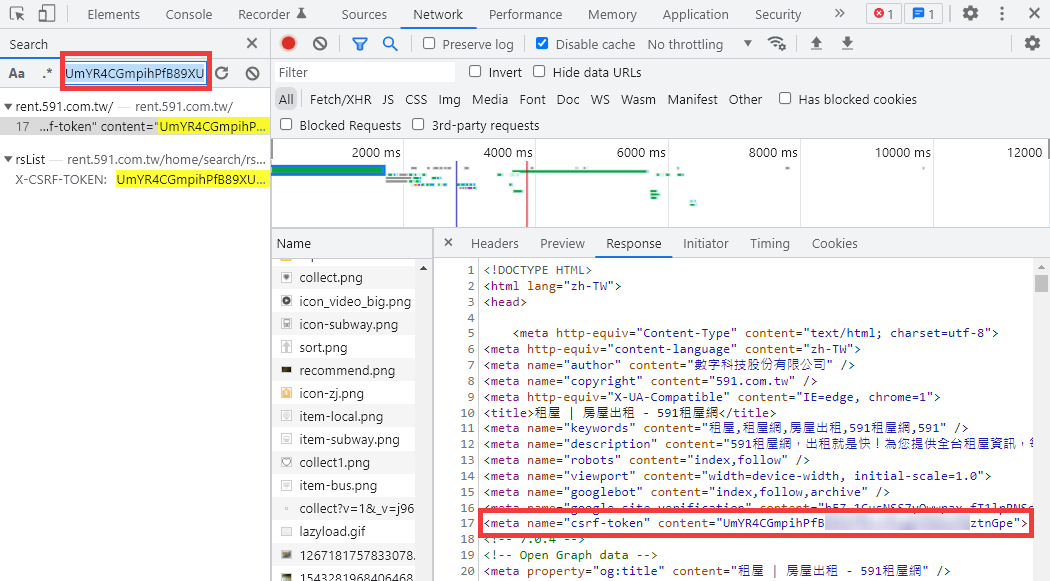
在 https://rent.591.com.tw/ 的 <meta name="csrf-token"> 裡能找到此字串。
另外 Cookie 也是請求此網址後可取得。
因此在我們實際要搜尋房屋資料前,要先請求 https://rent.591.com.tw/ 將 Cookie 與 X-CSRF-TOKEN 這兩個參數字串準備好。
另外,
我們可以透過帶入不同的搜尋參數值,來達到對結果做不同的篩選。

以下我將其全部羅列出來,但第一項 "位置" 有太多種類,就不一一呈現,可以自己選擇後再從 開發人員工具 查看。
* 以下某些選項在網頁上是可以多選的,則參數的數值用逗號 , 隔開即可。
* 如 multiArea=10_20,20_30 坪數 10-20坪 和 20-30坪。
房屋類型
| 類型 | kind: |
|---|---|
| 不限 | 0 |
| 整層住家 | 1 |
| 獨立套房 | 2 |
| 分租套房 | 3 |
| 雅房 | 4 |
| 車位 | 8 |
| 其他 | 24 |
租金
| 租金 | multiPrice: |
|---|---|
| 5000元以下 | 0_5000 |
| 5000-10000元 | 5000_10000 |
| 10000-20000元 | 10000_20000 |
| 20000-30000元 | 20000_30000 |
| 30000-40000元 | 30000_40000 |
| 40000元以上 | 40000_ |
* 如果要自訂租金範圍,改用 rentprice 參數(如 "3000~6000元" 要用 rentprice=3000,6000)。
格局
| 格局 | multiRoom: |
|---|---|
| 1房 | 1 |
| 2房 | 2 |
| 3房 | 3 |
| 4房以上 | 4 |
特色
| 特色 | other: |
|---|---|
| 新上架 | newPost |
| 近捷運 | near_subway |
| 可養寵物 | pet |
| 可開伙 | cook |
| 有車位 | cartplace |
| 有電梯 | lift |
| 有陽台 | balcony_1 |
| 可短期租賃 | lease |
而以下選項在網頁中需要點擊展開,觀察它 API 再加入以下選項時,還多附加 showMore=1 參數,但實測貌似沒有影響(?),但建議還是加上比較保險。
型態
| 型態 | shape: |
|---|---|
| 公寓 | 1 |
| 電梯大樓 | 2 |
| 透天厝 | 3 |
| 別墅 | 4 |
坪數
| 坪數 | multiArea: |
|---|---|
| 10坪以下 | 0_10 |
| 10-20坪 | 10_20 |
| 20-30坪 | 20_30 |
| 30-40坪 | 30_40 |
| 40-50坪 | 40_50 |
| 50坪以上 | 50_ |
* 如果要自訂坪數範圍,改用 area 參數(如 "20~50坪" 要用 area=20,50)。
樓層
| 樓層 | multiFloor: |
|---|---|
| 1層 | 0_1 |
| 2-6層 | 2_6 |
| 6-12層 | 6_12 |
| 12層以上 | 12_ |
設備
| 設備 | option: |
|---|---|
| 有冷氣 | cold |
| 有洗衣機 | washer |
| 有冰箱 | icebox |
| 有熱水器 | hotwater |
| 有天然瓦斯 | naturalgas |
| 有網路 | broadband |
| 床 | bed |
須知
| 須知 | multiNotice: |
|---|---|
| 男女皆可 | all_sex |
| 限男生 | boy |
| 限女生 | girl |
| 排除頂樓加蓋 | not_cover |
* 要注意,不同 "類型" 的房屋,可附加的篩選條件有些不同,可以實際在網頁先點選嘗試。
排序
還有可通過帶入不同的排序參數,來對搜尋結果房屋作排序。
| 排序依據 | order: |
|---|---|
| 發佈時間 | posttime |
| 租金 | money |
| 坪數 | area |
| 排序順序 | orderType: |
|---|---|
| 由小到大 | asc |
| 由大到小 | desc |
換頁
而一次請求只會傳回 30 筆資料,就等同於網頁顯示"一頁"的資料,我們可以試著在瀏覽器切換不同頁數,觀察請求的網址變化:
第 1 頁https://rent.591.com.tw/home/search/rsList?is_format_data=1&is_new_list=1&type=1&
第 2 頁https://rent.591.com.tw/home/search/rsList?is_format_data=1&is_new_list=1&type=1&firstRow=30&totalRows=11227
第 3 頁https://rent.591.com.tw/home/search/rsList?is_format_data=1&is_new_list=1&type=1&firstRow=60&totalRows=11227
第 10 頁https://rent.591.com.tw/home/search/rsList?is_format_data=1&is_new_list=1&type=1&firstRow=270&totalRows=11227
最後的 totalRows 是代表此條件的搜尋結果總筆數,但經過我的嘗試,貌似有沒有帶此參數,並不影響結果。
重點是在 firstRow 參數,代表要從第幾筆資料開始取得,這跟我們以前在其他文章提過的 offset 概念類似。
(可參考我之前整理的 (圖解) 網路爬蟲 API 常見的 3 種「翻頁」方式 文章)
firstRow=0 -> 代表第 1 頁;firstRow=30 -> 代表第 2 頁;firstRow=60 -> 代表第 3 頁;
再補充一點,在以 "鄉鎮" 為條件搜尋時,需要在 cookie 內加入一個參數,否則搜尋出來會沒有結果。'urlJumpIp', '17', domain='.591.com.tw', path='/'
這是經網友留言提問,另一位熱心網由找到解答並回覆,我稍微調整一下寫法,使其加入範例程式碼內。
回傳資料
回傳資料會有此條件搜尋出來的房屋總筆數(records),以及房屋基本資訊(data > data),而房屋基本資訊會有像是 "標題"、"價格"、"圖片"、"房屋類型"、"樓層"、"地區"、"標籤"……等等,大致上就是你在網頁可以看到的那些資訊。
回覆資料範例: house591_search.json (搜尋房屋)
範例程式
使用 Python 撰寫 "搜尋房屋" 的寫法如下,完整程式碼請至文末參考:
| |
取得房屋詳情
"取得房屋詳情" 是指從搜尋頁面選一間房屋後點進來,所呈現關於此房屋的詳細資訊。
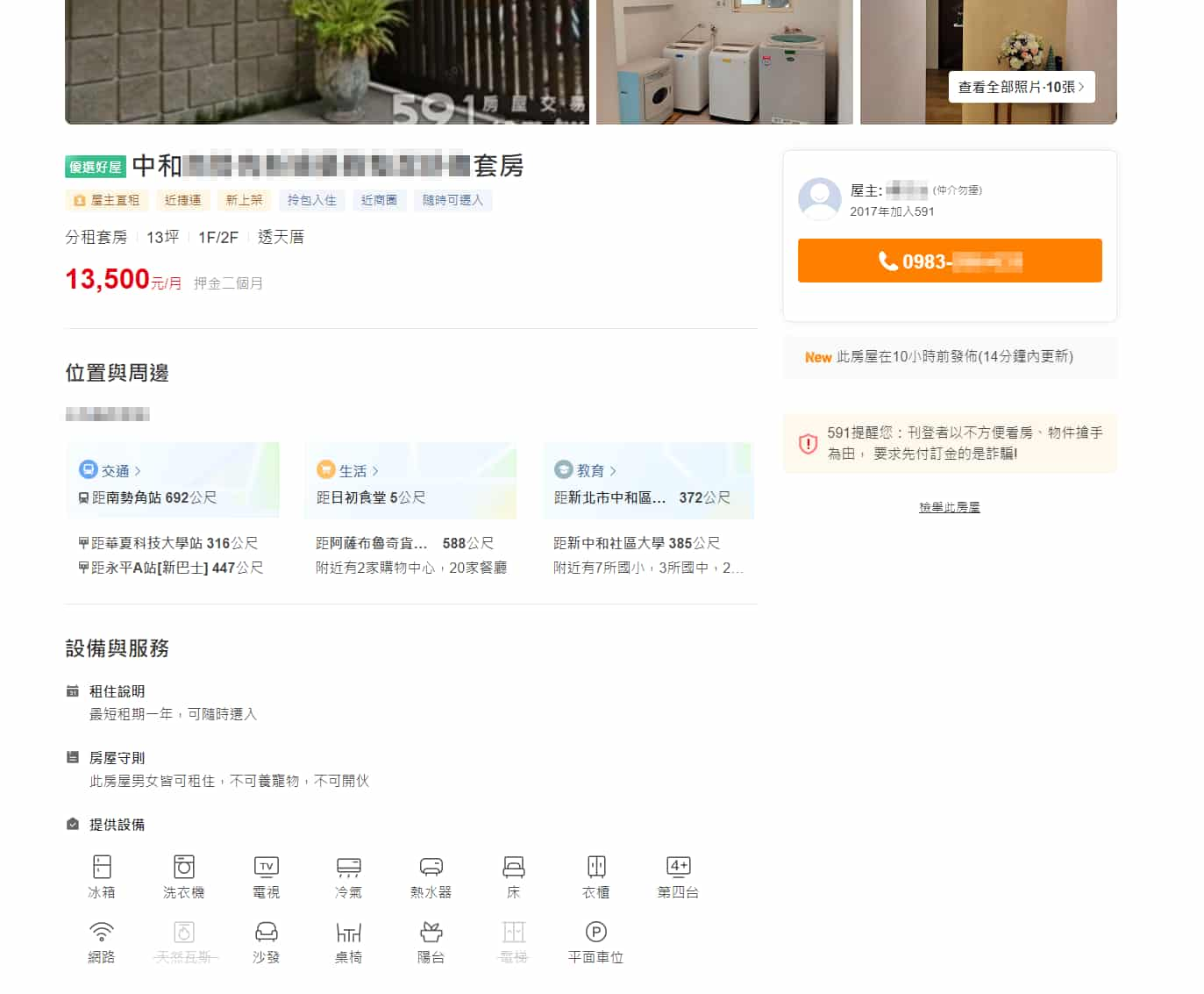
請求路徑與參數
一樣打開瀏覽器的 開發人員工具 (F12 或 Ctrl + Shift + i) > Network 分頁,在 "Fetch/XHR" 分類中就可以找到是哪個請求。
經過比對,確認是 https://bff.591.com.tw/v1/house/rent/detail?id=1254xxxx 請求,網址後方也可以發現是代表此房屋的 ID,也等同於目前瀏覽器網址後方的數字。
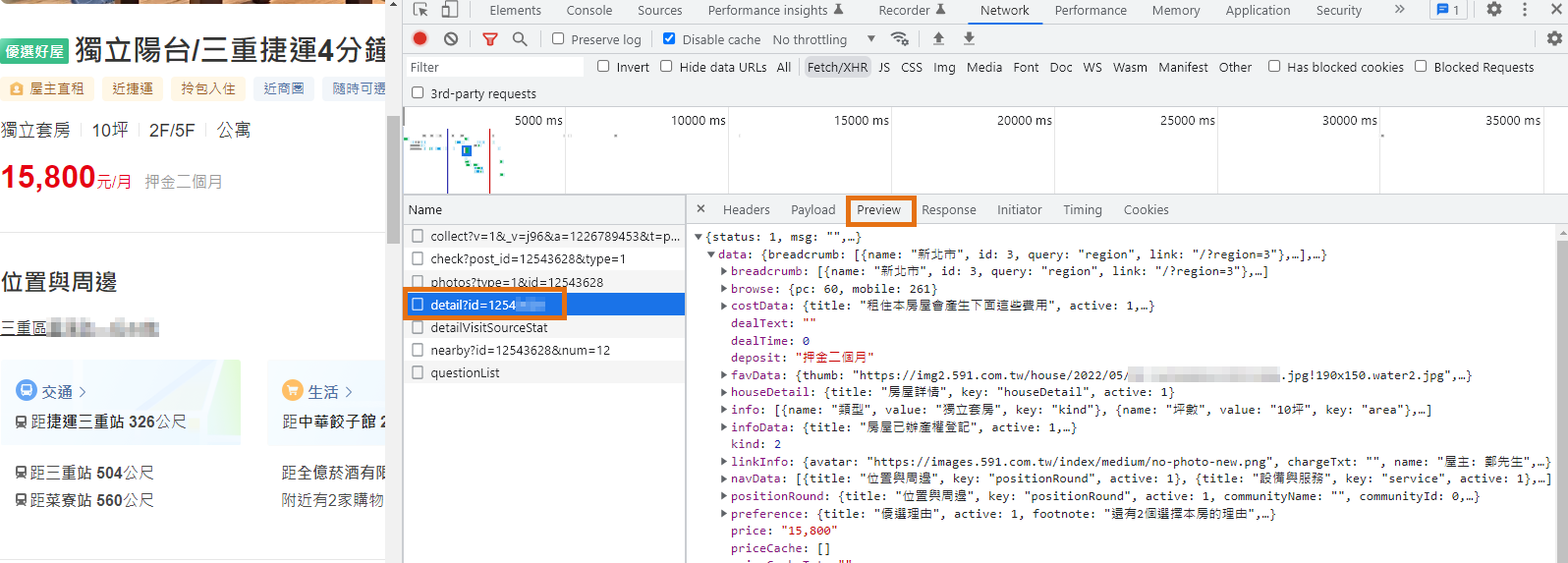
不過相比 "搜尋房屋" API 所需要的參數,"取得房屋詳情" 還多了 device、deviceid 兩個必備參數,
device 就固定 pc 即可,而 deviceid 我們透過搜尋(Ctrl+F)發現,它隱藏在 "cookie" 之中,所以之後程式要將其字串抓出來代上。
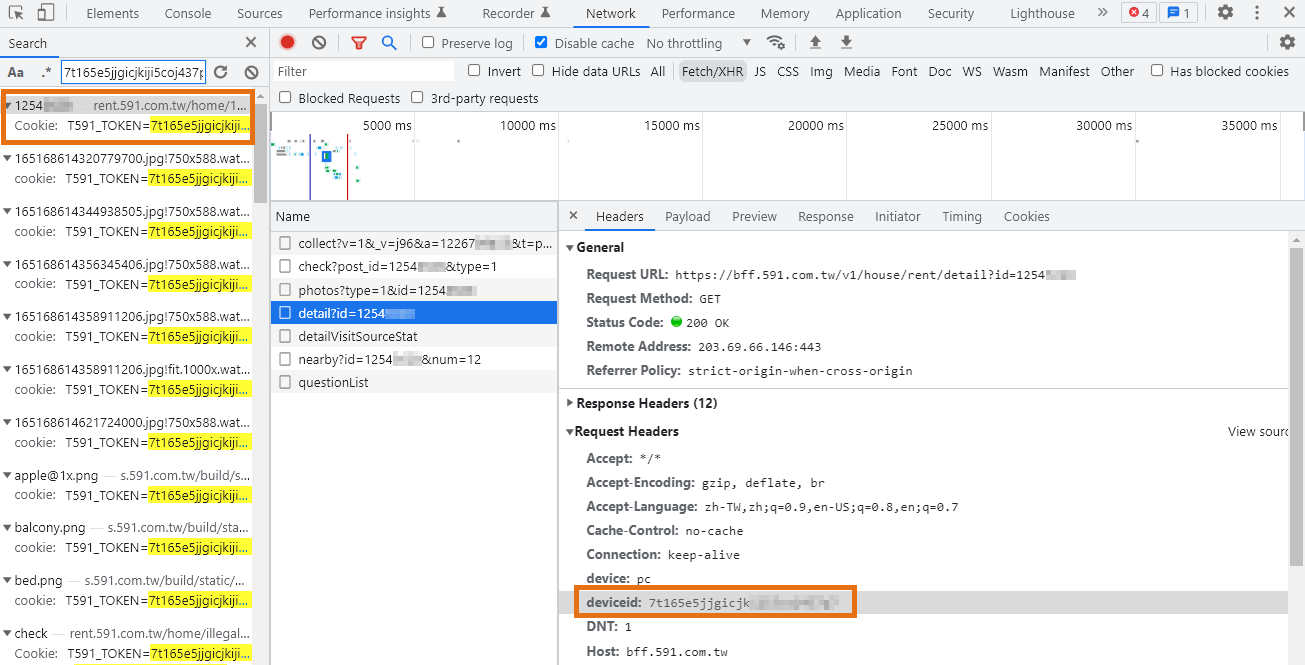
回傳資料
回傳資料大致上也是與網頁上的一樣,關於此房屋的詳細資訊,你可以挑出需要的欄位來儲存,或進一步判斷執行其他動作。
回覆資料範例: house591_detail.json (房屋詳情)
範例程式
使用 Python 撰寫 "搜尋房屋" 的寫法如下,完整程式碼請至文末參考:
| |
完整程式碼
我將以上兩種請求寫到 class 中,並可以傳入不同的值來篩選,供需要的人參考。
附上完整程式碼: house591_spider.py | GitHub
延伸練習
在上面教學與範例中,我們都是搜尋 "所有物件" 的房屋,那如果我想搜尋 "優選好屋" 該如何帶 API 參數呢?
你能試著找出全台最貴的租屋要多少租金嗎?並且是在哪個縣市鄉鎮?
台中市的房屋中 "整層住家"、"獨立套房"、"分租套房"、"雅房" 之間的數量與比例是多少呢?會是分租套房最多嗎?
結語
最後也要提醒,不要太頻繁地發出請求,這對伺服器來說算是種攻擊,也容易被擋,建議請求之間要加入 delay。
如果有找到適合或有趣的題材,會繼續寫一些網站的 Python網路爬蟲實例 ,如果你正好是剛開始想學爬蟲的新手、想知道某網站如何爬取資料、遇到其他問題,也歡迎在底下留言,或追蹤 FB 粉專『 IT空間 』~ 🔔
要成就一件大事業,必須從小事做起。
—— 列寧
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~