前言
我前陣子才發現,原來 GitHub 上面也有可以免費使用的 LLM,像是 GPT-4o、Llama-3.3、Phi-3.5…等等,甚至還提供 API 可串接程式!
雖然 GitHub Models 主要是讓我們在開發生成式 AI 應用程式測試用,算是試用性質,所以有 速率 & Token 數量限制,但我覺得用作個人專案還蠻不錯的,每日請求上限也不算太少 (50~150 次,依模型而定),有需求的網友可以試試~
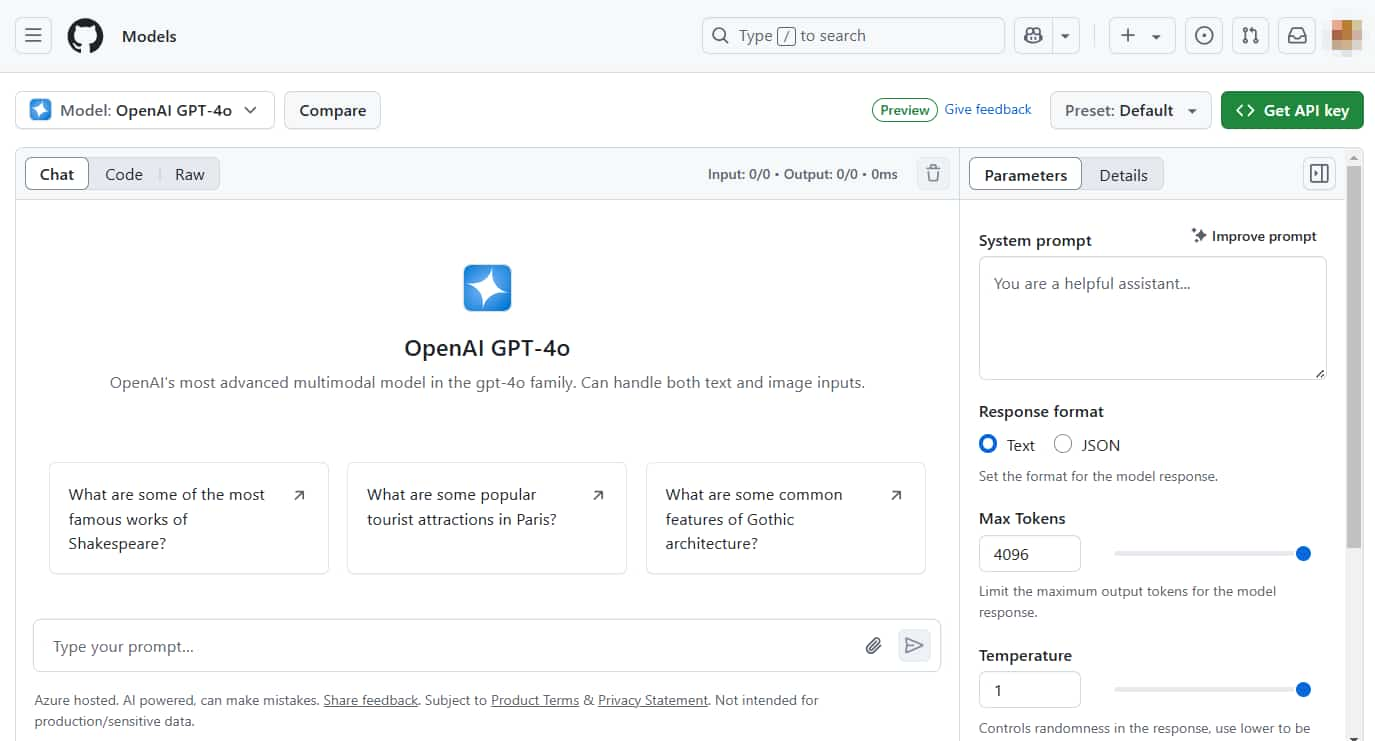
如果你發現還不能使用,可加入候補名單:https://github.com/marketplace/models/waitlist
速率限制
在開始使用之前,首先來看看它速率限制到底是多少。
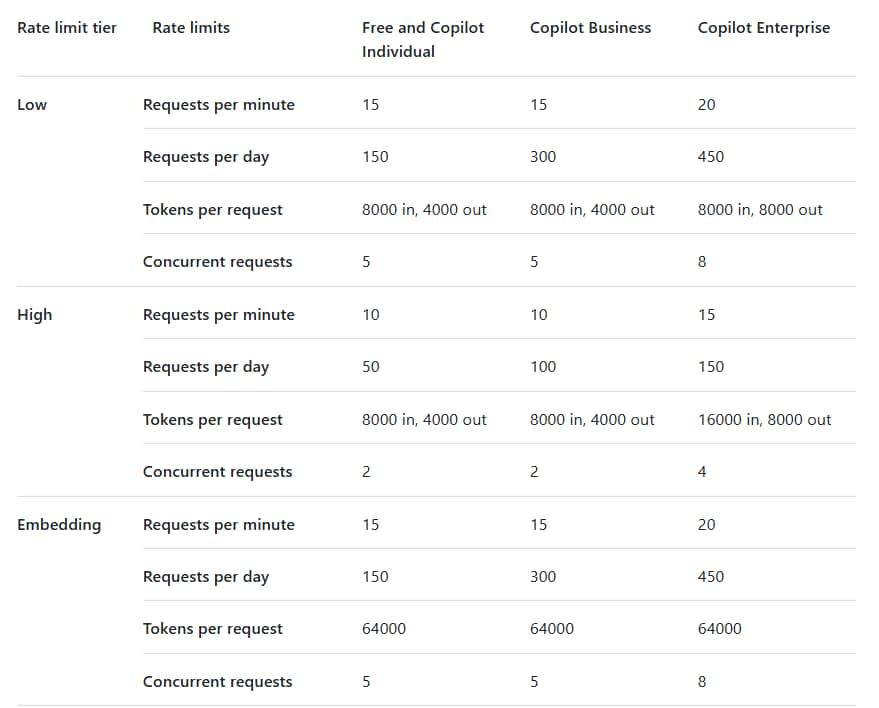
GitHub Models 是依照模型分成 Low、High、Embedding 等級去做限制,
在 模型介紹 和 Playground 頁面都有寫此模型是採用哪個限制等級 ("Rate limit tier")。
* 表格底下雖然還有 Azure OpenAI o1-preview 和 Azure OpenAI o1-mini,但我好像沒辦法使用。
例如 GPT-4o 是 "High",那它的限制就是:
- 每分鐘請求數:10 次
- 每天的請求數:50 次
- 每個請求的 Tokens:輸入 8000, 輸出 4000
- 並發請求:2 個
* 當然假如你是 Copilot Business 或 Copilot Enterprise,那可使用次數就會更多。
模型清單
GitHub Models 有提供哪些模型讓我們試用呢?
這邊有完整支援的模型清單:https://github.com/marketplace?type=models
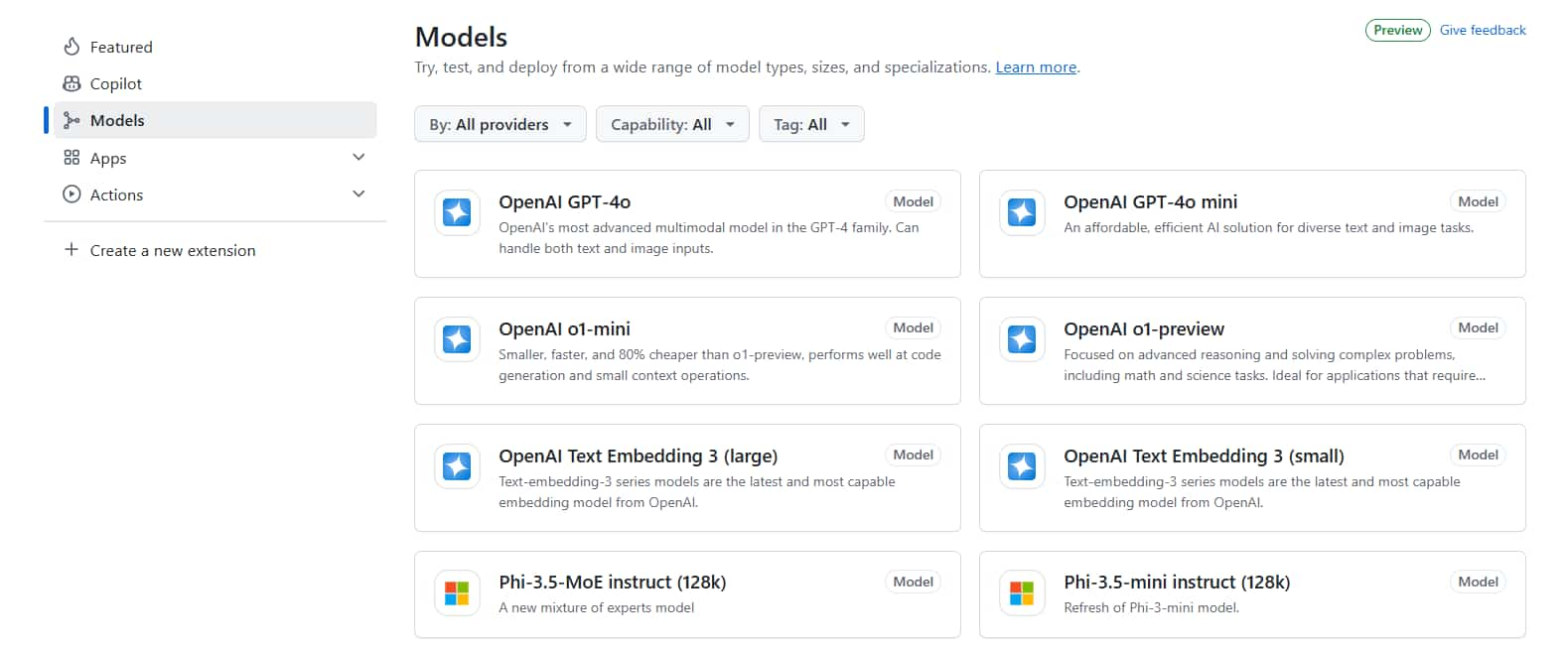
例如聊天的模型有:
- OpenAI GPT-4o
- OpenAI GPT-4o mini
- DeepSeek-V3-0324
- DeepSeek-R1
- Llama 4 Maverick 17B 128E Instruct FP8
- Llama-3.3-70B-Instruct
- Llama-3.2-90B-Vision-Instruct
- Phi-4
- Phi-3.5-MoE instruct
- Phi-3.5-vision instruct
- Mistral Large
- Mistral Small 3.1
- Codestral 25.01
- Cohere Command R+
- AI21 Jamba 1.5
- JAIS 30b Chat
- …(更多)
還有 Embedding 嵌入模型:
- OpenAI Text Embedding 3
- Cohere Embed v3 Multilingual
- …(更多)
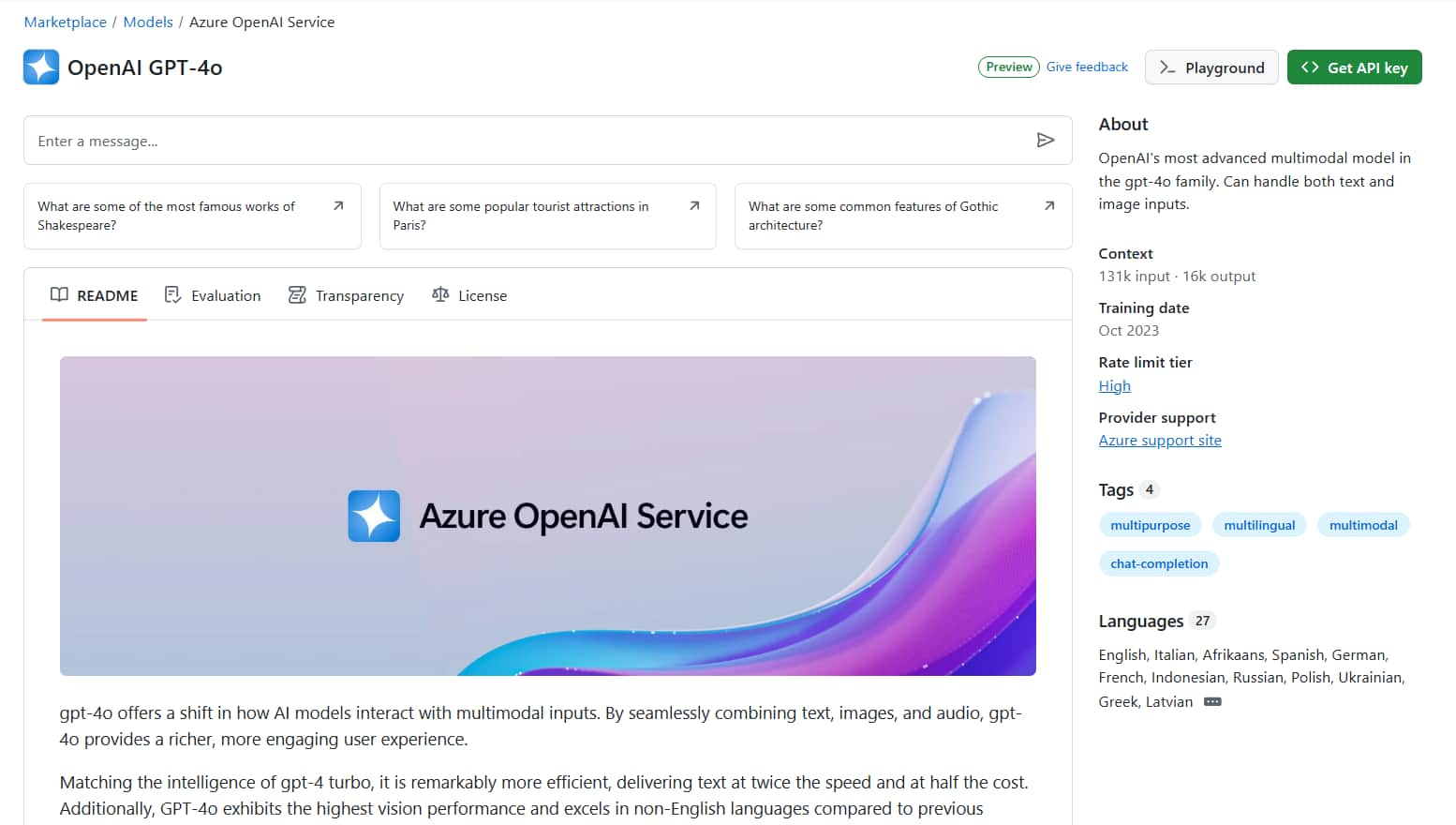
點選任一個模型後,會進入模型介紹頁面。
會有模型的相關說明介紹、測試評估分數、License 等等,右邊區塊還有像是 簡介、Context (模型"本身" 輸入、輸出 tokens 限制)、訓練資料日期、速率限制等級 (Rate limit tier)、提供者、支援語言 等等資訊。
Playground
從剛剛 "模型介紹頁面" 點擊右上角「Playground」,或在 GitHub Marketplace 左上角選擇一個模型。
即可進入 Playground 頁面跟它聊天。
* 例如 GPT-4o 的 Playground
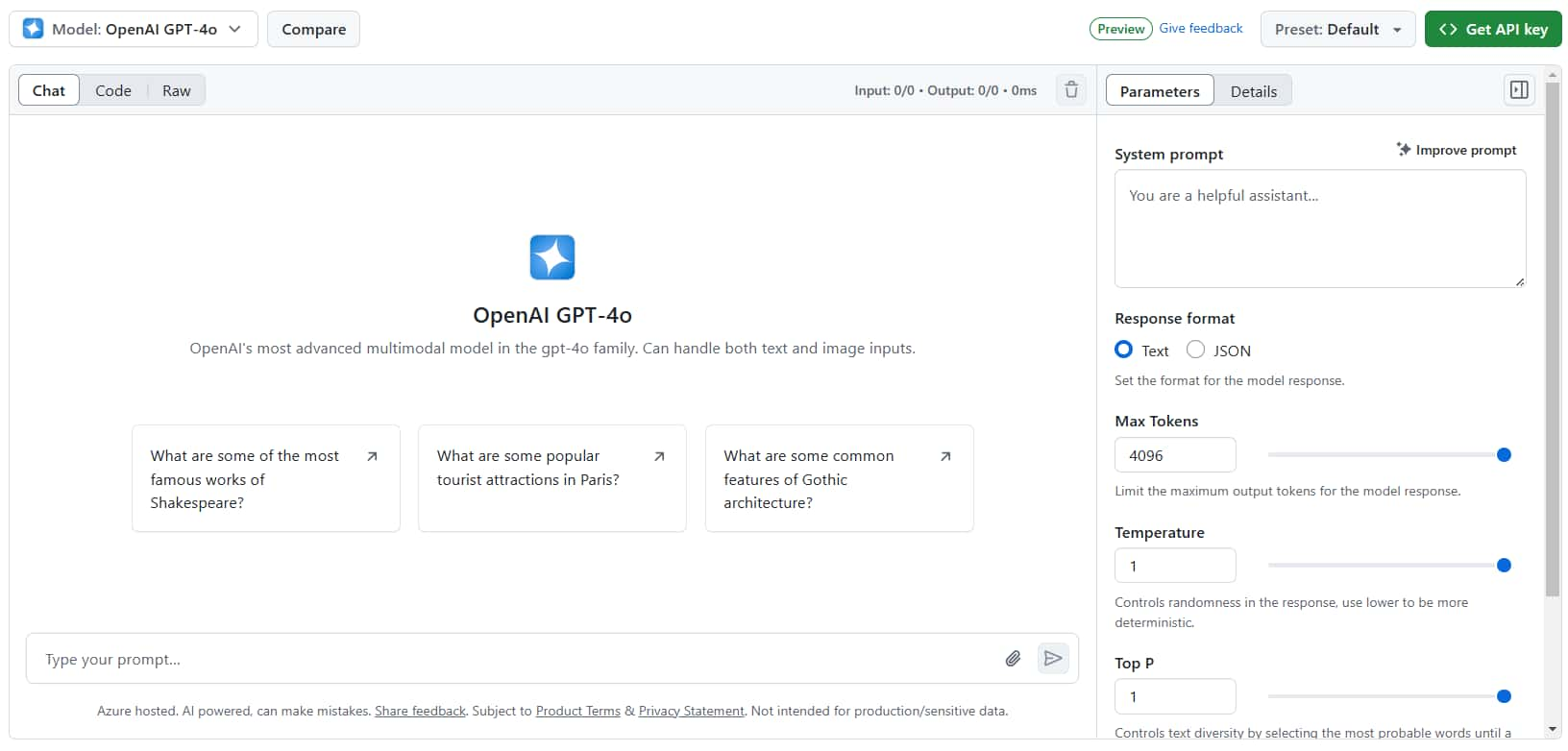
先看右側區塊可以切換 "Parameters" 和 "Details":
- Parameters:設定、調整模型參數 (System prompt、Response format、Max Tokens、Temperature……)。
- Details:模型的相關說明 (就跟剛剛的模型介紹頁面差不多)。
再來看左側區塊分為 "Chat"、"Code"、"Raw":
- Chat:如同使用 ChatGPT、Gemini 一樣,可以與模型做多輪的聊天。
- Code:展示 API 如何使用,有不同程式語言的範例,下一節 API 還會介紹。
- Raw:你與模型對話紀錄的原始資料。
另外,
在頁面左上方還可以看到「Compare」按鈕,用於比較兩種不同模型的回答,在你輸入問題(prompt)後,它會同時送給兩個模型,讓你方便比較兩種模型哪個回覆比較好。
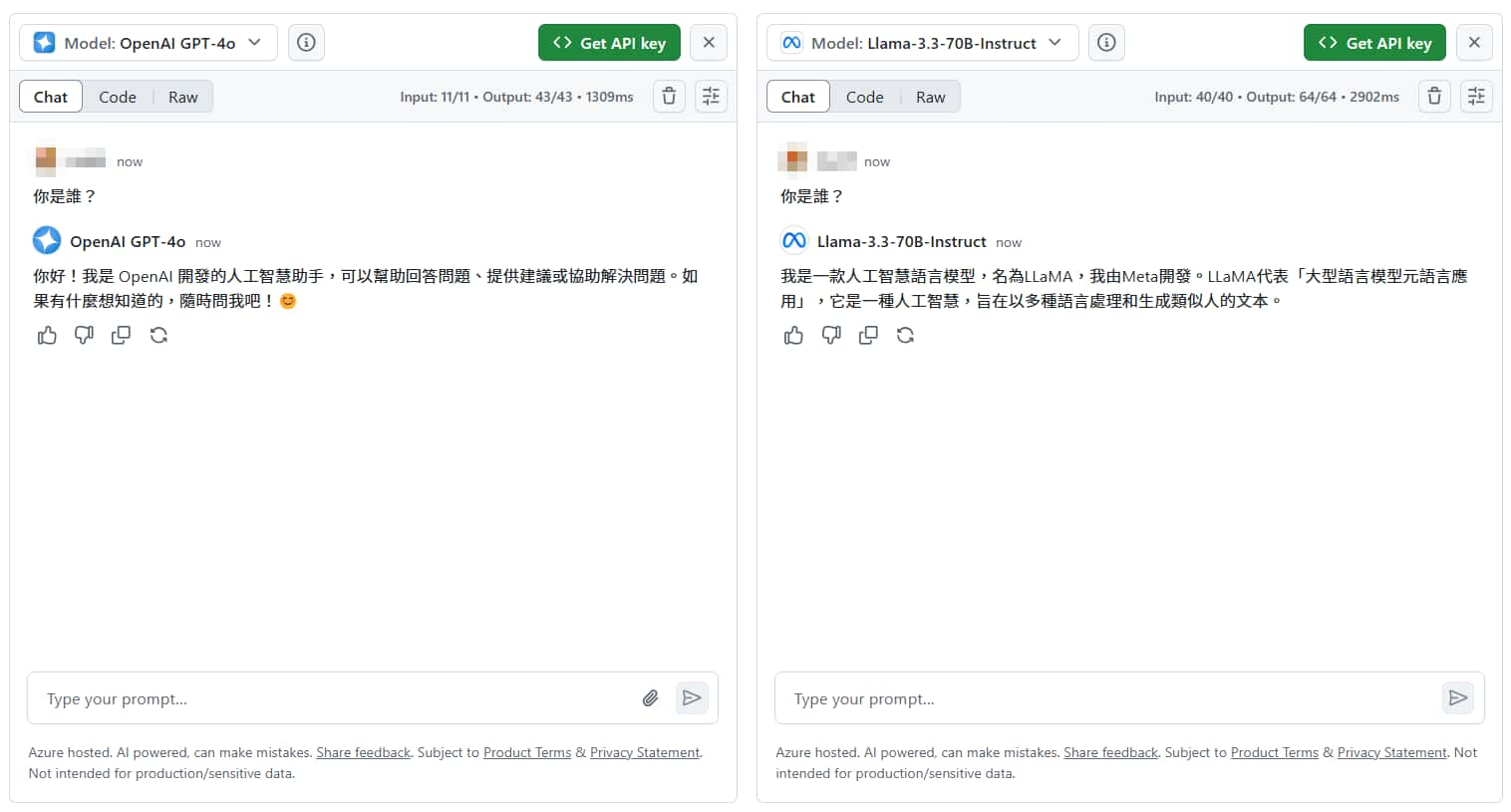
如果你想將目前調整好的參數、聊天記錄儲存起來 (甚至分享),可以使用右上角的「Preset」功能。
API
如同文章標題提到的,除了在網頁使用 Playground 介面,GitHub Models 還提供 API 供我們串接自己的程式做測試。
創建 GitHub Token
在開始使用 API 之前,我們要先去 GitHub 建立 Token,用作身份驗證。
* 關於 GitHub 的 Token 介紹,可以參考這篇官方文件: Managing your personal access tokens
Settings > 左側最下方 Developer settings > Personal access tokens > Fine-grained tokens
點選 Generate new token。
Expiration 過期時間可以改成 "No expiration" (無期限)。
Repository access 欄位維持 "Public Repositories" 即可。
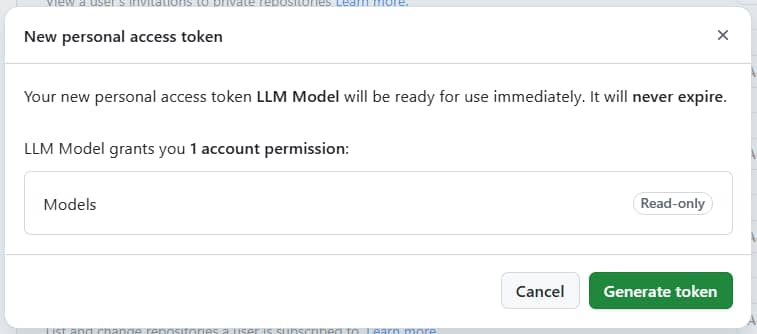
重點:
Permissions > Account permissions > Models 要改為 "Read-only",這樣才有 GitHub Models 的權限。
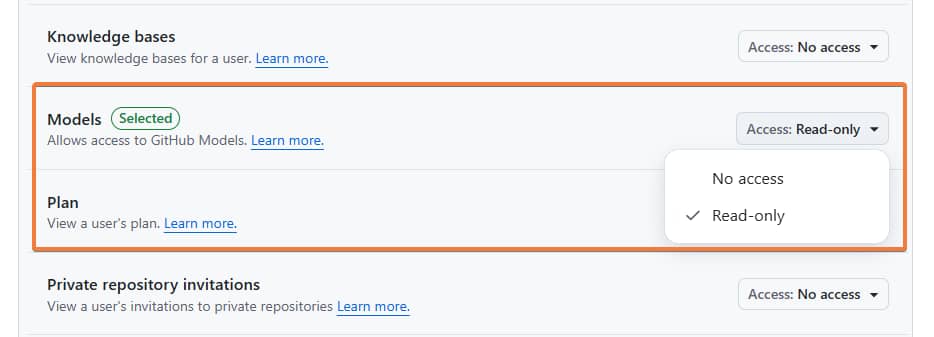
填寫完欄位後,最下方點擊 Generate token 按鈕。
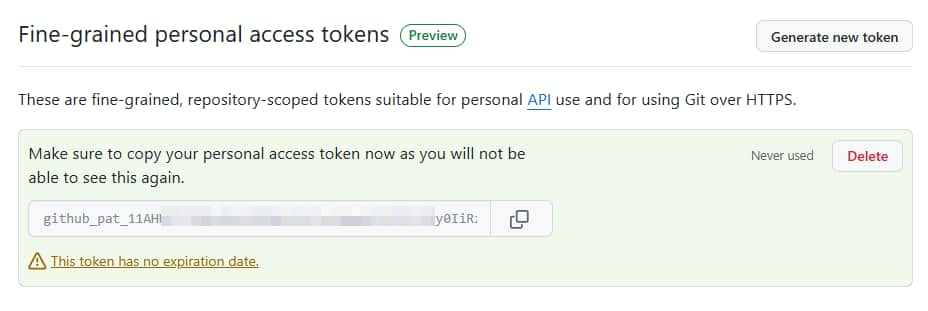
將 token 複製並保存好,之後忘記就只能再重新產生了。
Fine-grained personal access token 會長的類似這樣:github_pat_11AHxxxxxxxxxxxxxxxxxxxxxxxxxCp7pLSr3a
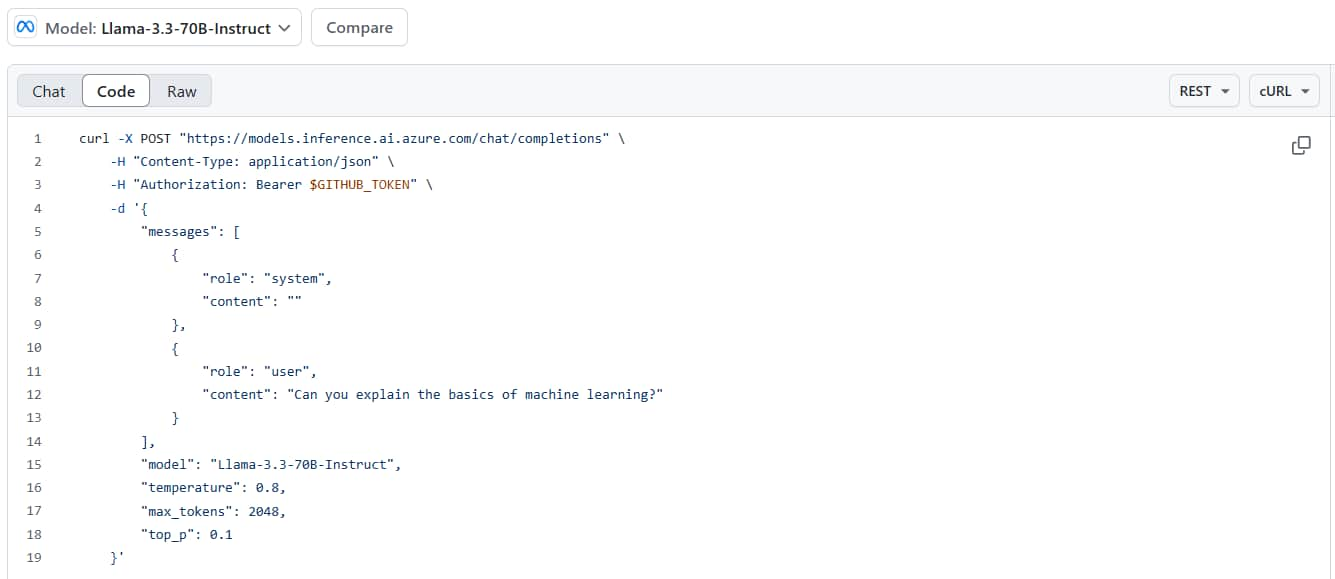
使用範例
回到剛剛 Playground 頁面的 "Code" 分頁 (像是 GPT-4o 的 Playground )。
右上角可以下拉清單選擇不同的程式語言、SDK (OpenAI SDK 或 Azure AI Inference SDK)。
切到 REST 語言,可以看到實際發送請求的 URL、Headers、Body 等等,API 格式是跟 OpenAI API 一樣的,所以如果你使用的套件、框架、軟體有支援 OpenAI API 格式,那就可以直接切換來用,或者以後 GitHub Models 測試完要換到穩定的付費 Azure OpenAI、OpenAI 也很簡單。
這邊我使用 Postman 來示範如何發送請求。
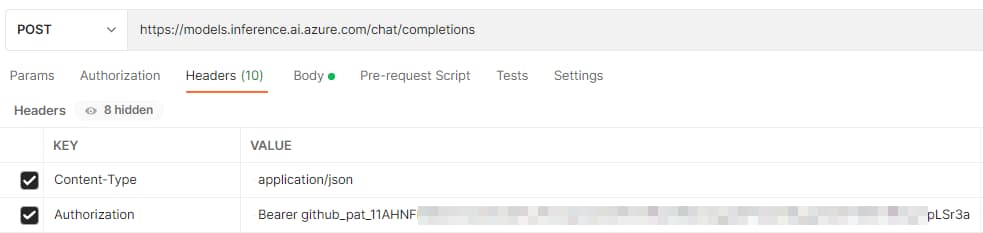
Request URL: https://models.inference.ai.azure.com/chat/completions
Request Method: POST
Request Headers:
Content-Type: application/json
Authorization: Bearer github_pat_11AHxxxxxxxxxxxxxxxxxxxxxxxxxCp7pLSr3a
* Authorization 內 Bearer 後面那串就是剛剛創建的 personal access token。
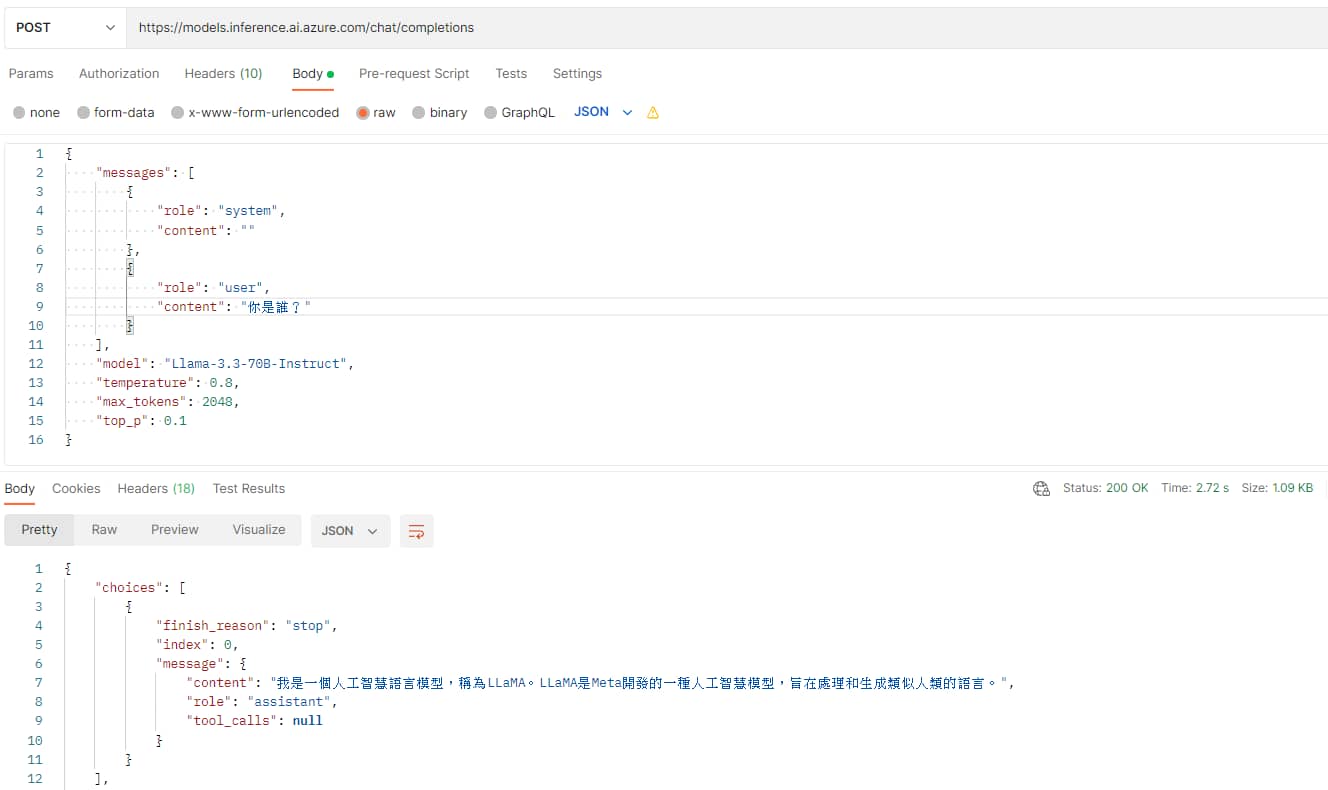
Body (JSON 格式):
| |
* 只有 messages 和 model 欄位是必要的
回傳資料範例:
| |
* 不過我在猜它是不是還會塞入其他 prompt,因為 usage > prompt_tokens 看起來明顯大於我下的 prompt token 數量。知道的網友可以留言幫我解惑~🙏
結語
如果你剛好在開發 LLM 應用專案,或使用量不多,推薦可以嘗試 GitHub Models。
如果對於 生成式 AI 有興趣的讀者,記得追蹤『 IT空間 』FB 粉專,才不會錯過最新的發文通知呦~🔔
參考:
GitHub Marketplace Models
GitHub Models 說明文件
我不是最好的那個,但我想成為最努力的那個。
—— 李洋 (台灣羽球國手)
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~