前言
時隔一年,Google 終於再度推出新一代開源模型~
支援文字和影像輸入(E4B、E2B 多支援音訊),並首次引入 MoE 架構,而且 license 改成商業上較為寬鬆的 Apache 2.0 授權,
在 Arena AI 文本排行榜(開源模型)上,31B 排全球第三、26B 排全球第六。

重點介紹
✨ Agent 能力:原生支援 function-calling、結構化 JSON 輸出、system 角色,對於現今最流行的自主 Agent 能更好支援。
✨ 影像和音訊:所有模型都原生支援「影像和視訊」輸入,支援多種分辨率 (對於 OCR、圖表識別 任務更出色)。E2B 和 E4B 型號還具備原生音訊輸入。
✨ 推理能力:能夠進行多步驟規劃和深度邏輯推理,因此在數學和指令遵循基準測試中顯著進步,並且可調整思考模式。
✨ Coding 能力:在 Coding 基準測試取得了顯著改進。
✨ 增大 Context Length:31B 和 26B 為 256K;E4B 和 E2B 為 128K。
✨ 140 多種語言:原生支援 140 多種語言。
✨ Apache 2.0 授權
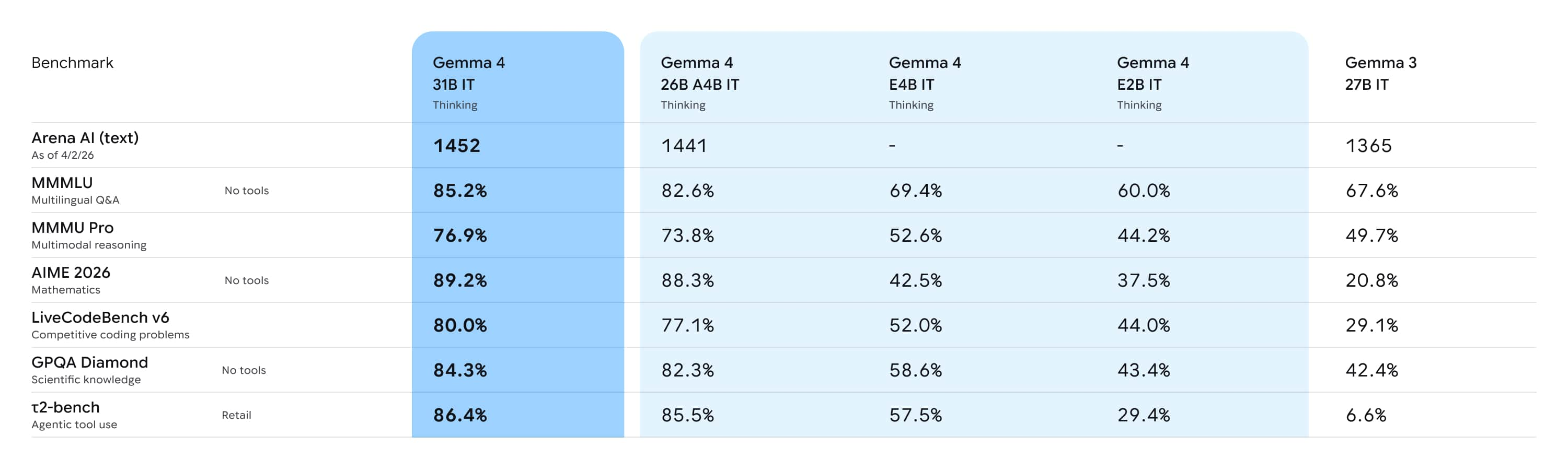
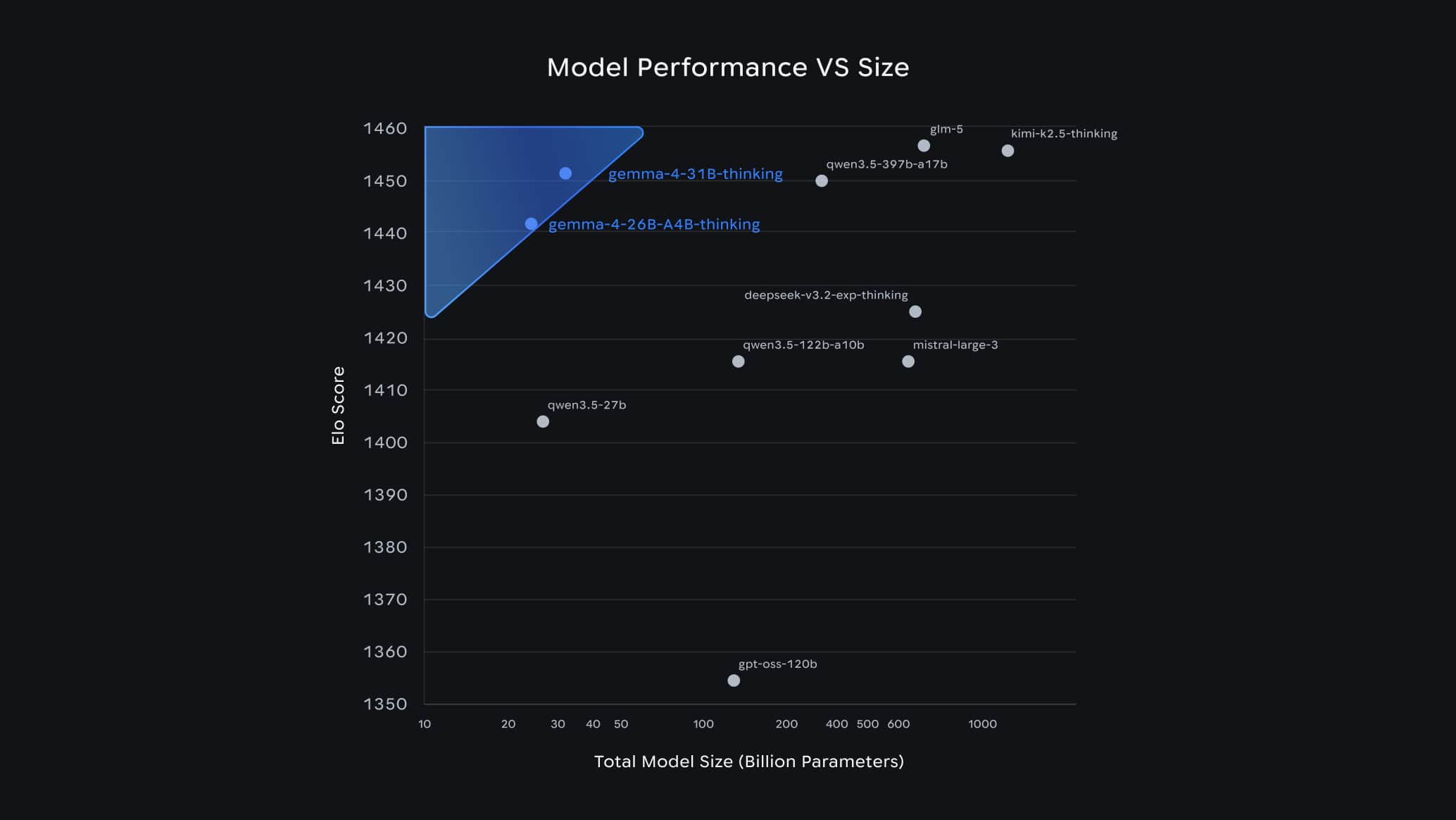
[31B 和 26B 模型]
- 參數量:30.7B (Dense) 和 25.2B (MoE 架構,4B active)
- 26B 的 Expert 數量:8 active / 128 total and 1 shared
- 輸入類型:文字、圖像
- Context Length:256K tokens
[E4B 和 E2B 模型]
針對邊緣設備最佳化,例如在行動裝置或筆記型電腦上運行。
- 參數量:4.5B effective (8B with embeddings) 和 2.3B effective (5.1B with embeddings)
- 輸入類型:文字、圖像、音訊
- Context Length:128K tokens
結語
趕緊來試試看~
對生成式 AI 感興趣的讀者,記得追蹤 FB 粉專『 IT空間 』,以免錯過最新的發文通知呦~🔔
參考:
Google 官方部落格介紹
Ollama
Hugging Face
Hugging Face 的測試文章
在你沒有成功之前,沒有任何人會理解你。
—— 比爾·蓋茲
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~