前言
這次 Google I/O 2025 公布了支援原生音訊輸出文字轉語音 (TTS) 的 Gemini 2.5 Pro 和 Flash,可以指定語音的風格、口音、速度和音調等等,而且還可以一次生成單一發言者或多位發言者。
同步,Google AI Studio 也加入 Gemini speech generation 介面,方便我們透過網頁 UI 直接試玩。
延伸閱讀:
我就想到 Google 的 NotebookLM,它透過 AI 自動從多篇文章整理並生成出一段通順、自然的語音摘要功能 (Audio Overview),是由兩位虛擬主持人對話的 Podcast 語音,非常的厲害,讓我很想一玩再玩。
那既然這次 Google 公布了原生音訊輸出文字轉語音 (TTS) ,就想說感覺應該可以自己來試試,不管是逐字稿,還是對話語音,都由 Gemini 來生成 (我只要坐在旁邊看就好)。
相比 NotebookLM,透過此方法可以有更高的自由度、主控權,例如調整每一句要講什麼內容、Podcast 整體長度、細節語氣變化…等等。
成品效果會像這樣:
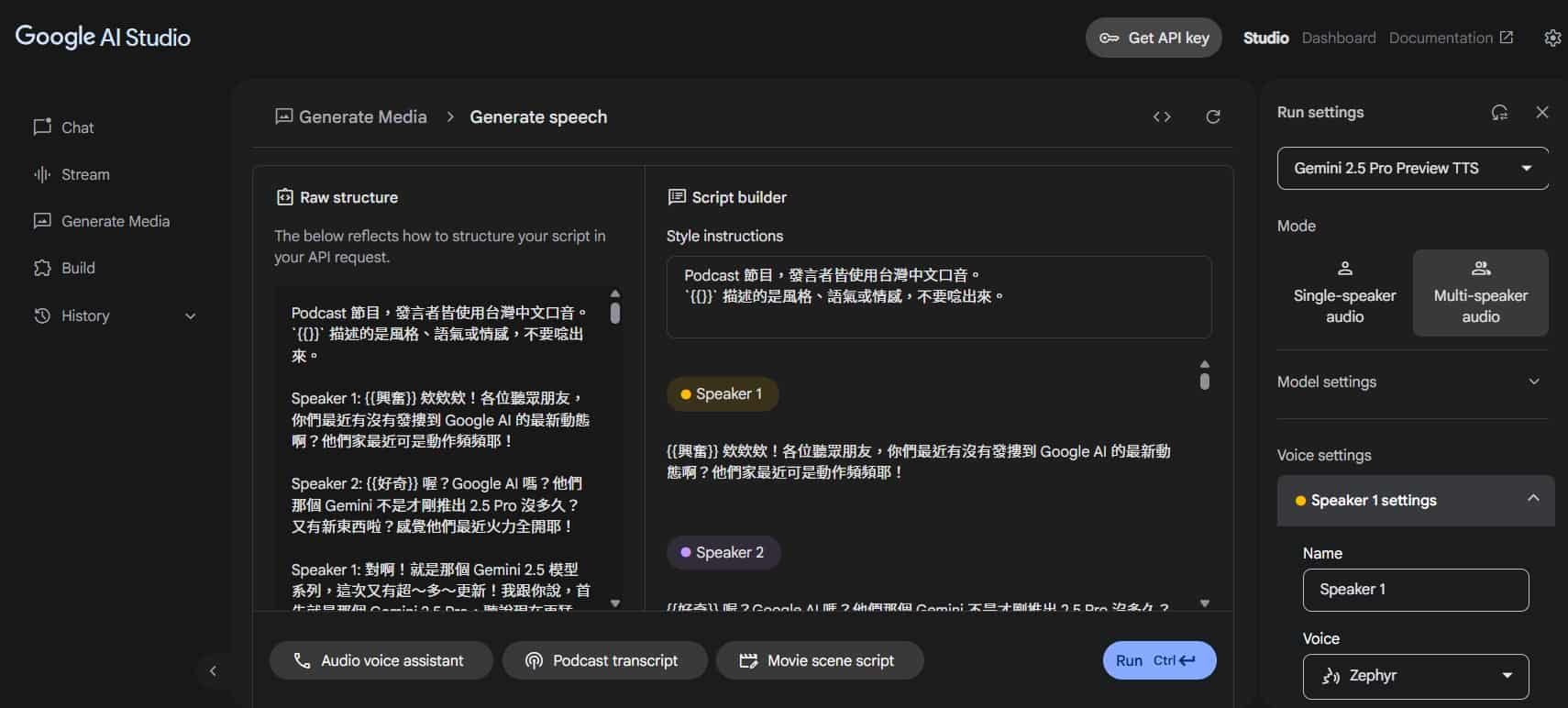

Gemini speech generation 介面
先來了解一下 Google AI Studio 的 Gemini speech generation 操作介面,在 Generate Media > Gemini speech generation。
直接先看右側的面板。
可以選擇生成語音的模型,目前有兩個模型可以選擇:
- Gemini 2.5 Pro Preview TTS
- Gemini 2.5 Flash Preview TTS
建議優先使用「Gemini 2.5 Pro Preview TTS」模型,我測試起來效果還是比較好的。
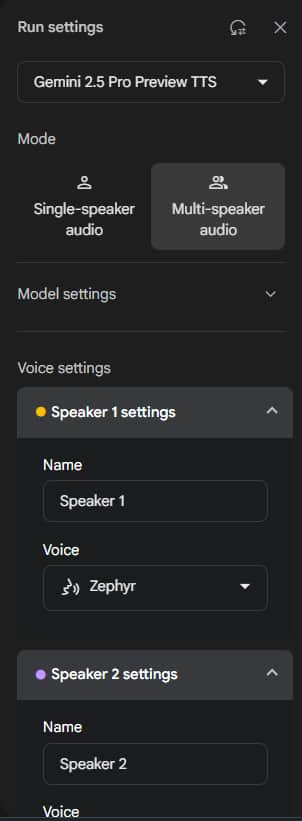
再來選擇要單一發言者或多位發言者(目前最多兩位):
- Single-speaker audio
- Multi-speaker audio
最後 "Voice settings " 個別設定他們的名字與語音風格。
語音風格每個都可以點擊播放鍵試聽,目前
共有 30 種語音風格
可以選擇。
* 雖然官方文件內寫 目前支援的語言沒有中文 ,但我測試中文結果還是不錯的。
看回中間的部分,設定文字腳本 (也就是我們希望它念的內容),分成左右兩邊 "Raw structure" 和 "Script builder",其實他們是一樣的內容,修改其中一邊,另一邊也會跟著同步。
之後我們生成的逐字稿內容,可以直接一次貼在左邊的 "Raw structure",較方便。
右邊的 "Script builder" 只是為了讓我們在 UI 上操作,並確認格式有沒有跑掉。
從文章生成 Podcast 語音
這次我們最主要的目的,是想要「從文章去生成出一段 Podcast 風格的對話語音」。
我的基礎概念很簡單,就是先由 Gemini 模型將一篇(或多篇)文章整理成 Podcast 逐字稿,再交由 Gemini TTS 模型去生成出 Podcast 語音檔案。

接下來,一起來實際看看該怎麼操作吧~🚀
生成 Podcast 逐字稿
首先,我們後續想透過 Gemini TTS 模型生成語音,就要先來了解它支援的腳本架構。
* 因為我想要的是兩人的 Podcast 風格,因此我是選擇 "Multi-speaker audio" (兩位發言者)。
它的開頭是 "Style instructions",可以針對風格、口音、速度、音調…等等去描述。
再來就是每位發言者說的內容,前面使用 Speaker 1: 和 Speaker 2: 來標示 (這兩個名字可以換,記得要去右測面板 "Voice settings" 設定)
我測試發現,有關說話的語氣、情緒也可以寫在內容裡,不過要做點標示讓 AI 能懂,它才不會以為是逐字稿而唸出來,像我是使用 {{}} 符號來跟一般內容區隔。這部分官方沒有說明,用別的符號也可以,但不要用單個小括號 (),我測試過它有時候會不小心說出來 XD
* 如果不指定語氣、情緒,模型也會自動根據文字內容產生符合的,但這就像是通訊軟體內的文字訊息,同樣一句話,但不同人看,可能會有不同的理解與感受。因此明確標註語氣或情緒,能幫助模型生成更準確符合我們的預期。
了解腳本架構後,我們來到 " Google AI Studio > Chat "。
我這邊是使用 Gemini 2.5 Pro Preview 模型,比較聰明,效果應該會更好。
[2025/05/30 補充]
目前我有想到三種文章來源的方法:
- 自己手動複製文章內容
- 透過「網址」- URL context
- 透過「Google 搜尋」- Grounding with Google Search
自己手動複製文章內容
這是最直覺的方法,也就是去網路上找到文章,然後手動複製文章內容到 prompt 裡面,相對來說較麻煩一些,但是可以自己刪減、微調文章內容。
以下是我自己想出來的 prompt,各位可以直接複製來用,並依照自己的需求修改:
根據以下文章內容,整理出雙人 Podcast 逐字稿,遵循以下規則:
- 逐字稿使用繁體中文。
- 逐字稿總長度約 1000 字。
- 分別有 主持人 "Speaker 1" 與 主持人 "Speaker 2","Speaker 1" 為台灣人年輕女性、"Speaker 2" 為台灣人年輕男性。
- 如果有必要,主持人互相使用 "你" 稱呼。
- 皆使用台灣用語、台灣連接詞,可以適時使用台灣狀聲詞。
- 如果有需要描述語氣、情緒,使用 "{{}}",例如 "{{哈哈大笑}}" 或 "{{難過情緒}}"。
- 只需要輸出逐字稿,不需要其他說明。
- <其他要求,例如流程、架構、著重特定聽者>
逐字稿範例:
```
Speaker 1: {{驚嘆}} 哇塞!各位聽眾朋友,你們知道嗎?
Speaker 2: {{疑問語氣}} 最近有什麼有趣的新聞嗎?
Speaker 1: NotebookLM 最近加入一個「Audio Overviews」新功能。
Speaker 2: {{小小的疑問}} 你是說 Google 推出的 NotebookLM 嗎?
Speaker 1: 沒錯!它最近有個新功能,可以把 PDF、影片、圖檔這些資料,直接做成精美的簡報,而且還有圖片跟流暢的旁白喔!據說它可能用了那個很威的影片生成模型 Veo2。
Speaker 2: {{語氣轉折、好奇}} 不過咧,講到這裡,可能有些台灣朋友會想說:「{{疑問語氣}} 那中文版可以用嗎?」
Speaker 1: {{微微嘆氣}} 欸,很可惜,目前中文版的 NotebookLM 還沒看到這個 Video Overviews 的功能...
```
文章內容:
```
<文章內容貼這裡>
```
例如我餵給它這篇文章: Gemini 2.5: Our most intelligent models are getting even better
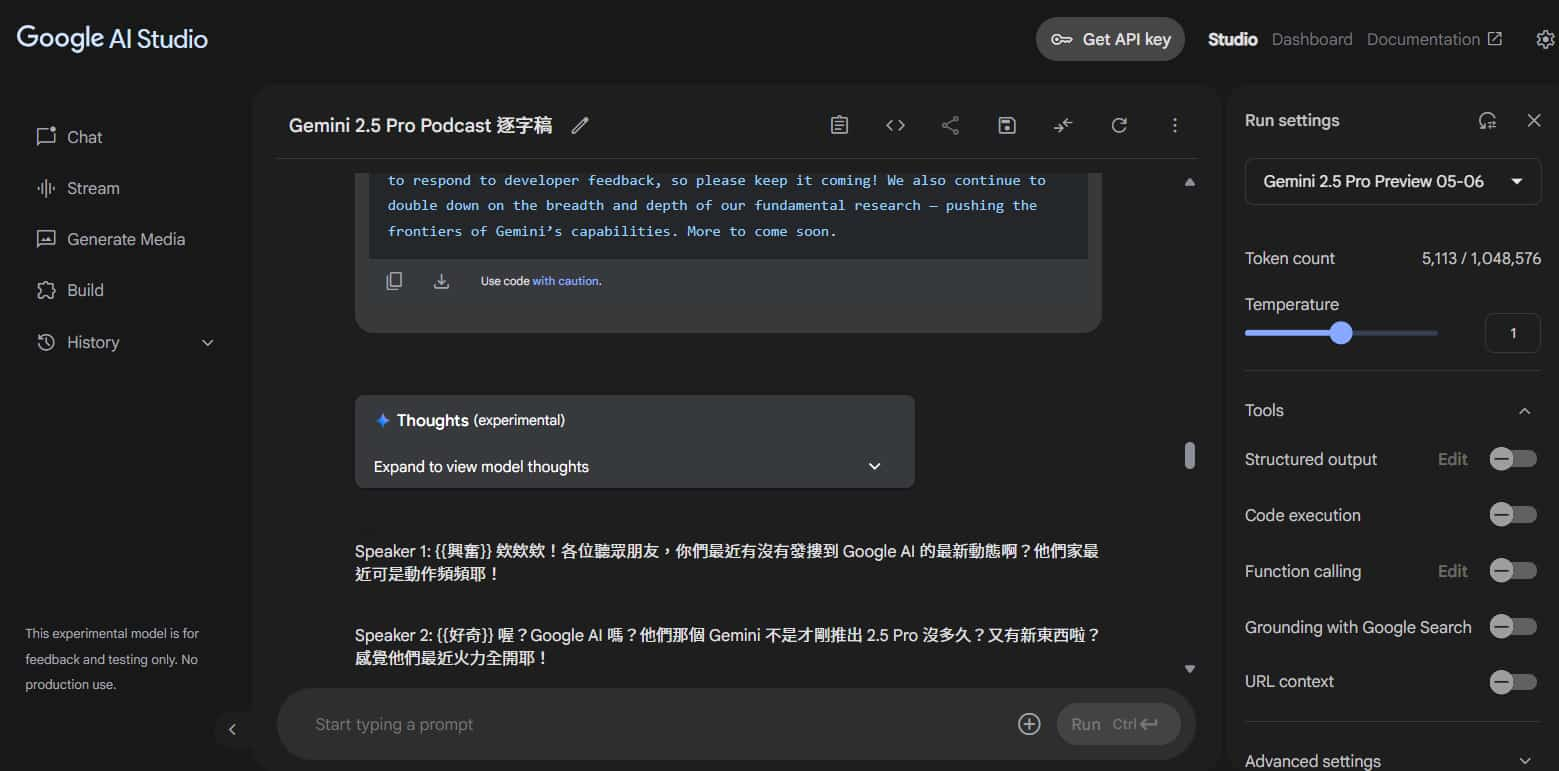
可以看到有依照我們的指令,生成較符合台灣人的用語、語助詞,這樣可以讓後續結果更人性化、自然~
("發摟"、"哇塞"、"很威欸"、"最屌的" 🤣🤣🤣)
迷之音:那這樣以後我們做 Podcast,是不是可以請 Gemini 來當嘉賓,直接生成雙人對話了?{{開玩笑語氣}} -> 現在就是了 😆
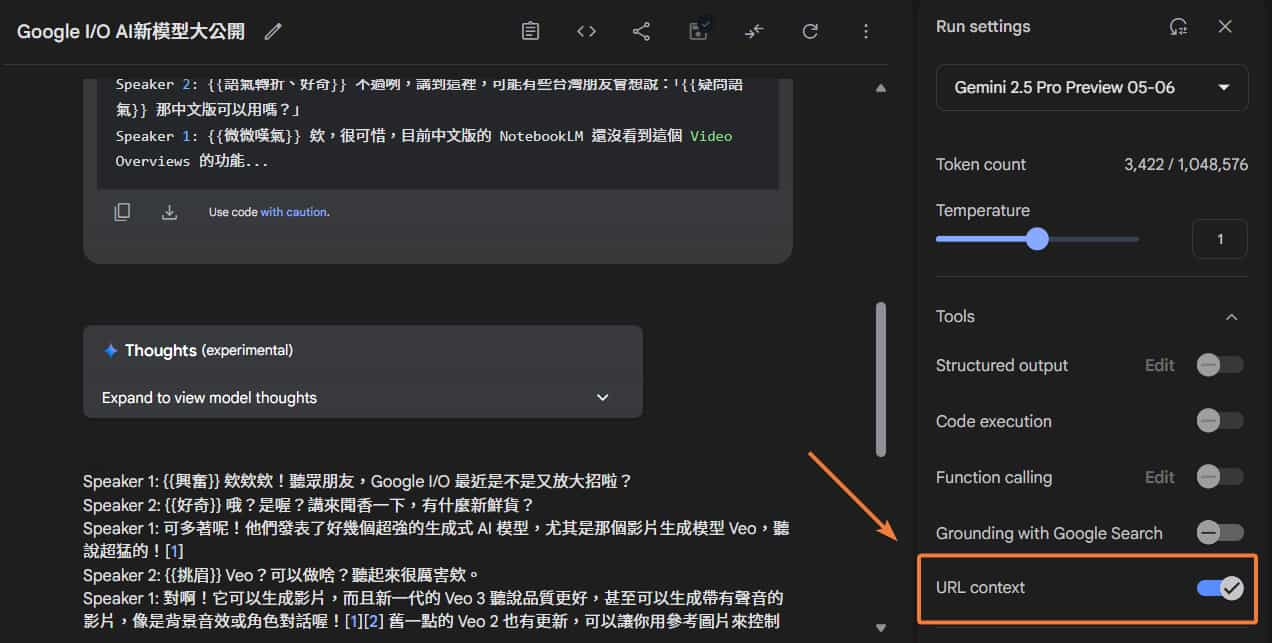
透過「網址」- URL context
URL context 也是這次 Google I/O 公布的工具,在右側設定欄開啟後,模型可以從 URL 中檢索內容,並使用該內容來回應,這樣我們就不用手動複製文章了。
範例 prompt 如下:
根據以下文章連結,整理出雙人 Podcast 逐字稿:
- https://blog.google/technology/ai/generative-media-models-io-2025/
- https://cloud.google.com/blog/products/ai-machine-learning/announcing-veo-3-imagen-4-and-lyria-2-on-vertex-ai
遵循以下規則:
- 逐字稿使用繁體中文。
- 逐字稿總長度約 1000 字。
- 分別有 主持人 "Speaker 1" 與 主持人 "Speaker 2","Speaker 1" 為台灣人年輕女性、"Speaker 2" 為台灣人年輕男性。
- 如果有必要,主持人互相使用 "你" 稱呼。
- 皆使用台灣用語、台灣連接詞,可以適時使用台灣狀聲詞。
- 如果有需要描述語氣、情緒,使用 "{{}}",例如 "{{哈哈大笑}}" 或 "{{難過情緒}}"。
- 只需要輸出逐字稿,不需要其他說明。
- <其他要求,例如流程、架構、著重特定聽者>
逐字稿格式範例:
```
<逐字稿範例貼這裡,參考上小節範例>
```
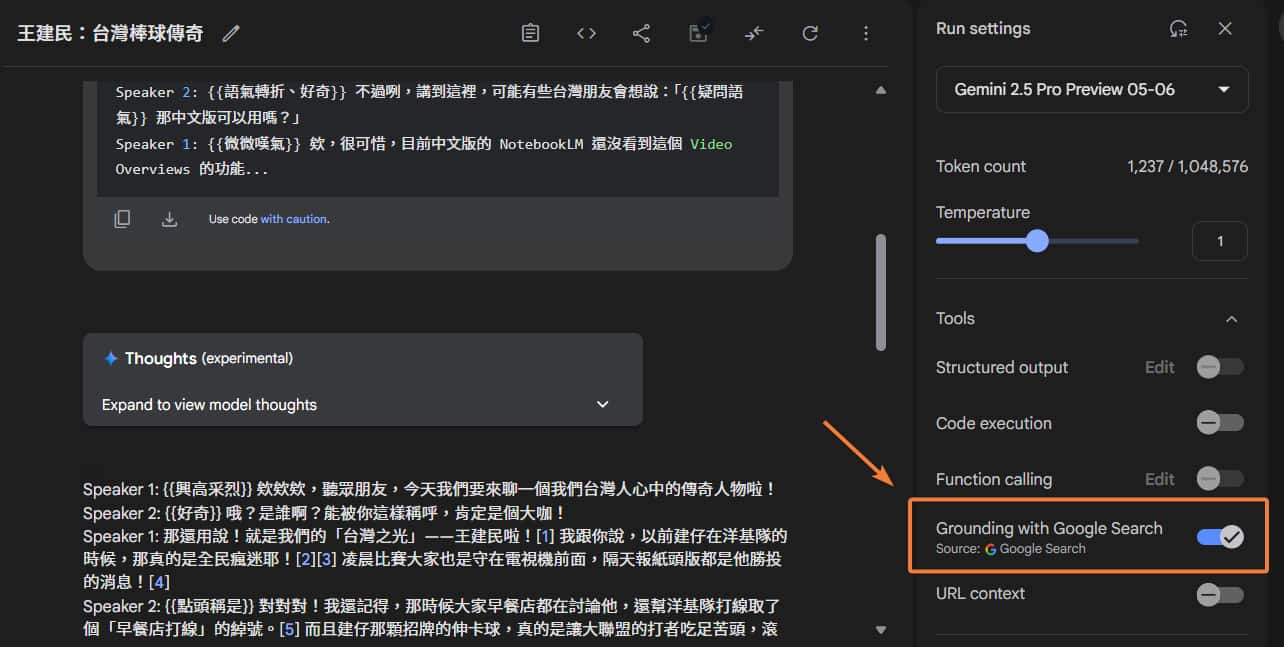
透過「Google 搜尋」- Grounding with Google Search
這是再更方便(懶人)的方法,連自己找文章都不用了,直接請模型自己 Google 搜尋 (記得右側要開啟 Grounding with Google Search 工具),我們只要給他主題方向就好。
範例 prompt 如下:
透過 Google 搜尋尋找相關文章,整理出雙人 Podcast 逐字稿,主題是「傳奇人物—王建民」。
遵循以下規則:
- 逐字稿使用繁體中文。
- 逐字稿總長度約 1000 字。
- 分別有 主持人 "Speaker 1" 與 主持人 "Speaker 2","Speaker 1" 為台灣人年輕女性、"Speaker 2" 為台灣人年輕男性。
- 如果有必要,主持人互相使用 "你" 稱呼。
- 皆使用台灣用語、台灣連接詞,可以適時使用台灣狀聲詞。
- 如果有需要描述語氣、情緒,使用 "{{}}",例如 "{{哈哈大笑}}" 或 "{{難過情緒}}"。
- 只需要輸出逐字稿,不需要其他說明。
- <其他要求,例如流程、架構、著重特定聽者>
逐字稿格式範例:
```
<逐字稿範例貼這裡,參考上小節範例>
```
* 懷念的王建民那段時光 ><
生成 Podcast 語音
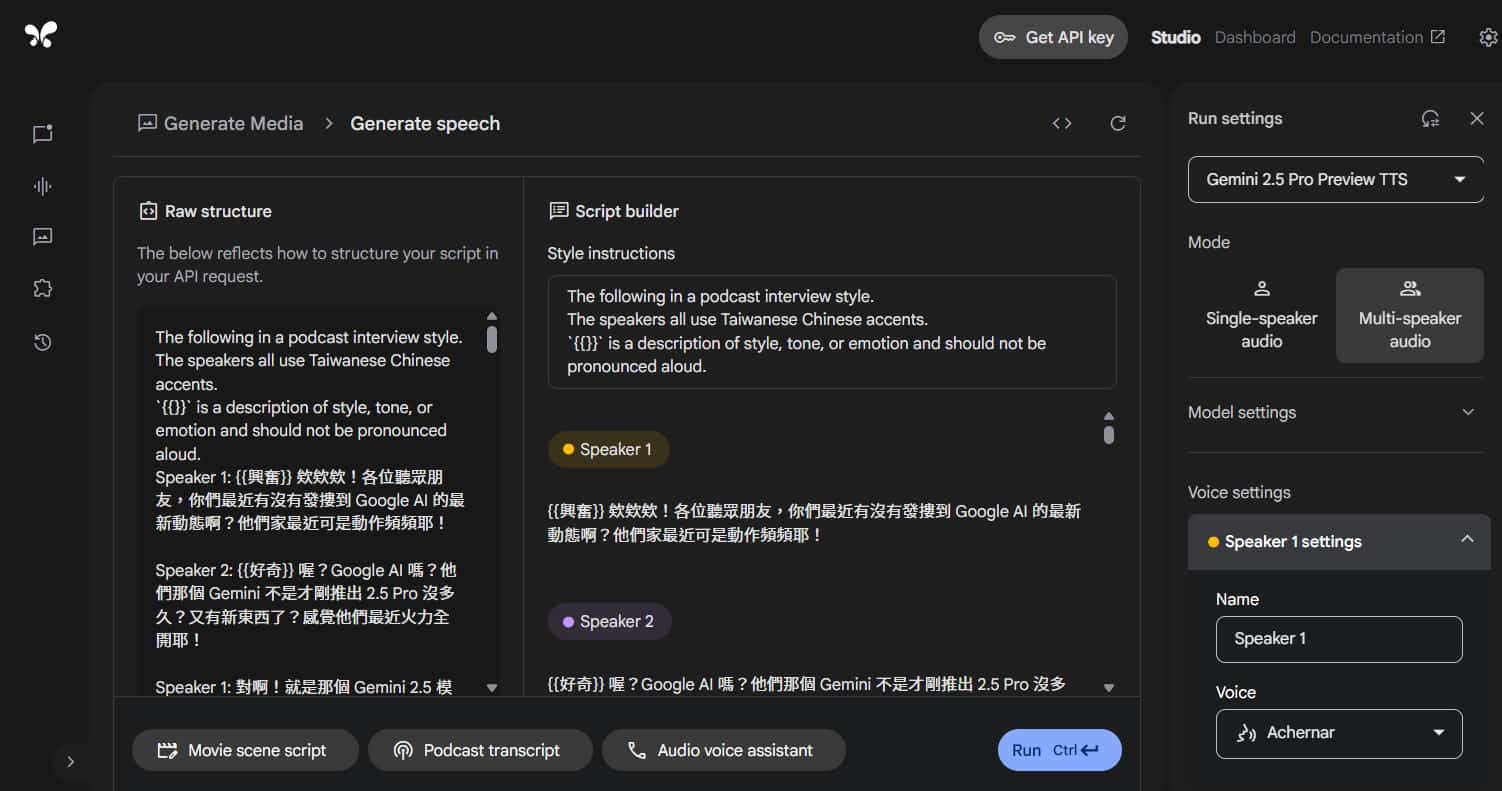
來到 " Google AI Studio > Gemini speech generation " 介面。
將剛剛生成的逐字稿貼到 "Raw structure" 區塊後,可以在開頭設定 "Style instructions",使其產生的語音更符合我們的情境或要求,例如跟它說這是 Podcast 對話、主持人是台灣人、提醒它 {{}} 內容為風格、語氣或情感描述,不要唸出來…等等。
* 中文也可以,只是我想說它英文應該更能了解,就使用英文 prompt 了。
以下是我加上的 Style instructions:
The following in a podcast interview style.
The speakers all use Taiwanese Chinese accents.
`{{}}` is a description of style, tone, or emotion and should not be pronounced aloud.
依據逐字稿長度不同,稍等幾分鐘,完成後會顯示在左下角,可以點擊聆聽或下載。
* 以上個小節的 "生成逐字稿結果 範例" 的逐字稿長度,它生成的中文總語音長度約為 8 分鐘。
成果範例
我試了幾種語言,各位可以自己試聽看看~
🎙️中文 Podcast (非官方支援語言,以上教學示範的成果)
* 語音風格選的是 Achernar 和 Rasalgethi。
🎙️英文 Podcast (官方支援語言)
* 語音風格選的是 Sulafat 和 Lapetus
🎙️日文 Podcast (官方支援語言)
* 語音風格選的是 Zephyr 和 Puck。
🎙️韓文 Podcast (官方支援語言)
* 語音風格選的是 Aoede 和 Achird。
結語
可惜中文聽起來跟 NotebookLM 還有點差距,感覺以上的 prompt 還可以再做調整,而且官方寫目前還沒支援中文,可能就是中文的效果還沒到很理想 (有時候還會有老外講中文的口音 XD),另外目前也還是 Preview 版本,正式上線後應該會再更好。
但相比 NotebookLM,此方法可以有更高的自由度、主控權,例如調整每一句要講什麼內容、Podcast 整體長度、細節語氣變化、口音、速度…等等。
而且能達成的成果也算不錯了,跟以前死板的機器人語音有很大的不同~
有關更多介紹與 API 的使用,可參考官方文章: Gemini API docs - Speech generation (Text-to-speech)
迷之音:未來被 AI 統治,會不會人類被 AI 反過來強迫錄製 Podcast (誤
如果對於 生成式 AI 有興趣的讀者,記得追蹤『 IT空間 』FB 粉專,才不會錯過最新的發文通知呦~🔔
參考:
An upgraded dev experience in Google AI Studio
Gemini API docs - Speech generation (Text-to-speech)
要是我不打起精神的話,誰都不會為我的人生負責啊!
—— IU (李知恩)
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~