前言
本次 Python網路爬蟲實例 系列的「 Yahoo奇摩知識+ 」,將帶領你來一步步爬取所有分類的問題與解答。
「Yahoo奇摩知識+」大約 10 年前左右在台灣還蠻多人用的,但現在會在Yahoo奇摩知識+上發問、回答的人已經少很多了。話說最近有人對Yahoo奇摩知識+有印象,會不會是從天氣之子呢(笑),不過「Yahoo奇摩知識+」在日本是叫「Yahoo!知恵袋」哦~
* 香港叫「Yahoo知識+」,但為什麼台灣的多出"奇摩"兩個字呢?較年輕的讀者可能不知道,「奇摩站」是以前台灣一家入口搜尋網站,但這又是另外一個故事了…
備註:此文僅教育學習,切勿用作商業用途,個人實作皆屬個人行為,本作者不負任何法律責任
套件
此次 Python 爬蟲主要使用到的套件:
安裝
| |
它資料是如何載入的呢?
進到 Yahoo奇摩知識+ 網站後,將網頁往下滾動,可以看到 Loading 的圖示,而且頁面也沒有跳轉,因此可以猜測它資料是透過 AJAX 的方式載入
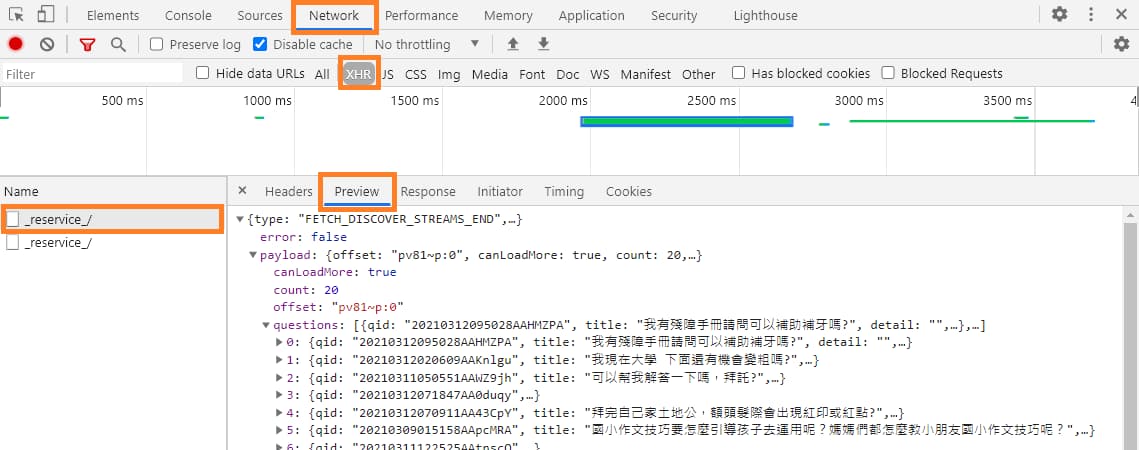
經過以前網路爬蟲實例的文章應該很熟悉了,打開瀏覽器的 開發人員工具 (F12 或 Ctrl + Shift + i),切換到 "Network" > "XHR",再將網頁往下滾動,讓我們抓到它送出的請求。點擊 "_reservice_/" 的請求後切換到 "Preview" 頁面,可以發現它返回的資料都在這裡。
開發人員工具切回到"Headers"頁面查看請求的網址與方法。
跟我們一般常用的 HTTP 請求方法(GET、POST)不同,在這裡它是使用 PUT 方法。
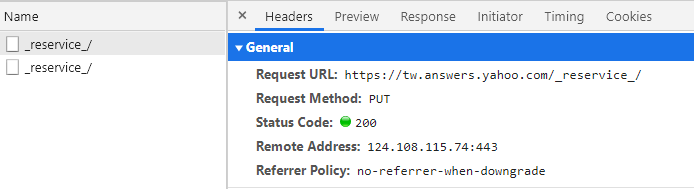
往下還有請求夾帶的參數 Request Payload,可以點擊 view source 方便我們複製參數。

請求網址:https://tw.answers.yahoo.com/_reservice_/
請求方法:PUT
Request Payload:{"type":"CALL_RESERVICE","payload":{"categoryId":"0","lang":"zh-Hant-TW","count":20,"offset":"pv61~p:0"},"reservice":{"name":"FETCH_DISCOVER_STREAMS_END","start":"FETCH_DISCOVER_STREAMS_START","state":"CREATED"}}
這邊有個之前文章沒遇過的地方,以前請求夾帶的參數常遇到的是 key-value (鍵值對)的形式,但這邊是採用 JSON 格式,因此 Headers 內要加入 content-type(HTTP 內容類型) 來表明用 JSON 格式來傳遞參數資料。'content-type': 'application/json'
同時要注意請求的 data 中資料是 JSON 格式的字串,在 Python 程式裡記得要使用 json.dumps() 將其轉換為字串,大致如下程式碼所示。
| |
好!!那這樣都知道"Yahoo奇摩知識+"資料的請求方法了,我們來看看其參數有哪些值~
問題列表
首先從網站一進入就會看到的問題列表(文章列表)說起,左方有各式各樣的分類,中間的問題列表還有分為"探索"與"解答",綠色方框即是我們想要獲取的部分。
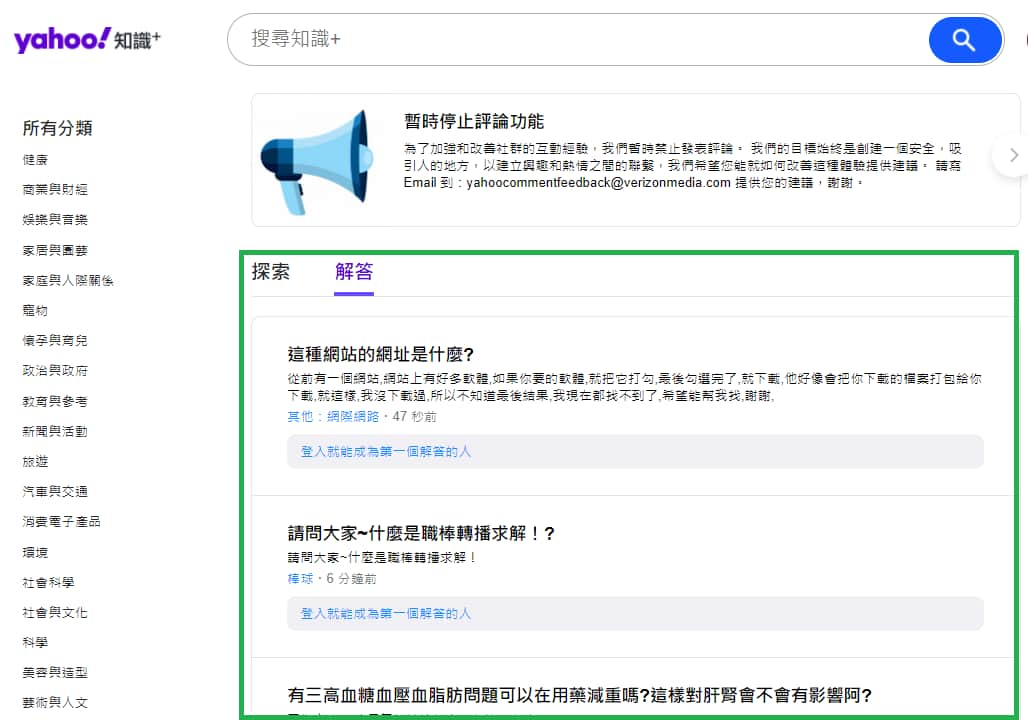
請求方法
先從"探索"開始找起,同上章節步驟,從開發人員工具知道請求的路徑、參數如下:
請求網址:https://tw.answers.yahoo.com/_reservice_/
請求方法:PUT
Request Payload:
| |
其中幾個參數代表意思:
categoryId:分類 ID。分類 ID 在各分類網頁的網址後方可找到,目前共有 24 個大分類,子分類也是採用同樣的方式。
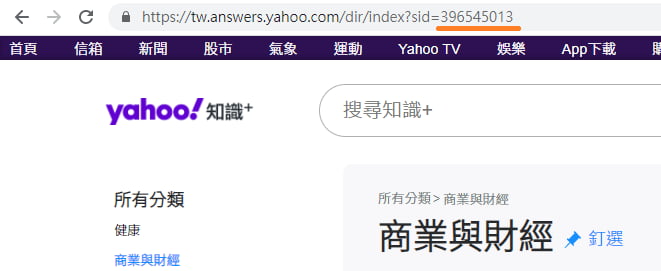
而如果給 0,則代表"所有分類",以下是各大分類所對應的 categoryId:
| 分類名稱 | 分類 ID |
|---|---|
| 所有分類 | 0 |
| 健康 | 396545018 |
| 商業與財經 | 396545013 |
| 娛樂與音樂 | 396545016 |
| 家居與園藝 | 396545394 |
| 家庭與人際關係 | 396545433 |
| 寵物 | 396545443 |
| 懷孕與育兒 | 396546046 |
| 政治與政府 | 396545444 |
| 教育與參考 | 396545015 |
| 新聞與活動 | 396545439 |
| 旅遊 | 396545469 |
| 汽車與交通 | 396545311 |
| 消費電子產品 | 396545014 |
| 環境 | 396545451 |
| 社會科學 | 396545301 |
| 社會與文化 | 396545454 |
| 科學 | 396545122 |
| 美容與造型 | 396545144 |
| 藝術與人文 | 396545012 |
| 遊戲與休閒活動 | 396545019 |
| 運動 | 396545213 |
| 電腦與網際網路 | 396545660 |
| 食品與飲料 | 396545367 |
| 餐廳與小吃 | 396545327 |
count:一次回傳"問題(文章)"數量。但實測發現有時得到的數量會較少。offset:偏移值。帶入前一頁回傳資料中offset的值。
而 "解答" 部分的問題列表(文章列表)其參數幾乎一樣,只要把 FETCH_DISCOVER_STREAMS_END 改成 FETCH_ANSWER_STREAMS_END、FETCH_DISCOVER_STREAMS_START 改成 FETCH_ANSWER_STREAMS_START 即可。
請求網址:https://tw.answers.yahoo.com/_reservice_/
請求方法:PUT
Request Payload:
| |
回傳資料
它以 JSON 格式回傳,error 會顯示此次請求是否發生錯誤,主要的資料都在 payload 裏頭。
canLoadMore:是否還有下一頁。offset:請求下一頁的偏移值。questions:問題列表(文章列表)。
而每一則問題又有幾個數值:
qid:問題 ID。也代表問題網址後方帶的參數,例如https://tw.answers.yahoo.com/question/index?qid=20210318093121AAnaQXT。title:問題標題。detail:問題內容。category:問題分類。createdTime:創建日期時間。answersCount:解答總數。thumbUpsCount:按讚總數。bestAnswerDetail:最佳解答內容。
範例:問題列表 JSON 資料 question_list_data.json
問題詳細資料
在問題列表(文章列表)點擊問題後會跳轉到問題詳細頁面,有完整的問題資訊與網友的解答。
請求方法
可以發現請求路徑和方法都是一樣的,它是透過 Request Payload 來判斷需要哪些資料(條件)。
請求網址:https://tw.answers.yahoo.com/_reservice_/
請求方法:PUT
Request Payload:
| |
其中 payload > qid 與 kvPayload > key 參數帶上問題 ID。
回傳資料
它以 JSON 格式回傳,error 會顯示此次請求是否發生錯誤,主要的資料都在 payload 裏頭,幾個比較重要的參數:
qid:問題 ID。也代表問題網址後方帶的參數,例如https://tw.answers.yahoo.com/question/index?qid=20210318093121AAnaQXT。lang:語言。category:問題分類。createdTime:創建日期時間。title:問題標題。content:問題內容。updatedDetails:問題更新詳情。attachedImageUrl:附加圖片網址。bestAnswer:最佳解答。answerCount:解答總數。saveCount:被收藏總數。isAnonymous:是否匿名。
範例:問題 JSON 資料 question_data.json
解答列表
位於每篇問題(文章)底下會有各網友回覆的解答(留言)。
請求方法
一樣只有 Request Payload 有差異,
請求網址:https://tw.answers.yahoo.com/_reservice_/
請求方法:PUT
Request Payload:
| |
其中 payload > qid 與 kvPayload > key 參數帶上問題 ID。count 代表一次回傳"解答(留言)"數量,start 代表起始值,例如這次解答取到 10 則,下一次要從第 11 則開始抓,那 start 就要帶 11。sortType 代表解答排序依據(RATING:評分、NEWEST:最新、OLDEST:最舊)。

回傳資料
它以 JSON 格式回傳,error 會顯示此次請求是否發生錯誤,主要的資料都在 payload 裏頭,幾個比較重要的參數:
qid:問題 ID。lang:語言。answerCount:解答總數。start:本次解答起始值。count:本次解答數量。sortType:解答排序依據(RATING:評分、NEWEST:最新、OLDEST:最舊)。answers:解答列表(留言列表)。
而每一則解答又有幾個數值:
qid:問題 ID。id:解答 ID。text:解答內容。attachedImageUrl:附加圖片網址。reference:解答參考來源。answerer:解答網友。answerer>kid:網友 ID。answerer>nickname:網友暱稱。answerer>imageUrl:網友圖片網址。answerer>level:網友等級。isBestAnswer:是否為最佳解答。thumbsDown:倒讚數。thumbsUp:按讚數。isAnonymous:是否匿名。commentCount:此解答底下回覆數量(目前此功能好像被移除了)。createdTime:創建日期時間。
* 抓取解答(留言)時要注意,如果此問題有"最佳解答",則此解答並不會出現在"解答列表"的回應裡,而是會在"問題詳細資料"回應資料裡的 bestAnswer 參數中,因此要注意不要遺漏掉了。
範例:解答列表 JSON 資料 answer_list_data.json
範例程式碼
附上範例程式碼:
yahoo_answers_spider.py
(對超連結右鍵 > 另存連結為…)
延伸練習
- 試著爬取一篇問題,並將問題以及各解答挑出想要的幾個欄位,並儲存成適合的檔案(TXT文字檔、JSON)。
結語
一開始我在測試抓取"Yahoo奇摩知識+"時,不知道為何 Header 都給一樣了,還是一直無法成功請求到資料。後來改使用 Postman 這項工具測試,才發覺 content-type 要帶 'application/json',也學到了一個😙。
如果你對於 Python、爬蟲、網頁感興趣的話,我後續還會繼續寫相關的文章,歡迎來追蹤 FB 粉專『 IT空間 』~
人生就像天空一樣,有季節更迭,時刻在變;
它雖然不會一直晴空萬里,但也不會總是大雪紛飛。—— 《鬼滅之刃》
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~