(This article was translated by AI and then reviewed by a human.)
Preface
Two days ago (12/11), Google announced Gemini 2.0, saying it is a new model specially created for the agentic era✨, and it was the first to launch the “Gemini 2.0 Flash (Experimental)” model.
To showcase the new capabilities of Gemini 2.0, Google has an interface in Google AI Studio for everyone to try out.
In addition to the powerful functions of real-time video + voice interaction similar to the previous demo's Project Astra, the new model includes spatial image understanding, video analysis, and map integration, among other exciting features.
Let's dive in for a quick experience!
By the way,
* Just a day later, OpenAI rolled out its advanced voice mode with similar real-time video features (including screen sharing). The competition is heating up! XD
* Google also introduced a Deep Research tool
, which can search the web on your behalf (and may collect more than a 100 sources), analyze it, and compile it into research reports.
Gemini 2.0
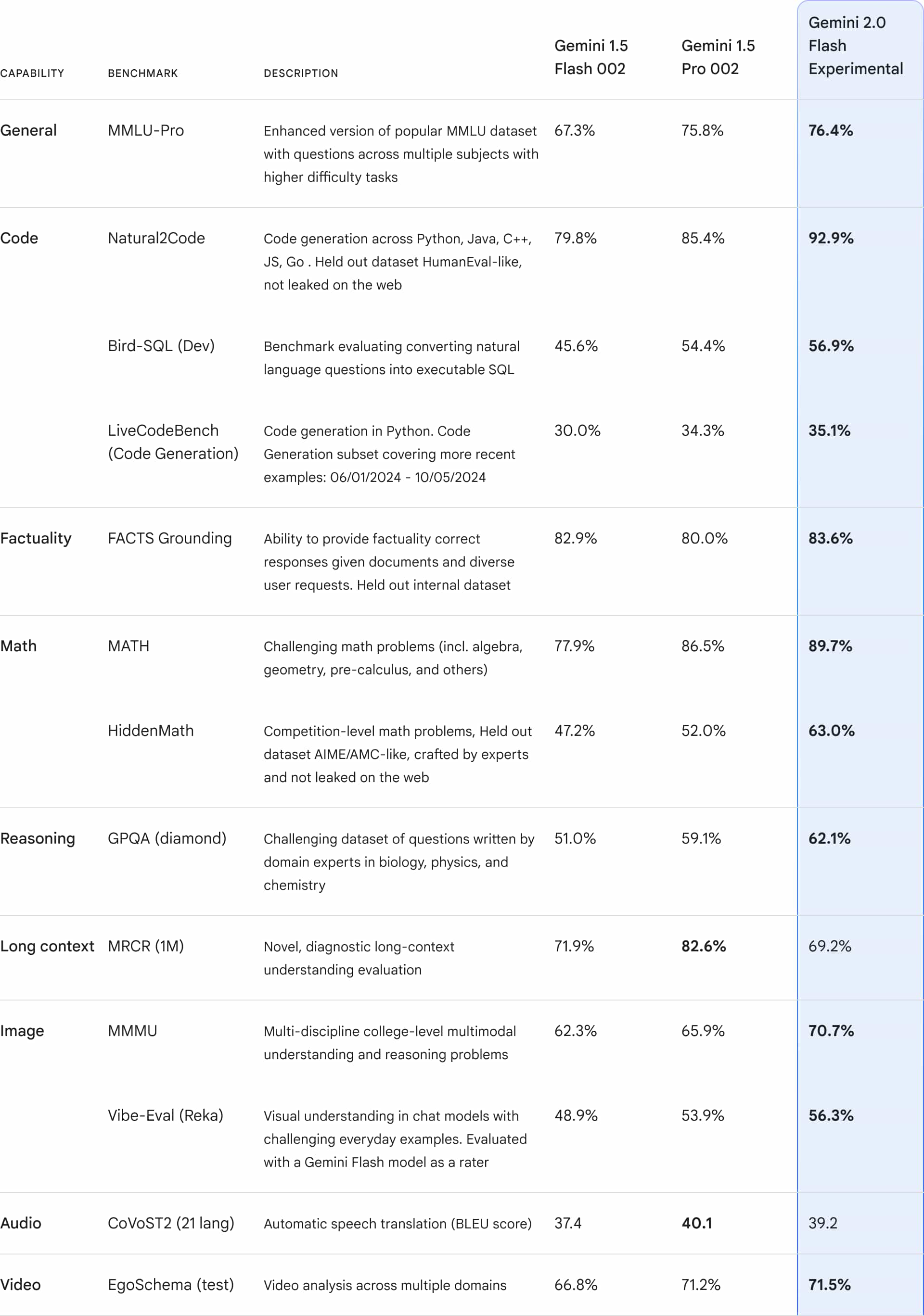
Gemini 2.0 Flash has outperformed 1.5 Pro in key benchmark tests, with speeds twice as fast as 1.5 Pro. It supports inputs like text, images, videos, and audio, and now even outputs native images and audio!
Gemini 2.0 Flash is now available on Google AI Studio and Vertex AI. Global Gemini users can also access 2.0 Flash via desktop or mobile web platforms, with the feature set to launch on the Gemini mobile app soon ~
- Google Official Introduction to Gemini 2.0
- Google Official Overview of New Features in Gemini 2.0 Flash
Google AI Studio
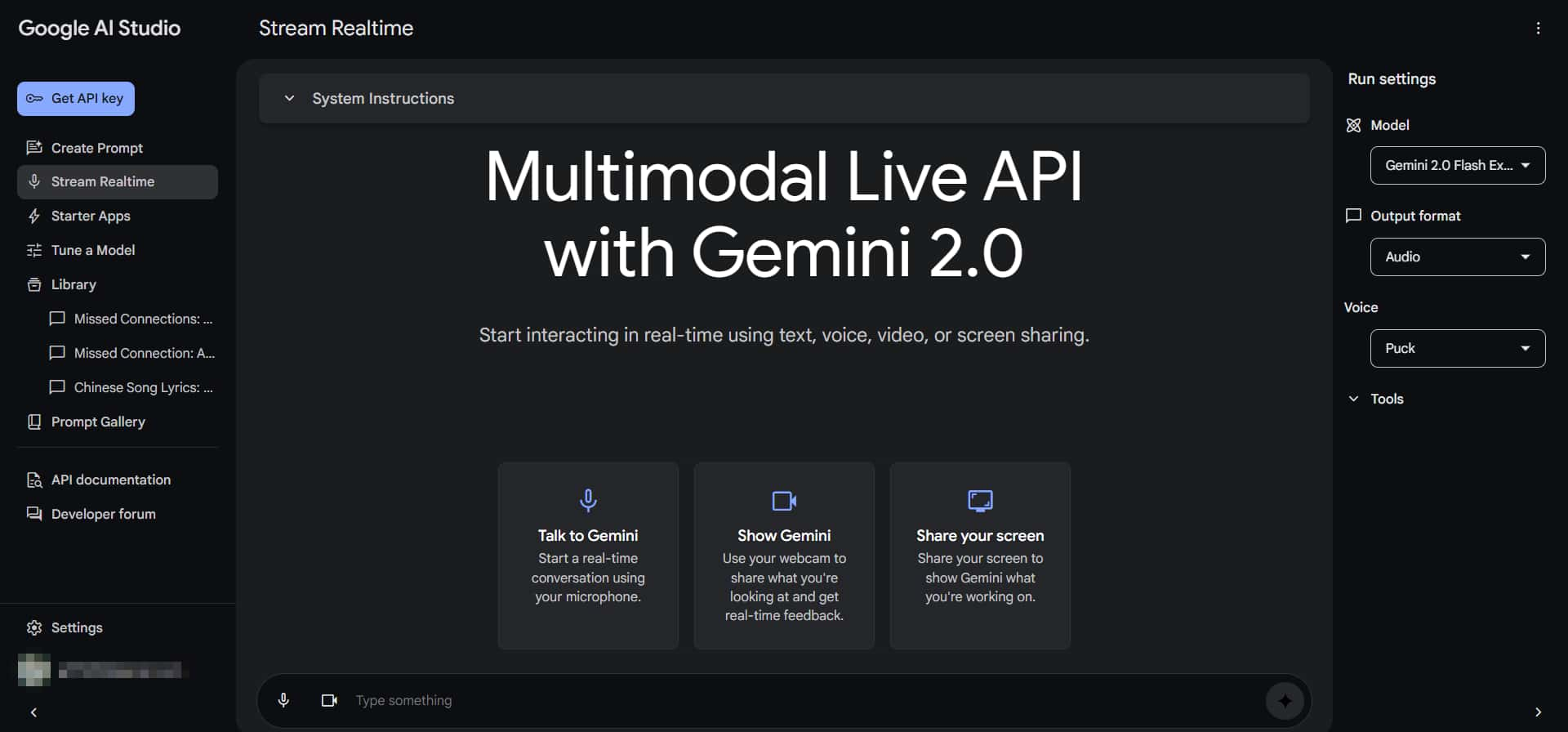
Stream Realtime
Stream Realtime | Google AI Studio
Here, you can use a "camera + microphone" to interact with Gemini in real-time, similar to the Project Astra demo shown earlier (just not as advanced yet 😅).
For example, you can walk around with your phone and ask, "What is this?" or "What is that?" You can also share your screen to ask for help, like how to operate something. The range of applications is very broad.
Since Gemini 2.0 is natively multimodal, it supports both voice input and output. It can adapt its tone and speed based on the context, and you can even interrupt it mid-response.
It's hard to fully show this through text, so feel free to try it out yourself!
* Unfortunately, it currently doesn't support Chinese voice output. However, you can still ask it questions in Chinese and have it reply in English (or set it to reply in text, so it can respond in Chinese).
Starter Apps
Starter Apps | Google AI Studio
On this page, Google has created three apps to let you experience Gemini 2.0’s capabilities in understanding images, analyzing videos, and integrating maps.
* If you are a program developer and want to manually write code for interaction, you can refer to the official GitHub project example
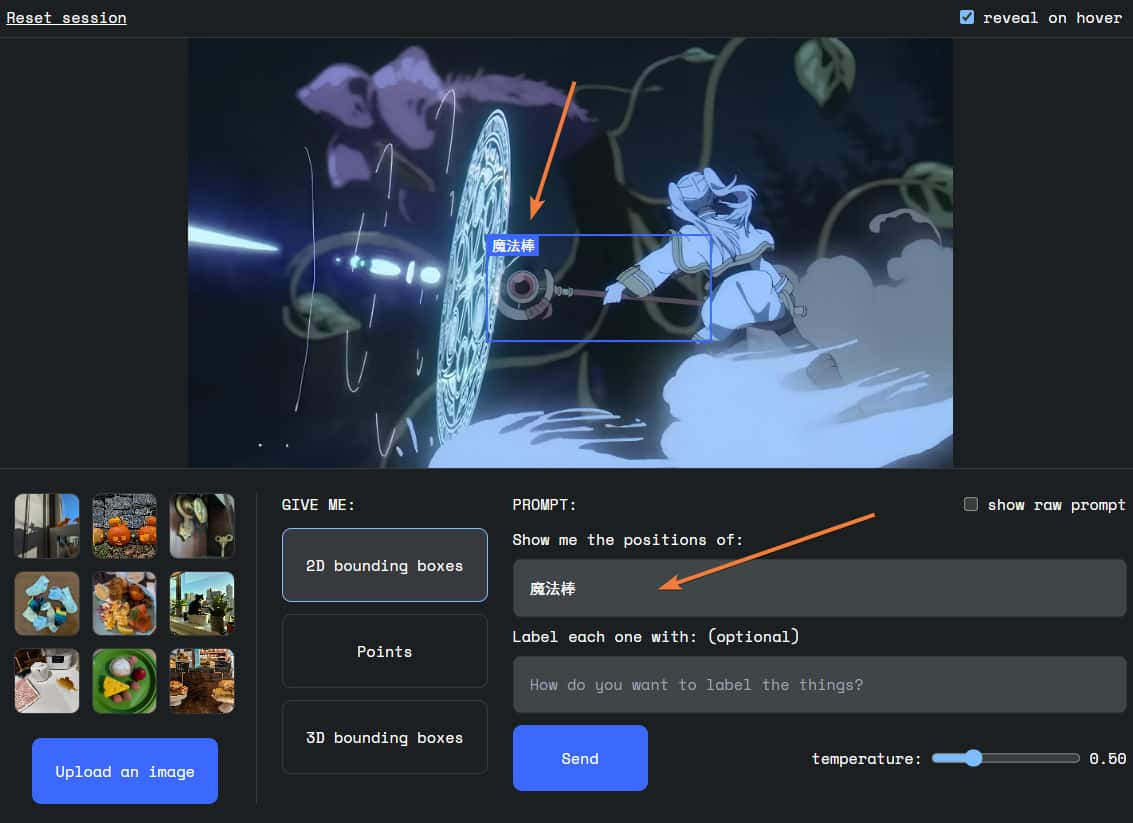
Spatial Understanding
Spatial Understanding can identify objects in an image. For example, you can ask it to find a magic wand in a picture:
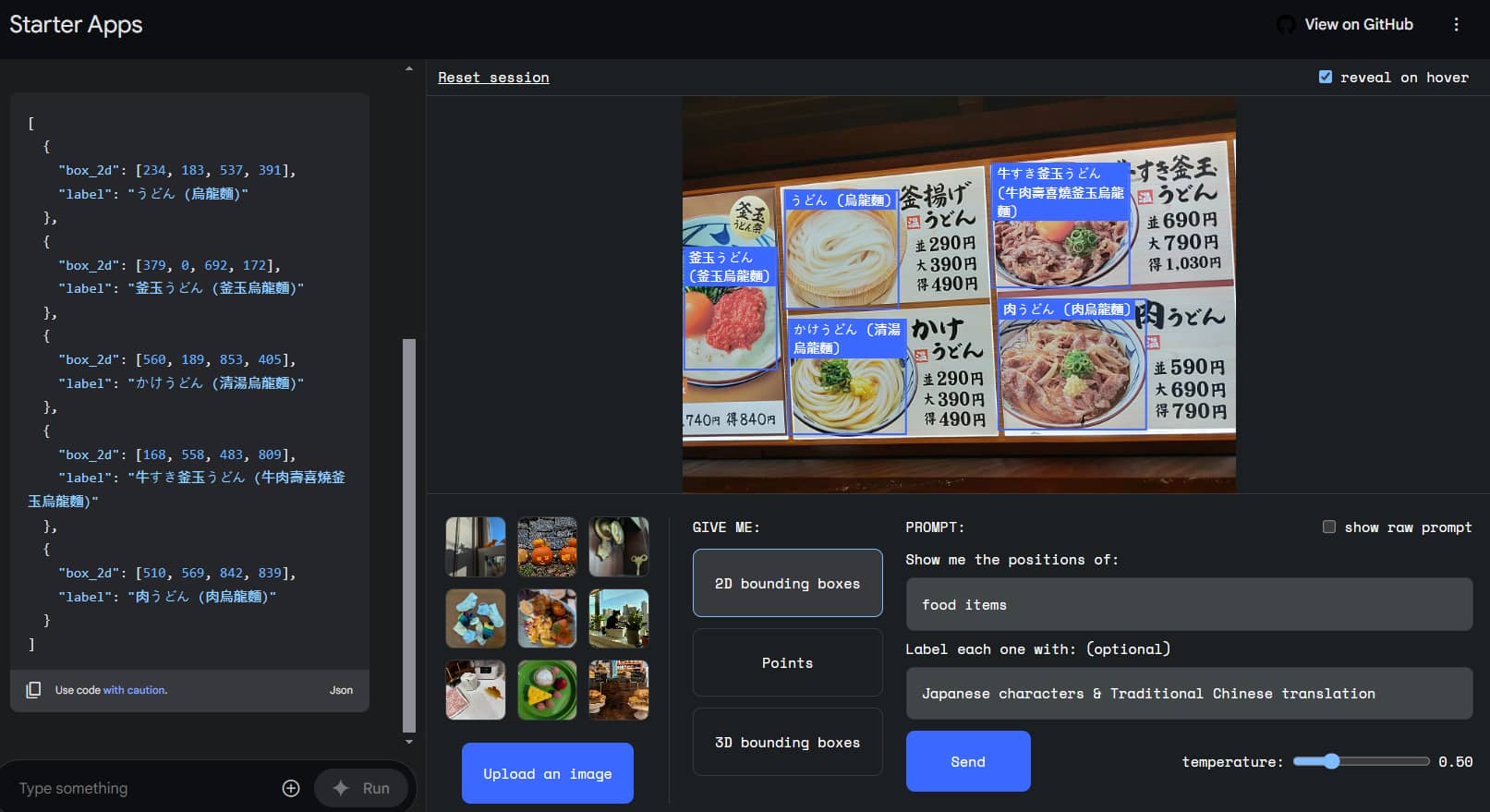
It can also help when you can't understand a Japanese menu by identifying and translating the items into Chinese:
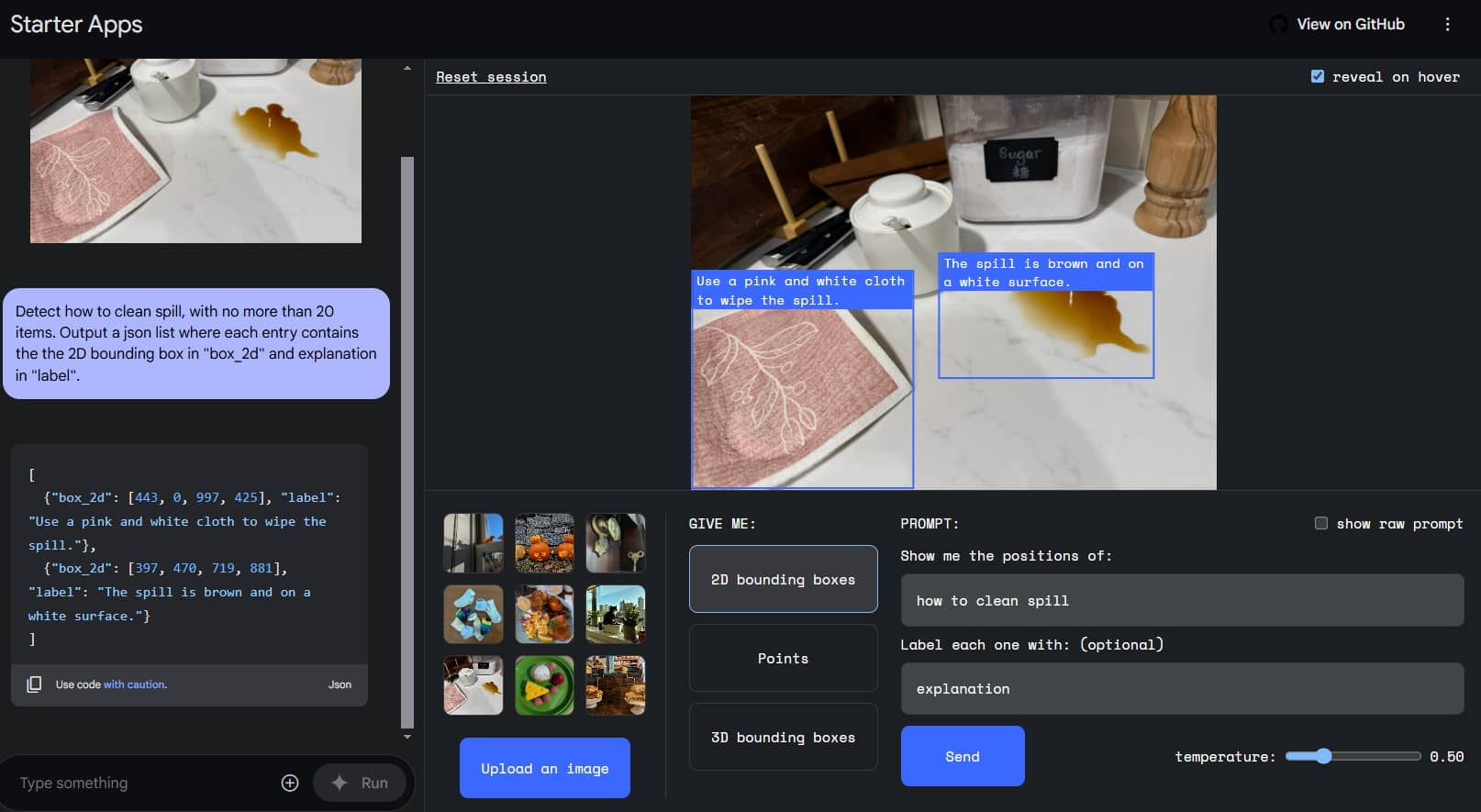
Or find stains and teach me how to clean them:
Check out the official demo video: https://www.youtube.com/watch?v=-XmoDzDMqj4
* The official notes mention: “Points and 3d bounding boxes are preliminary model capabilities. Use 2D bounding boxes for higher accuracy.”
Video Analyzer
Video Analyzer can analyze video scenes, provide summaries, extract text, search for objects, and more.
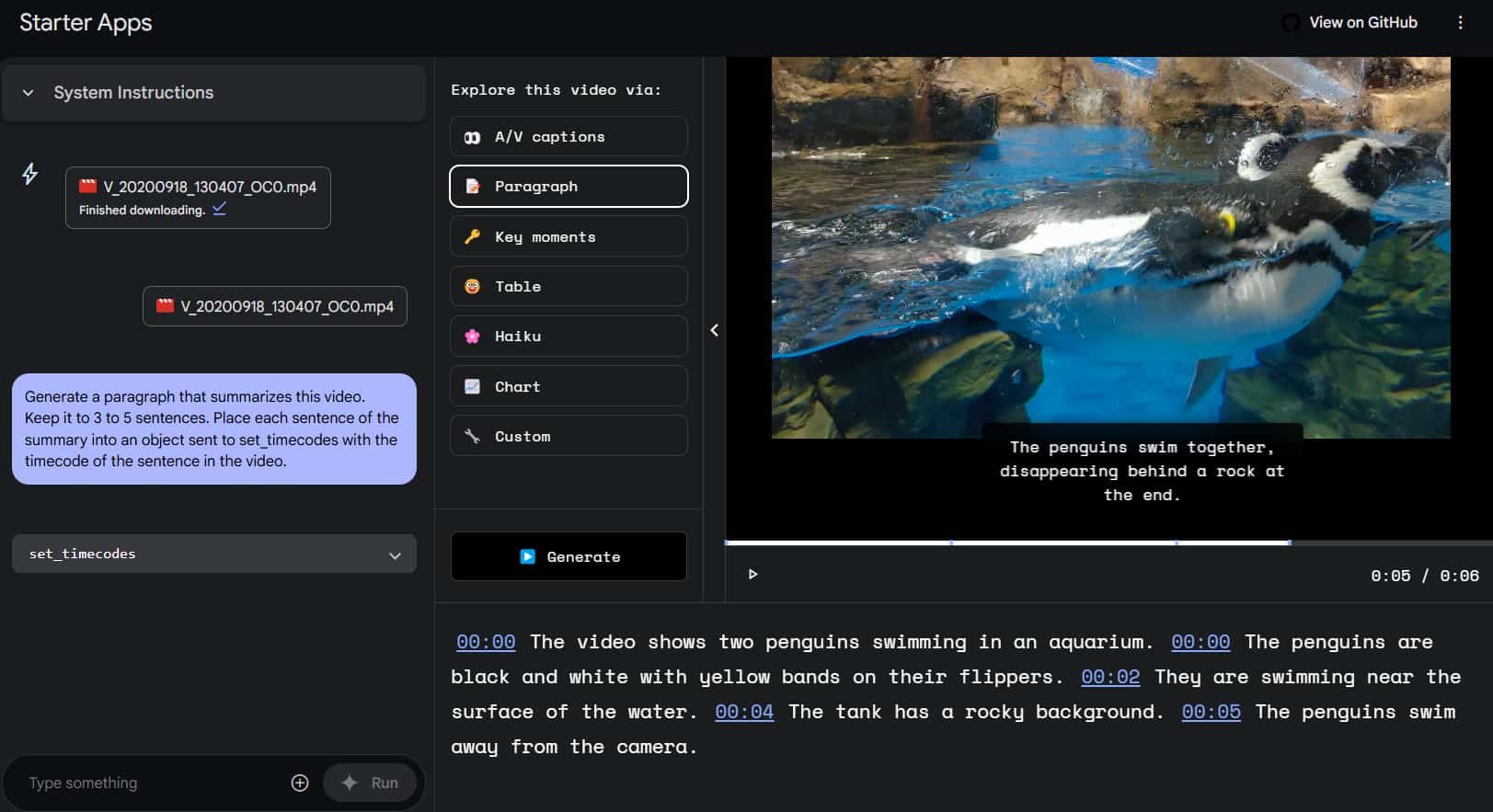
Map Explorer
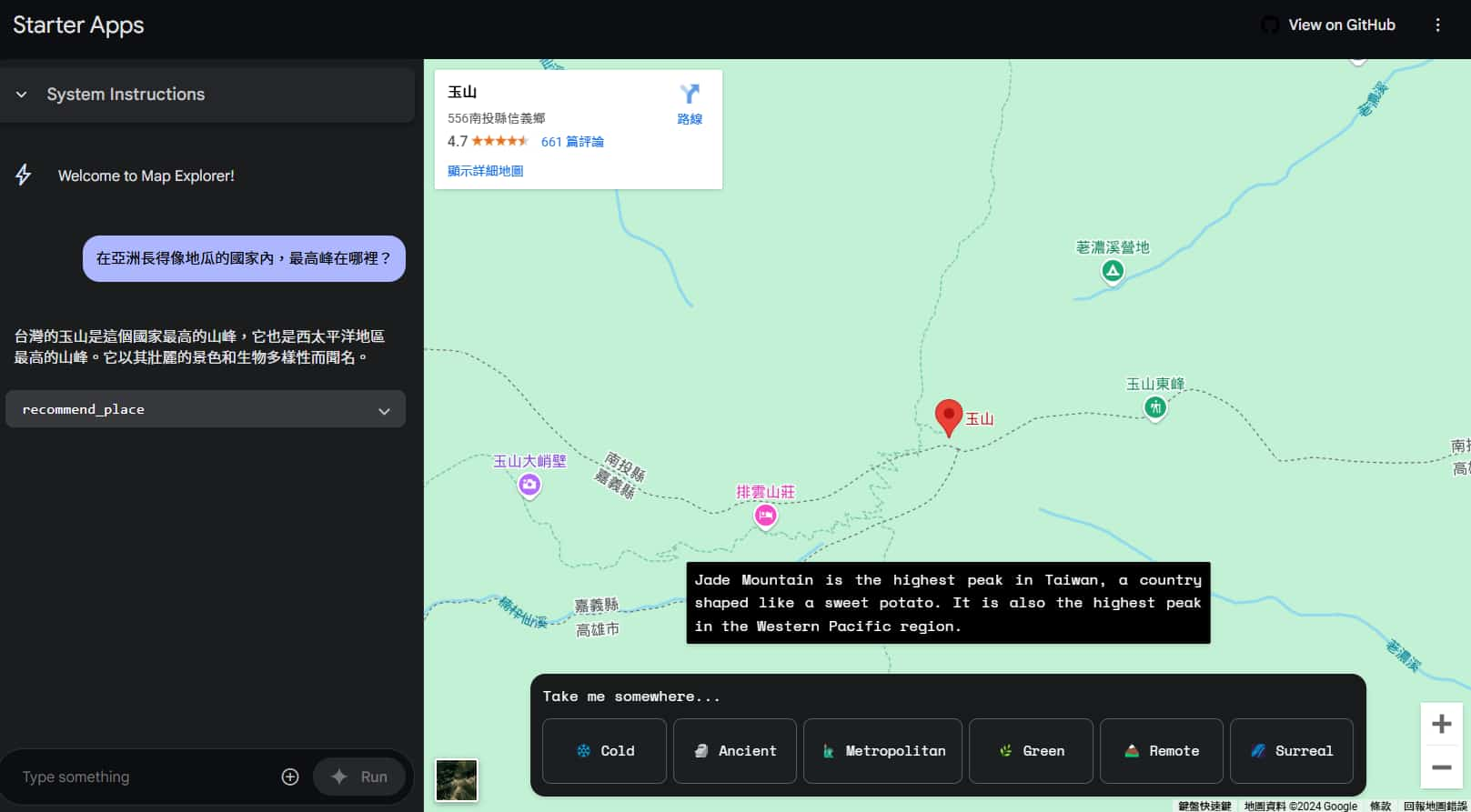
Ask Map Explorer questions about countries, landmarks, or geography, and it will pinpoint the answers on Google Maps, making it easy to explore the world ~
Other tests
Recognizing Song Lyrics
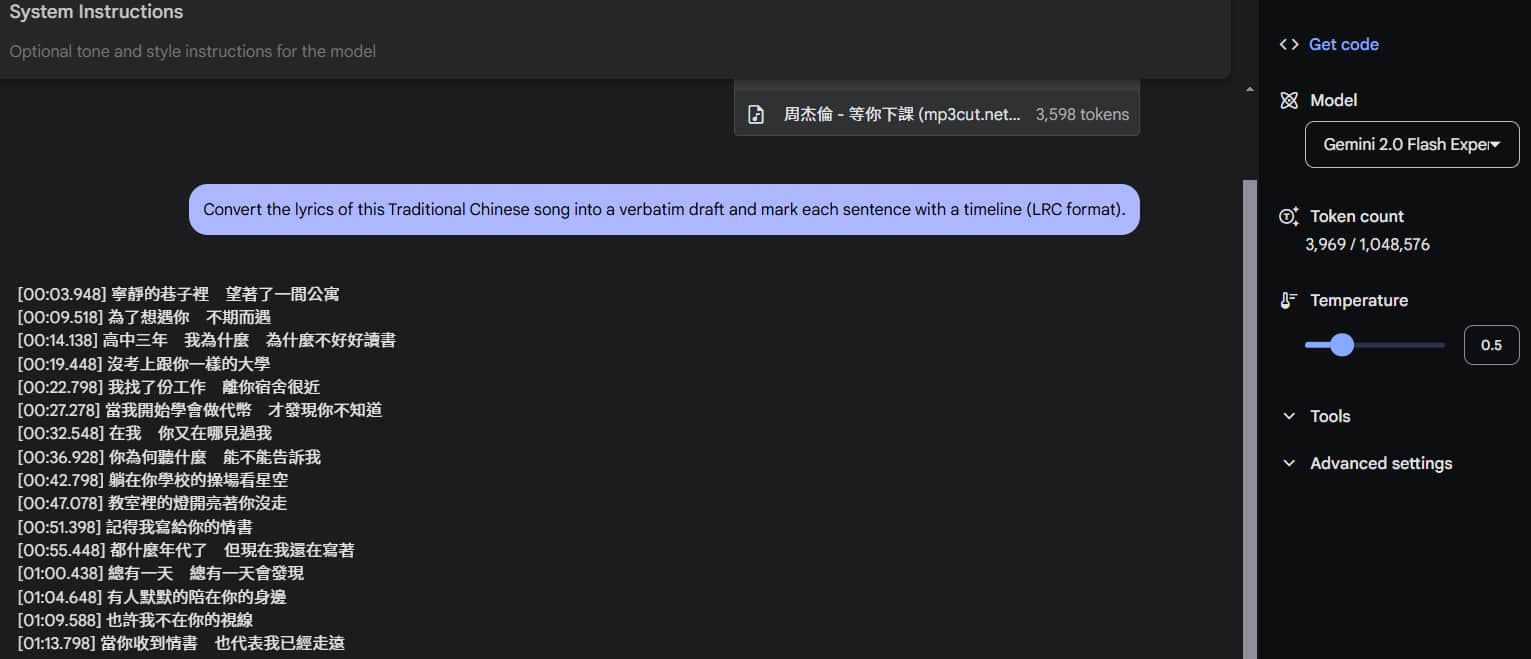
Try out the Gemini 2.0 Flash to test its ability to read audio files and recognize song lyrics. Simply provide it with an audio file of a song, and it will identify and organize the lyrics into an LRC format.
I tested it with Jay Chou's “Waiting for You” (等你下課) to see how it handles slightly unclear pronunciation. Here's how it performed:
(Temperature set to 0.5)
Let's also compare with the Gemini 1.5 Pro model:
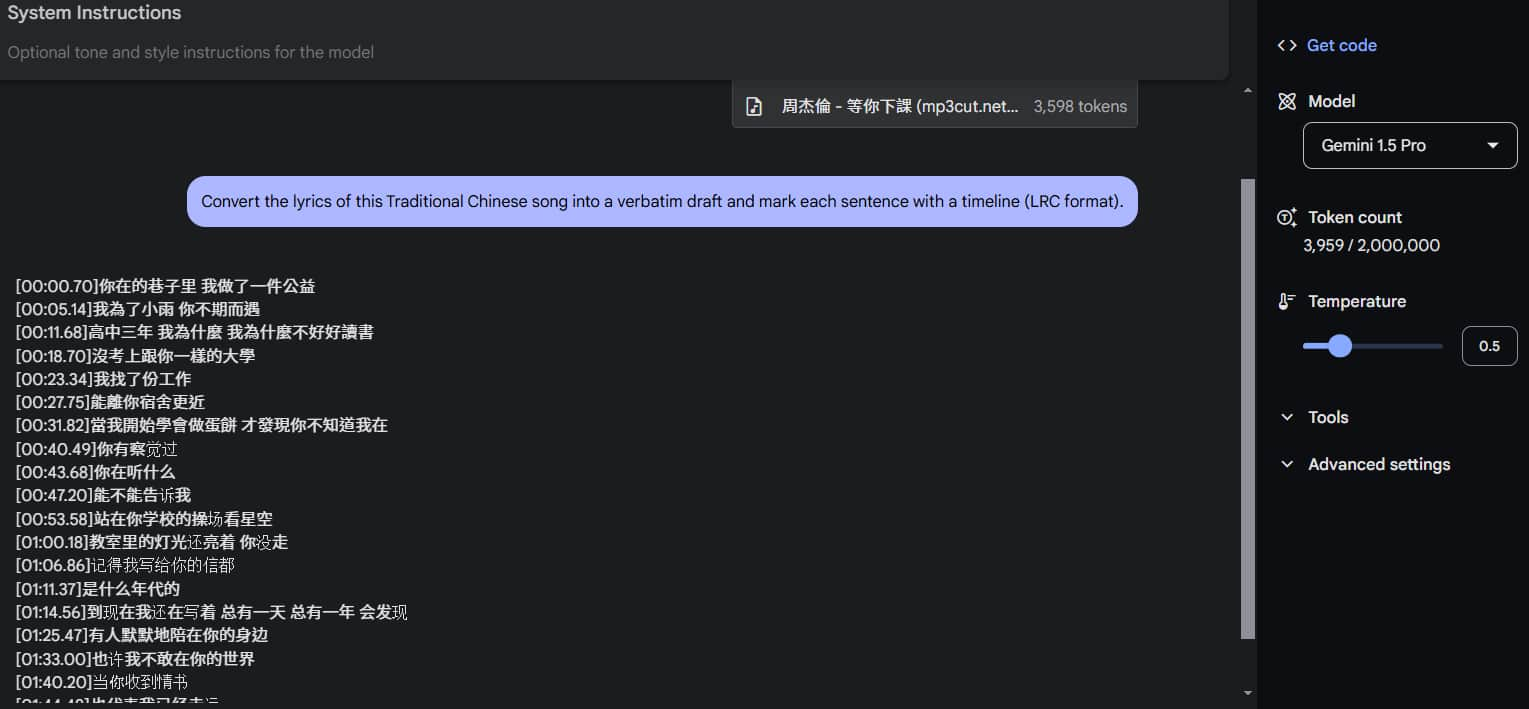
When compared to the original lyrics, although both have small recognition errors, it's clear that 2.0 Flash Experimental is better than 1.5 Pro. Additionally, 1.5 Pro mistakenly switched to Simplified Chinese toward the end.
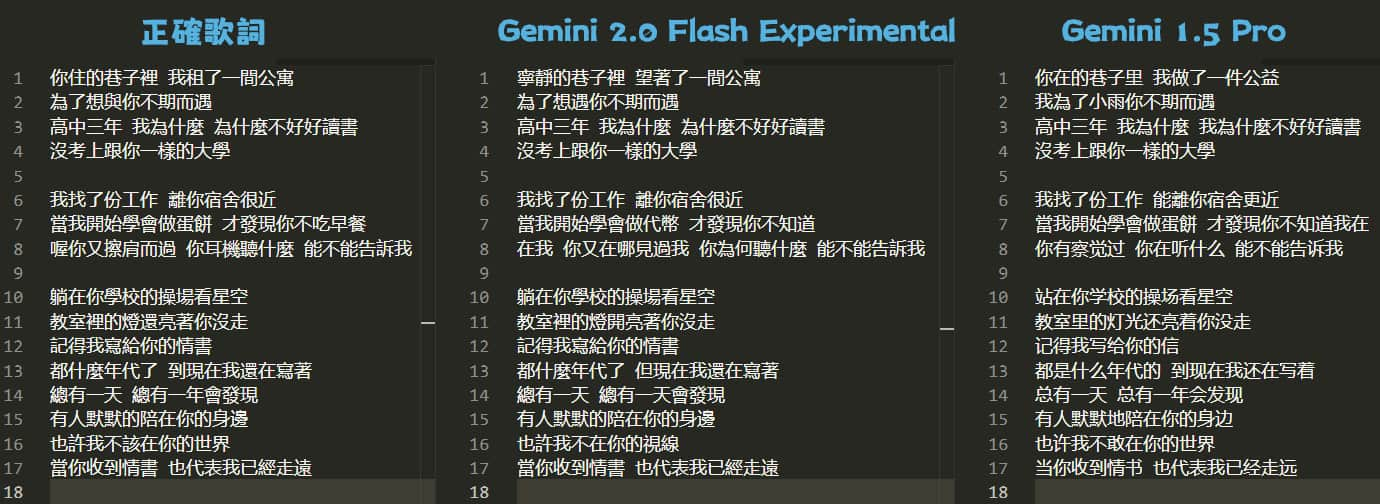
Although comparing Flash and Pro models isn't entirely fair, it does show how much Gemini 2.0 has improved.
However, I don't know why the output lyrics were not complete, stopping about halfway, even though it shouldn't have exceeded the Output length limit of 8192 tokens.
Native tool use
Gemini 2.0 natively supports tools like running code or performing Google searches, allowing for real-time interaction and feedback.
Using Google search can help ensure the accuracy of the answers. It allows the system to gather information from multiple sources and combine them to make the responses more comprehensive.
(The official documentation also mentions that this approach can “increase traffic to the source websites” 😆)
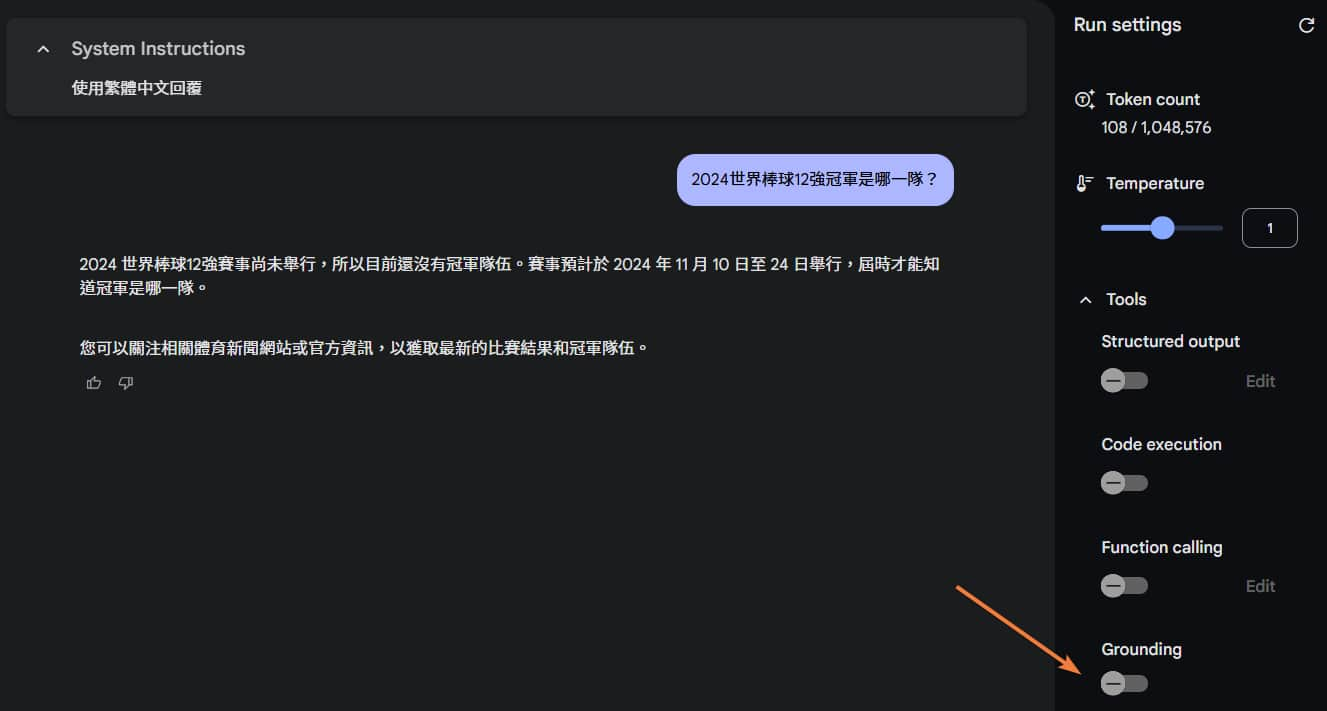
For example, if I directly ask it, “Which team won the 2024 World Baseball Classic?” it might reply that the game hasn't started or that it doesn't know:
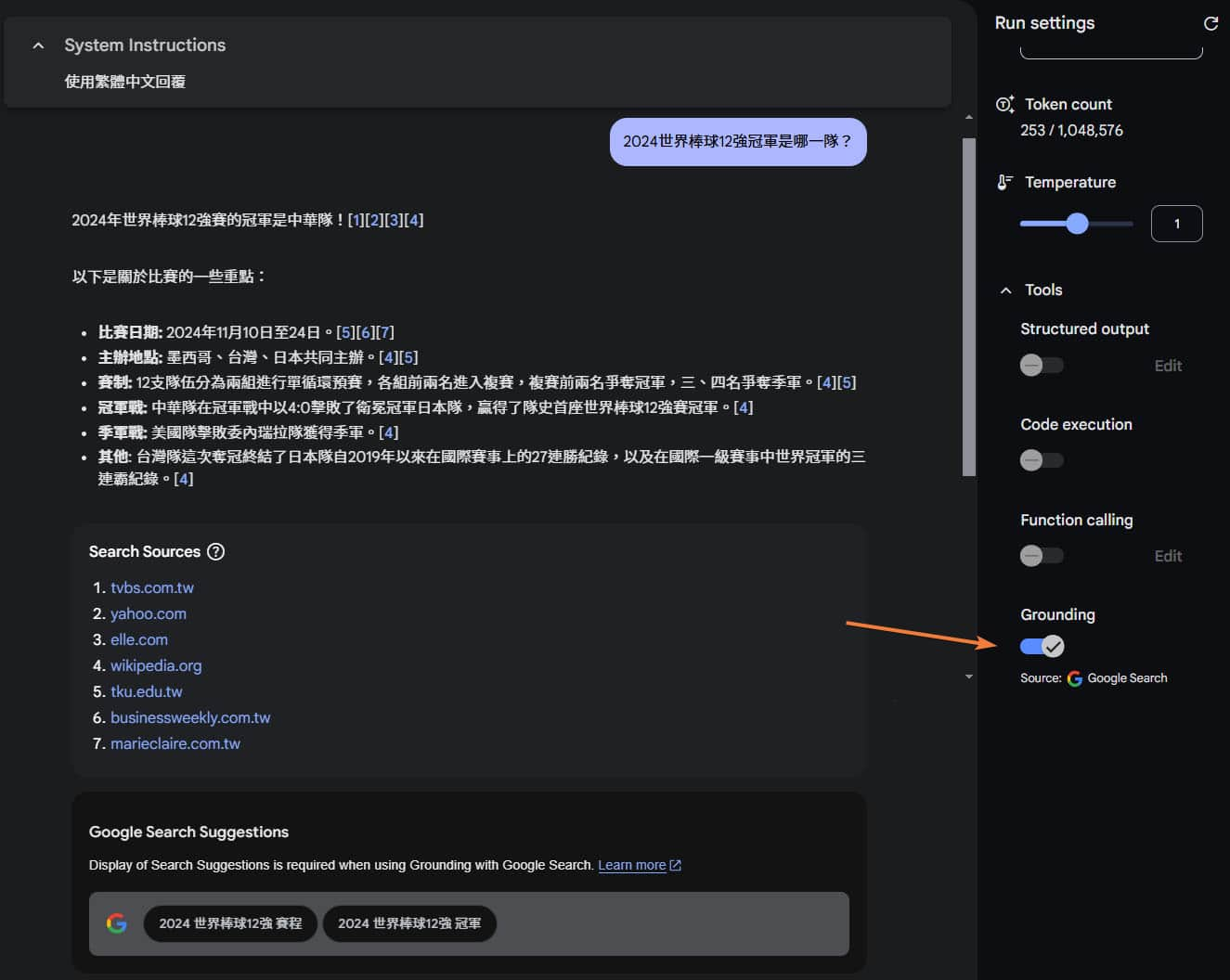
However, when the Google Search (Grounding) feature is enabled, it will search the web for information, providing accurate and real-time answers:
* You can refer to the official documentation for instructions on how to use the program. There's no need to integrate a separate search API: Grounding with Google Search
The official demonstration shows how to draw charts with code. You can watch this video:
Native image output
It also has powerful image generation and editing capabilities. It can precisely modify specific areas of an image without affecting other parts. The commands are more conversational and user-friendly. It can also merge two images or infer possible scenes from existing ones.
This feature seems impressive and could make AI-powered image editing more practical!
This part doesn't seem to be available to the public yet, but you can get a glimpse through the official demo videos:
Official Sample Code
For developers, Google also provides some example code for various features as a starting point for reference:
https://github.com/google-gemini/cookbook/tree/main/gemini-2
Conclusion
Since the model training data is primarily in English, if your results on Gemini aren't satisfactory, it's recommended to use English for your commands.
All the applications above are based on the Gemini 2.0 Flash model. Once the Gemini 2.0 Pro model is released, the performance will certainly be even better and more powerful~
Below are links to other Gemini 2.0 reference articles. If you’re interested, you can click to read further.
If you're interested in Generative AI, make sure to follow the “ IT Space ” Facebook page to stay updated on the latest posts! 🔔
References:
Introduction to Gemini 2.0
Overview of New Features in Gemini 2.0 Flash
Google 推出新一代 Gemini 2.0!可直接使用搜尋、各種模態無縫融合
Google:AI 代理時代降臨!一口氣發表自動瀏覽網站、網購、打電動的 AI 助理
Don't be afraid to think different and challenge the status.
—— Jensen Huang (president and chief executive officer (CEO) of Nvidia)
🔻 如果覺得喜歡,歡迎在下方獎勵我 5 個讚~